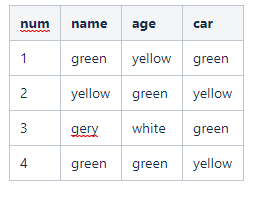
我有一個簡單的表格如下,我想用SQL查詢出, yellow 出現多少次, green出現多少次
SELECT COUNT(CASE WHEN name = "green" then 1 else NULL end) AS green,
COUNT(CASE WHEN name = "yellow" then 1 else NULL end) AS yellow
FROM T1
現在面臨到的問題是 如果同一行有重複的只會算到一次. 求解
(ps 我是要在 confluence 上使用)
已邀請的邦友 {{ invite_list.length }}/5
sql資料
CREATE TABLE `ggg` (
`num` int(11) NOT NULL,
`name` varchar(1) NOT NULL,
`age` varchar(1) NOT NULL,
`car` varchar(1) NOT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
INSERT INTO `ggg` (`num`, `name`, `age`, `car`) VALUES
(1, 'G', 'Y', 'G'),
(2, 'Y', 'G', 'Y'),
(3, 'R', 'W', 'G'),
(4, 'G', 'G', 'Y');
第一種解法
SELECT
sum(if(name='G',1,0)+if(age='G',1,0)+if(car='G',1,0)) AS Gnum,
sum(if(name='Y',1,0)+if(age='Y',1,0)+if(car='Y',1,0)) AS Ynum
FROM `ggg`
第二種解法
SELECT a,count(*) AS num FROM (
SELECT name AS a FROM `ggg` AS n
UNION ALL
SELECT age AS a FROM `ggg` AS a
UNION ALL
SELECT car AS a FROM `ggg` AS c
) AS t GROUP by a
拿去研究
星空大把 values 生出來了,我就補一個 PostgreSQL 使用 array, unnest()的方式.
create table it200918d (
id int not null
, c1 text not null
, c2 text not null
, c3 text not null
);
insert into it200918d values
(1, 'G', 'Y', 'G'),
(2, 'Y', 'G', 'Y'),
(3, 'R', 'W', 'G'),
(4, 'G', 'G', 'Y');
select ca
, count(*)
from (select unnest(array[c1, c2, c3]) ca
from it200918d) a
group by ca;
+----+-------+
| ca | count |
+----+-------+
| Y | 4 |
| R | 1 |
| W | 1 |
| G | 6 |
+----+-------+
(4 rows)
