除了用 robot.txt 阻擋以後的搜尋之外, 舊內容可以:
申請 Google Search Console, 進去把你的網站刪掉..
Google Search Console 初學者指南,如何使用及安裝
如以下幾招
1.設規則 robot.txt 有人有說明過了,我就不在重覆
2.設ip阻檔或是規則阻擋。可以用rw規則來處理,一般搜尋引擎都會帶有特定標頭。
3.關站。(好~~~我是開玩笑的)
我大多是用第二招。因為第一招對某些搜尋引擎沒用。
還有一招~
自創DNS自己連進網站~
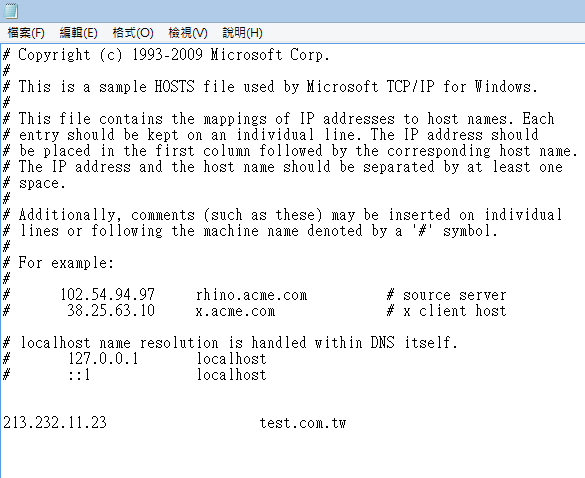
例如IIS設定一組 test.com.tw
然後在本機的hosts文件輸入test.com.tw xxx.xxx.xxx.xxx(網站位置IP)
使用「noindex」封鎖搜尋索引服務 (不使用Robot.txt)
https://support.google.com/webmasters/answer/93710?hl=zh-Hant
<meta name="robots" content="noindex">
<meta name="googlebot" content="noindex">
走cloudflare proxied 用cloudflare firewall 檔known-bots
想要防止網頁被Google編入索引,你可以嘗試以下幾種方式:
1. 創建並提交robots.txt文件
通過創建robots.txt文件,我們可以指定谷歌爬取工具甚麼頁面可以被索引,甚麼頁面禁止索引。你可以使用任何支持UTF-8編碼的文字編輯器創建robots.txt文件。要注意的是,robots.txt必須存放在網站的根目錄下。
robot.txt寫法規則:
-允許所有爬取工具索引所有內容:
User-agent: *
Allow: /
禁止所有爬取工具索引任何內容:
User-agent: *
Disallow: /
僅禁止谷歌索引任何內容:
User-agent: Googlebot
Disallow: /
User-agent: *
Allow: /
2. 設置noindex
你也可以在所有頁面實施noindex,禁止搜索引擎將該網頁編入索引。
3. Google Search Console — 移除工具
如果你的網站安裝了Google Search Console站長工具,你可以使用移除工具將某個網址快速從谷歌搜索中移除。 想了解更多關於安裝Google Search Console和用途,可參考Google 站長工具教學。
