新手發問
寫了一個程式去很多個csv檔找特徵,需要把這些找到的存成一個csv檔
但type好像跑掉了
原本的
後來的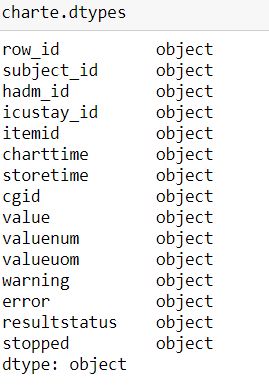
附上程式碼
求大神幫忙
已邀請的邦友 {{ invite_list.length }}/5
你可以在read_csv的時候加參數(dtype)去聲明類型。
然後我真的覺得我的大師頭銜是搬官方文件搬來的。給初學者一些建議,寫程式先去查一下官方文件,不要埋著頭苦幹,然後還幹不出來。
https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.read_csv.html
dtypeType name or dict of column -> type, optional
Data type for data or columns. E.g. {‘a’: np.float64, ‘b’: np.int32, ‘c’: ‘Int64’} Use str or object together with suitable na_values settings to preserve and not interpret dtype. If converters are specified, they will be applied INSTEAD of dtype conversion.
pd.read_csv(file.csv, dtype={"row_id": np.int32, ....})
csv 檔只是單純的文字檔,不含資料型別的資訊,read_csv 會根據資料自動判別資料型別,建議以記事本打開檢查是否有null value或特別的符號。
