# -*- coding: utf-8 -*-
import pandas as pd
from statsmodels.tsa.arima_model import ARIMA
from datetime import datetime,timedelta,date,time
import warnings
warnings.filterwarnings('ignore')
filename = '03.xlsx'
df = pd.read_excel(filename,header=0,parse_dates=True,index_col=0,squeeze=True)
d = pd.date_range(df.index.min(),df.index.max())
res = pd.Series(df['Close'],d)
res = res.dropna()
print('-----original data-----')
res.index = pd.DatetimeIndex(res.index).to_period('B')
print(res)
r = ARIMA(res,(1,2,0))
model_fit = r.fit(disp=0)
afew = 122
pred = model_fit.predict(start = df.index.max()+timedelta(0), end = df.index.max()+timedelta(afew),typ='levels',dynamic =True)
print('-----'+ str(afew) +' day forecast predict data-----\n'+str(pred))
有 res.index = pd.DatetimeIndex(res.index).to_period('B') 這行就可行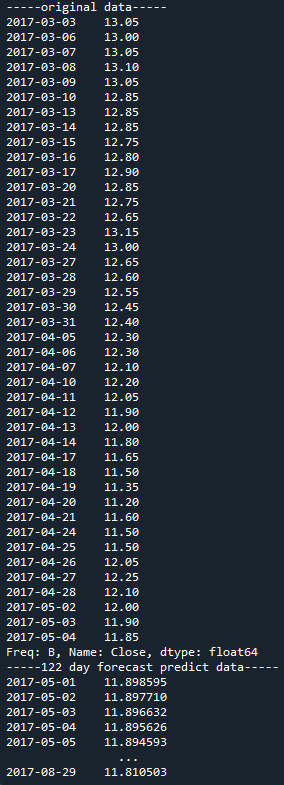
沒有 res.index = pd.DatetimeIndex(res.index).to_period('B') 這行就報錯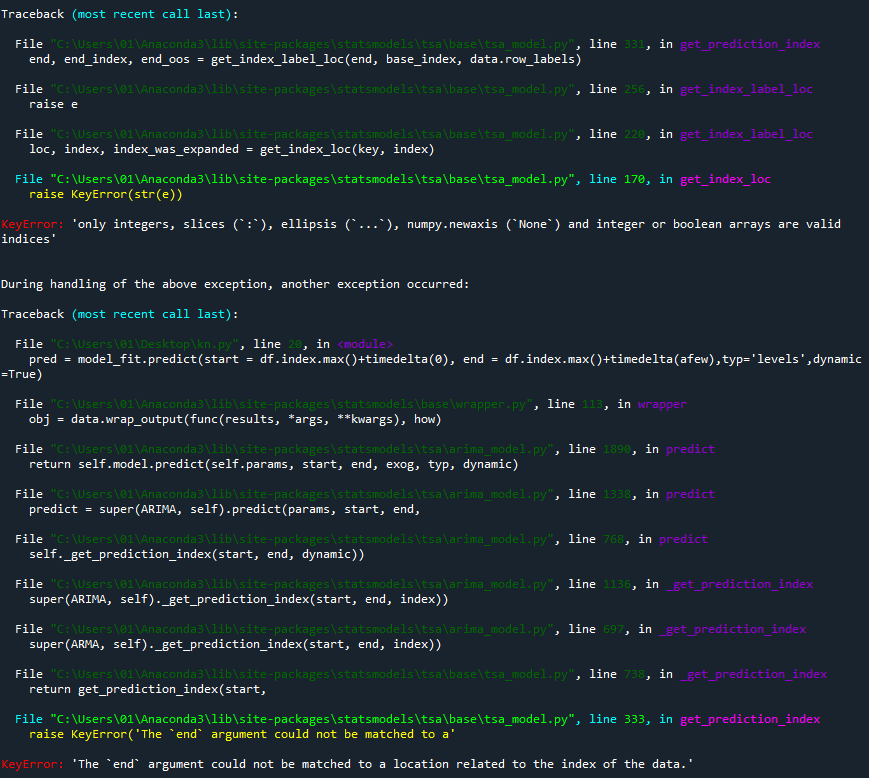
主要錯:
一、 only integers slices (:) ellipsis (...) numpy.newaxis (None) and integer or boolean arrays are valid indices
二、 The end argument could not be matched to a location related to the index of the data
不好意思打擾各位大大了!請問各位大大知道為什麼會這樣嗎?謝謝!
已邀請的邦友 {{ invite_list.length }}/5
.to_period('B')的B是business daysThe end argument could not be matched to a location related to the index of the data參數和index位置無法匹配
你原始的時間資料不是business days
當然無法model.fit
不過我不知道你的model
也不確定你的資料是什麼
所以我大概猜是這樣
參考資料:https://pandasguide.readthedocs.io/en/latest/Pandas/timeseries.html
