在爬取一個網站時
遇到這個亂碼
網頁原始碼的部分
<span style="display:none">亂碼</span>要爬取的部分<br />
不管怎麼改標籤
都沒辦法避開亂碼的部分
有什麼方法嗎?
import requests
from bs4 import BeautifulSoup
def ourl(url):
res=requests.get(url)
res.encoding='big5'
soup=BeautifulSoup(res.text,'html.parser')
return soup
url='http://ds-hk.net/thread-93278-1-49.html'
soup=ourl(url)
print(soup.select('.t_msgfont')[0])
已邀請的邦友 {{ invite_list.length }}/5
其實要過濾掉不要的內容
就真的去歷遍所有節點
判斷節點屬性後再決定是否輸出就好
要學爬蟲,最好先學 DOM 相關的內容,理解整份文件是一種樹狀結構
遇到比較複雜的狀況才知道怎麼處理
import requests
from bs4 import BeautifulSoup
from bs4.element import Tag,NavigableString
#這個函式會歷遍 node 節點的子元素
#過濾後輸出內容
def getArticleContent(node):
outputHtml='';
for child in node.children:
#如果是 elementNode
if(isinstance(child, Tag)):
#判斷 style 屬性是否有 display:none 或 font-size:0px
#有的話跳過這個 node
st=child.attrs.get('style', '')
if('display:none' in st or 'font-size:0px' in st):
continue
#通過檢查的 node 則用遞迴呼叫繼續往下
outputHtml=outputHtml+getArticleContent(child)
#如果是 textNode 就直接輸出文字內容
elif(isinstance(child, NavigableString)):
outputHtml=outputHtml+child
return outputHtml
#測試的 html
testHtml='''<div id='test'><span style="display:none">不要的</span><font
style="font-size:0px;color:#FAFFEF">這也不要</font><br />
【標題】<font
style="font-size:0px;color:#FAFFEF">我不要看到這個</font><br />
內文內文內文內文 <font
style="font-size:0px;color:#FAFFEF">你看不到我</font><br /></div>'''
soup = BeautifulSoup(testHtml, 'html.parser');
div=soup.select('#test')[0];
print(getArticleContent(div))
唔
要理解一下
有沒看過的函數
我之前則是想出取代的方法
發問是想說有沒有直接爬取要的部分就好
看您的方式還是得要用過濾的方法
理解了
感謝
i=soup.select('.t_msgfont')[0]
a=i.text
for j in i.select('span'):
a=a.replace(j.text,'',1)
for f in i.select('font'):
a=a.replace(f.text,'',1)
這是我的取代代碼
還蠻難看的...
用任何一個 Library,看一下他們原始的文件是個好習慣,一般網路上教學只是入門教材。
參考: 官方的文件
child.get('style', '')也和child.attrs.get('style', '')同樣結果
不懂attrs是什麼意思
都可以,參考:Attributes
喔
以字典模式來看,然後用get取出
了解
HI~!
關於你的問題,我覺得那是 網頁作者自已加上去的特殊符號。
圖片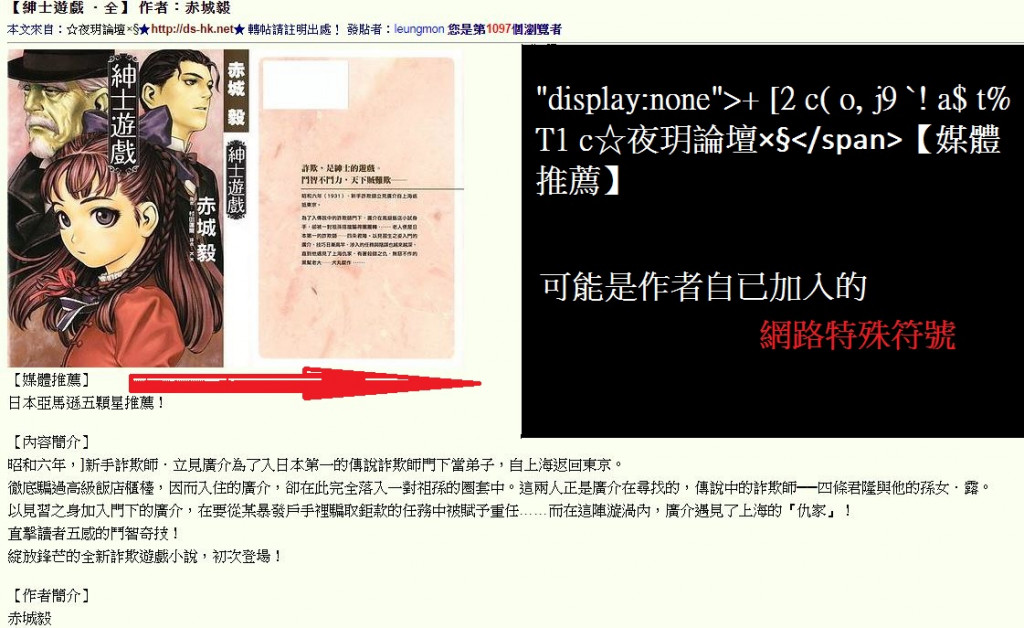
我把程式改成這樣就可以抓(grab )到網頁內容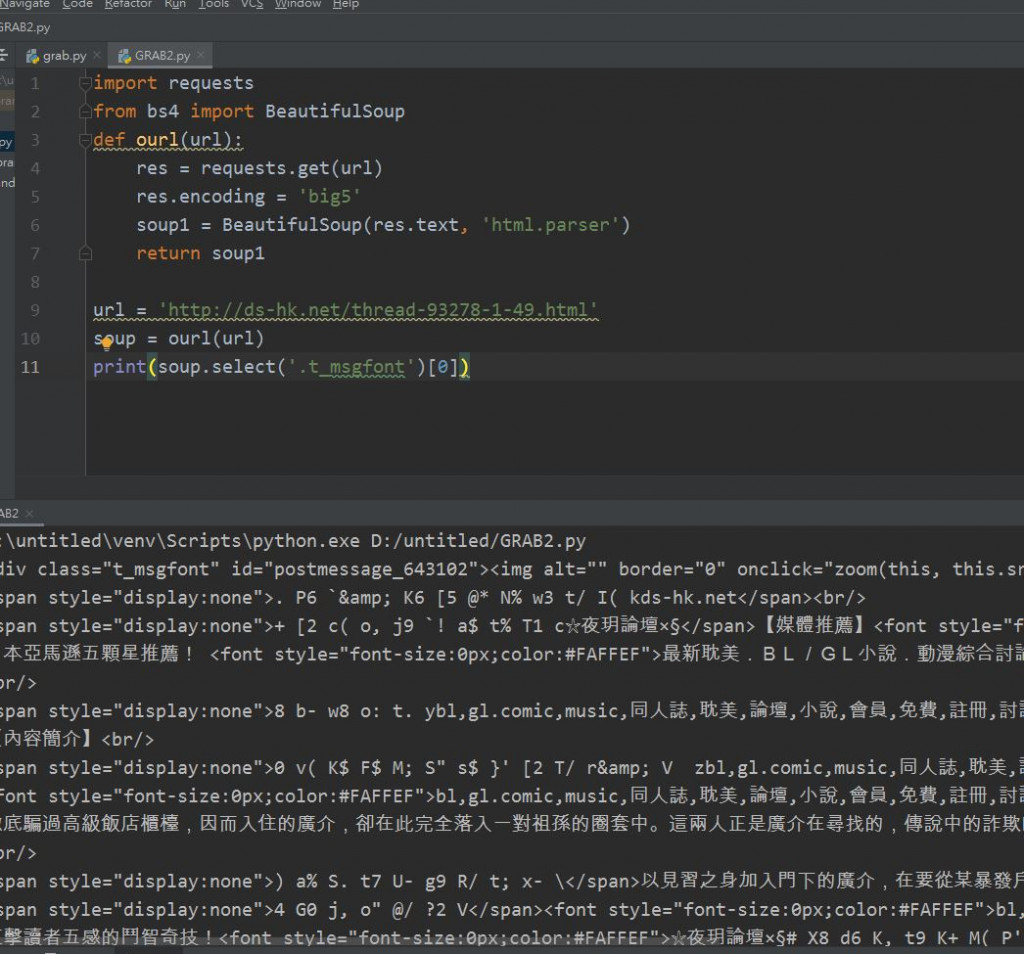
(一)以下是我的程式碼
import requests
from bs4 import BeautifulSoup
def ourl(url):
res = requests.get(url)
res.encoding = 'big5'
soup1 = BeautifulSoup(res.text, 'html.parser')
return soup1
url = 'http://ds-hk.net/thread-93278-1-49.html'
soup = ourl(url)
print(soup.select('.t_msgfont')[0])
(二)我在試成功上面的程式碼前,有先寫一個範例。
因為我之前沒有用過BeautifulSoup
from bs4 import BeautifulSoup
def ourl(url):
res = requests.get(url)
res.encoding = 'utf-8'
soup = BeautifulSoup(res.text, 'html.parser')
return soup
url = 'http://34.94.68.139/'
soup2 = ourl(url)
a_tags = soup2.select('html body h1')
for t in a_tags:
print(t.text)
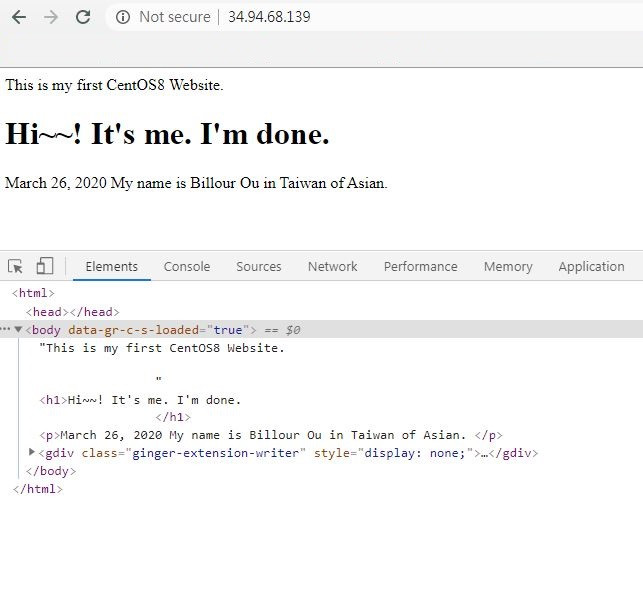
(三)出現大量錯誤。
我在試寫這個問題時,python3 的環境,有很多問題,
花了不少心力處理這一塊。
我應該寫一個「python3 常見錯誤」
或是 「python 環境設定」
自已寫的詳細安裝錯誤狀況
http://www.okna.tw/zh-hant-tw/zp0001/
關於我
