HI 大家好,小弟Python新手,請各位先進指導。感謝!!
問題: 目前有兩個由爬蟲抓下來的資料,一個是電影名稱'MovieTitle.csv'
一個是Ptt Movie版討論串'PttComment.csv', 如下圖:
MovieTitle.csv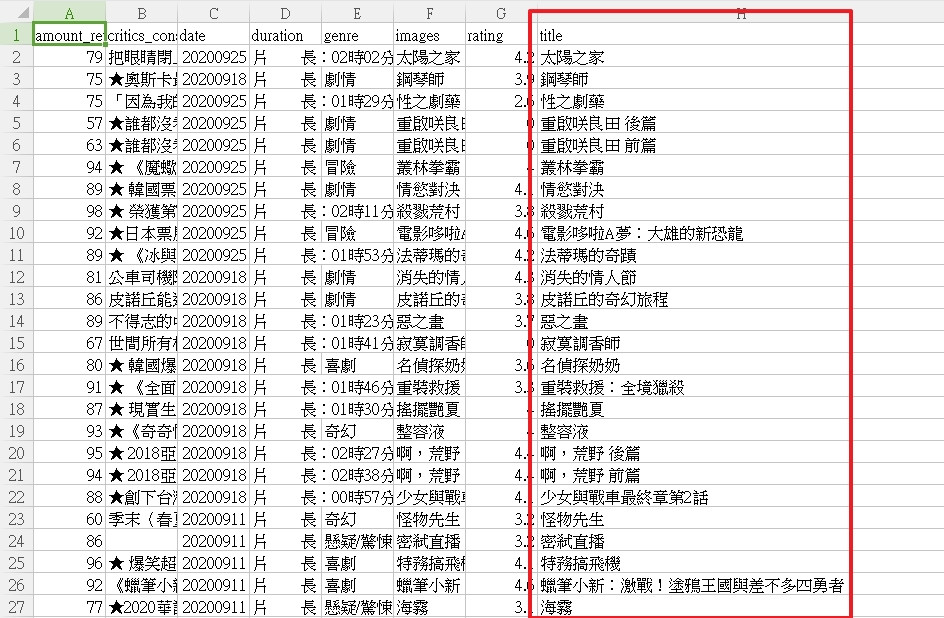
PttComment.csv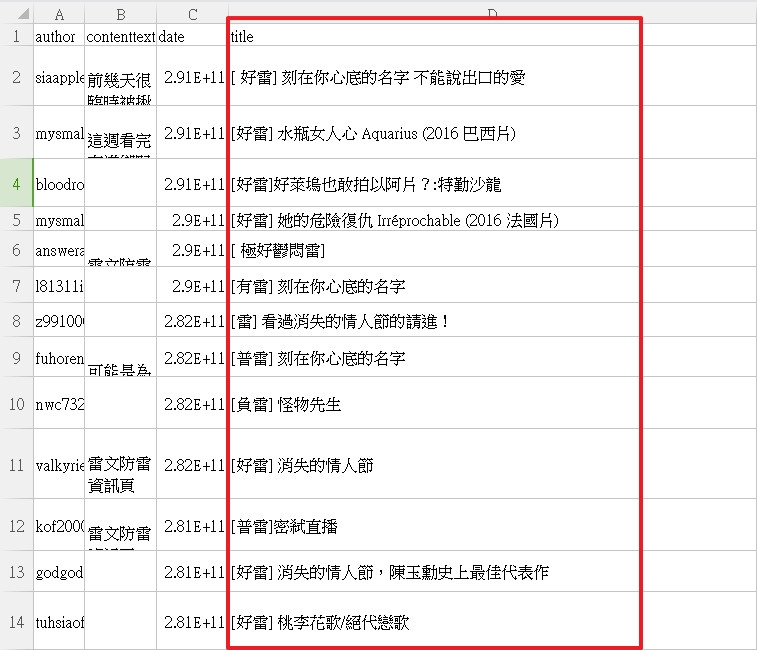
做字串比對使用.str.contains方法 程式碼如下:
`import pandas as pd
# 匯入 PttComment
movies = pd.read_csv("PttComment.csv").dropna(how='all')
movies["title"] = movies["title"].astype("category")
# 匯入 MovieTitle
titles = pd.read_csv("MovieTitle.csv")
key_word = titles.iloc[:, 7]
newDF = pd.DataFrame() # 新增DataFrame 儲存結果
for key in key_word:
mask = movies["title"].str.contains(key) # 字串比對
movies["key_word"] = key # 新增欄位把找到的keyword標記上去
newDF = newDF.append(movies[mask], ignore_index=True)
newDF.to_csv('newdata.csv', index=False) # 匯出新資料
`
結果如下圖: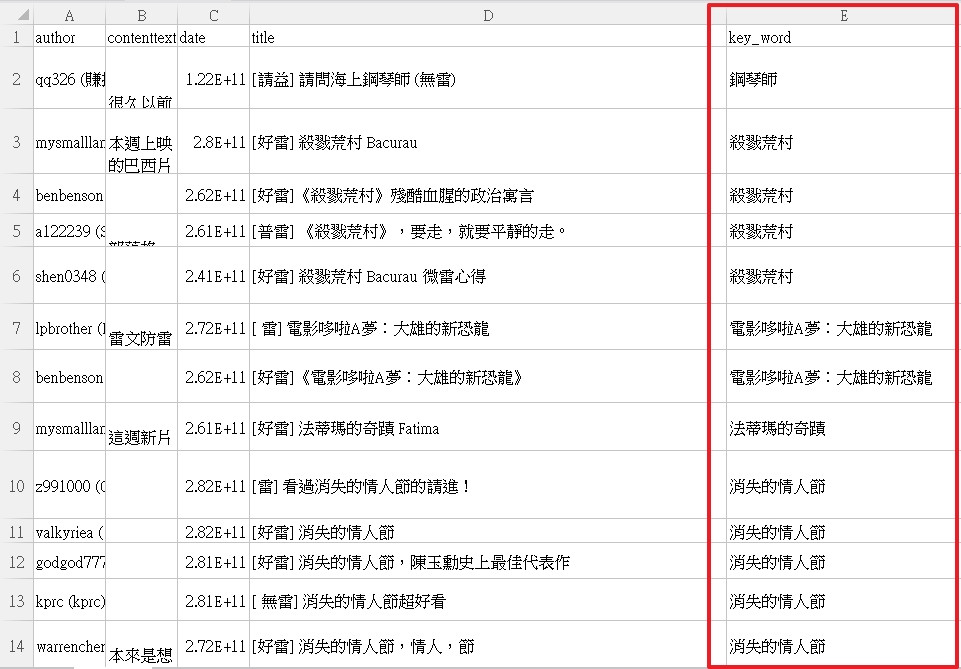
問題:
想請問各位大大,目前這做法跟方向是對的嗎?
還是爬蟲工具就可以做到資料比對了? (我是使用Scrapy)
Pandas有其他更好的方法可以做到嗎? (假如在資料量大的時候)
另外如果想去計算'負雷'跟'好雷'的次數該怎麼做呢?
如果程式碼有誤還請各位大大不吝指教!!
已邀請的邦友 {{ invite_list.length }}/5
排除掉漢字比對會出現不相關字詞或習慣字尾,你用包含contains或 movietitle in pptsubject的方式,應該是沒有問題,但如果有人在ptt的文章標頭打 [好雷]消失情人節,但你的電影清單裡卻只有【消失的情人節】,那上述兩種比對方式,會出現無法符合的狀況
我的解決方案是用中文分詞,我選pyjieba結巴,把movie title跟ppt subject都解成動詞名詞主詞,比對時準確度可以得到提升...不過這個議題會很漫長,有興趣再議
https://pypi.org/project/pyjieba/
用contains比沒什麼問題
不過應該不用建一個新的df來存結果
直接用mask來filter 給值就可以
雷數應該也可以用正則式的方法處理
方便給個範例檔玩玩嗎??
資料沒有個千萬筆 用純panda應該都不是問題
外國人的經驗
https://www.quora.com/Can-Python-Pandas-handle-10-million-rows-What-are-some-useful-techniques-to-work-with-the-large-data-frames
