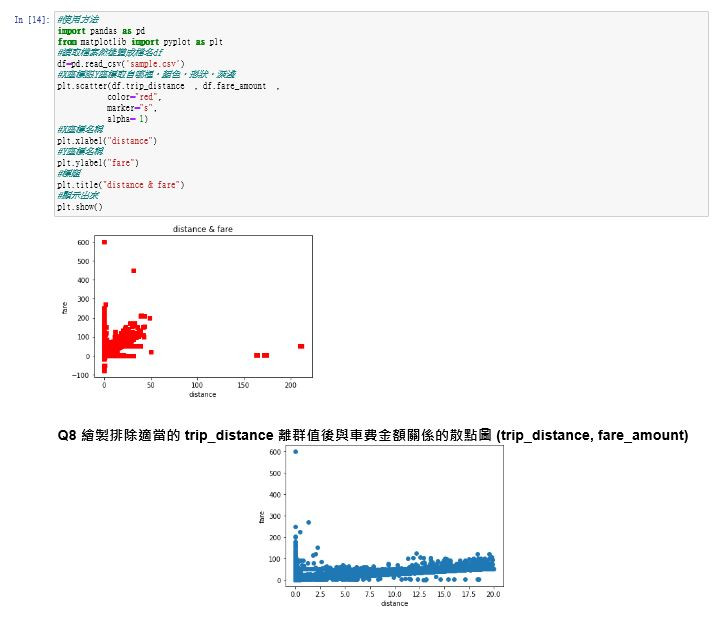
如圖要如何找把離群值去掉
只取正常值就好...
謝謝大大!!
已邀請的邦友 {{ invite_list.length }}/5
建議先將df中的離群值除去,
但是要先闡述離群值判斷的標準,
每個人去除離群值的方法都不一樣,
我這邊提供一個之前去除離群值的一個參考方式:
採用Hampel identifier篩除outliers,考量平均值與標準差可能受outlier之膨脹影響,將樣本平均值以中位數與中位數偏差 (MAD,the median of the absolute deviations from the median) 替代,因中位數與MAD不受outlier影響可為篩選標準,其篩選方式為:
|x_i-M|/((MAD/0.6745))>2.24
其中Xi為樣本實測值,M為樣本中位數,MAD為|Xi-M|(i=1……n)中位數,一般情況下,MAD/0.6745可預估樣本標準差,而篩選常數2.24參自Wilson’s (Erceg-Hurn et al.,2013;Wilcox,2012;Wilcox,2003)。
可以看出上述篩選離群值的方法要有幾個變數,M=>中位數以及MAD,以及篩選常數(本篇是使用2.24)。
df = pd.read_csv('./檔案名稱')
Ms = df.median()
X = df[['欄位名稱']].values
#先用每一筆X樣本計算出MAD
MAD_X = []
for x in X:
MAD_X.append(abs(x-Ms['欄位名稱']))
MAD_X = np.median(MAD_X)
print(MAD_X)
#再一次運算,將超出範圍之離群值刪去
indexs = []
i=0
for x in X:
if (abs(x-Ms['欄位名稱'])/(MAD_X/0.6745))>2.24:
indexNames.append(i)
i+=1
df.drop(indexs , inplace=True)
X = df[['欄位名稱']].values #=>已經將離群值刪除的X ndarray
結果範例:
原本的X最後五筆=
[[181]
[184]
[182]
[177]
[990]]<=故意加進去的outlier
後來的X最後五筆=
[[187]
[181]
[184]
[182]
[177]]<=outlier已被刪除
提供你做參考
