各位好
最近在學Python,遇到了兩個問題撞牆不知道怎麼解,還請各位給些指點,謝謝。
Q1:
有個df
memberid order_date
a 2020-08-05
a 2020-08-12
a 2020-08-17
b 2020-08-16
b 2020-08-19
c 2020-05-01
c 2020-05-03
c 2020-05-04
c 2020-05-07
要怎麼樣才能找到類似group by memberid 但顯示的是倒數第二筆資料呢
(想像的樣子)
a 2020-08-12
b 2020-08-16
c 2020-05-04
Q2:因為是學SQL慢慢有興趣開始學python 轉換過來一直覺得sql的case when條件式很好用 轉換到python之後 都用apply(lambda x:...) 但最近想轉換str都一直失敗 想請問有沒有別的方法 謝謝
舉例來說
memberid campaign
a bthd
a bthd_sell
a urgent_s
b urgent_s
b urgent_s
c bthd_sell
c bthd_sell
c christmas
c christmas
想依照條件 campaign == 'bthd_sell', campaign == 'urgent_s' 新開一欄命名為1,2
memberid campaign cam_label
a bthd
a bthd_sell 1
a urgent_s 2
b urgent_s 2
b urgent_s 2
c bthd_sell 1
c bthd_sell 1
c christmas
c christmas
*考慮過用map(dict) 但我目前處理的表該變數有太多種類 只想特定幾個處理一下 其他就null 想問有沒有更方便的解法
小弟有努力在搜索相關資源 嘗試不當伸手牌 但因為入門不久 對相關terms的概念也不深 找不太到相關回答 如果是已經存在的問題 還請鞭小力一點 謝謝各位幫忙了 祝大家周末愉快!
已邀請的邦友 {{ invite_list.length }}/5
pandas 搭配 numpy
我語法也是 google 來的,給你關鍵字參考
import pandas as pd
import numpy as np
df = pd.DataFrame(
np.array([
["a", "2020-08-05"],
["a", "2020-08-12"],
["a", "2020-08-17"],
["b", "2020-08-16"],
["b", "2020-08-19"],
["c", "2020-05-01"],
["c", "2020-05-03"],
["c", "2020-05-04"],
["c", "2020-05-07"]]),
columns=["memberid", "order_date"]
)
print(df.groupby('memberid').nth(-2).dropna())
# order_date
# memberid
# a 2020-08-12
# b 2020-08-16
# c 2020-05-04
df1 = pd.DataFrame(
np.array([
["a", "bthd"],
["a", "bthd_sell"],
["a", "urgent_s"],
["b", "urgent_s"],
["b", "urgent_s"],
["c", "bthd_sell"],
["c", "bthd_sell"],
["c", "christmas"],
["c", "christmas"]]),
columns=["memberid","campaign"]
)
df1['cam_label'] = np.where(df1['campaign'] == 'bthd_sell', 1, np.where(df1['campaign'] == 'urgent_s', 2, ''))
print(df1)
# memberid campaign cam_label
# 0 a bthd
# 1 a bthd_sell 1
# 2 a urgent_s 2
# 3 b urgent_s 2
# 4 b urgent_s 2
# 5 c bthd_sell 1
# 6 c bthd_sell 1
# 7 c christmas
# 8 c christmas
同樣身為先學SQL再學Python的路過~幫樓上改兩處:
df.groupby('memberid',as_index=False).nth(-2)
多了【as_index=False】,對學SQL的來說,看上去肯定舒服多了,哈哈~
另外建議.dropna()不要放,SQL裡縱使對應到的是null,groupby後一樣會秀出(縱使本案例沒有這機會),真要排除也是寫在where(在python則是另寫loc條件),資料處理的順序上,不會在groupby的時候就drop掉(where掉)資料。
...... 'urgent_s', 2, None))
我看原po說他要null,不要給他空白,null是很特別的存在,沒有人可以取代的(吶喊~~)。
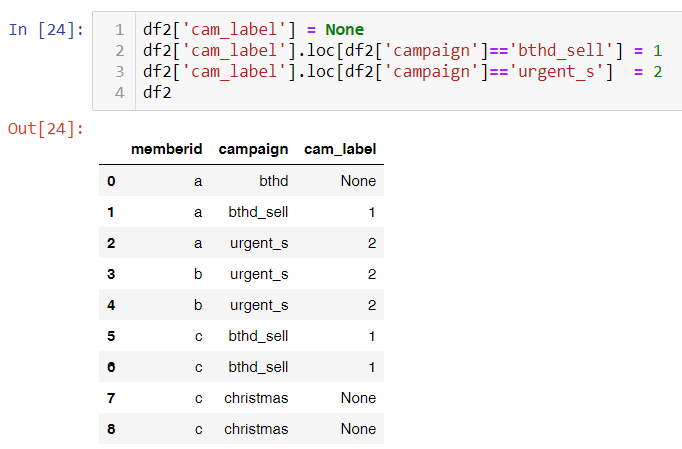
另外第二點啊,python沒有直接case when的概念,概念上是反正你先隨便建出一欄(最好是你原本ELSE要寫的內容),然後再下條件去改。當然寫成樓上那樣比較像是Python慣用者會寫的樣子,只是SQL背景的,應該會比較喜歡寫成如下圖那樣。有點像是SQL中把ELSE搬到第一條先寫好,再寫各種when。
不過還是要注意,Python這指令是彼此獨立的,不像SQL的case when是整包一起,所以如果你的when條件彼此有交集,要留意Python後面的指令,會改到前面的,和SQL中case前面的when可以依序先把想要的挑出來,剩下來的繼續when的概念,還是有所不同。
map 也可以使用函數轉換資料,如下:
import pandas as pd
import numpy as np
df = pd.DataFrame(
np.array([
["a", "2020-08-05"],
["a", "2020-08-12"],
["a", "2020-08-17"],
["b", "2020-08-16"],
["b", "2020-08-19"],
["c", "2020-05-01"],
["c", "2020-05-03"],
["c", "2020-05-04"],
["c", "2020-05-07"]]),
columns=["memberid", "order_date"]
)
print(df.groupby('memberid').nth(-2).dropna())
# order_date
# memberid
# a 2020-08-12
# b 2020-08-16
# c 2020-05-04
df1 = pd.DataFrame(
np.array([
["a", "bthd"],
["a", "bthd_sell"],
["a", "urgent_s"],
["b", "urgent_s"],
["b", "urgent_s"],
["c", "bthd_sell"],
["c", "bthd_sell"],
["c", "christmas"],
["c", "christmas"]]),
columns=["memberid","campaign"]
)
def generate_label(x):
if x == 'bthd_sell':
return 1
elif x == 'urgent_s':
return 2
else: return None
df1['cam_label'] = df1['campaign'] .map(generate_label)
df1