小弟想利用python做取代的功能
我想將這兩張表(A、B)作一些整理
A表(實驗設計組合):
a|b|c|d|e|f|g
------------- | -------------
0|2|1|0|1|2|2
1| 1| 2| 1| 0| 1| 0
2| 0| 0| 2| 2| 0| 1
0| 2| 1| 2| 0| 1| 2
1| 1| 2| 0| 2| 0| 1
2| 0| 0| 1| 1| 2| 0
B表(水準表):
水準|a|b|c|d|e|f|g
------------- | -------------
0|24| 1| 32| Sigmoid| SGD| 64| 0.01
1|72| 3| 64| Tanh| RMSprop| 128| 0.05
2|144| 6| 128| ReLU| Adam| 256| 0.1
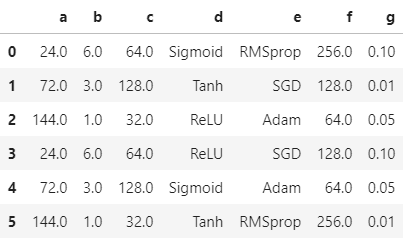
想呈現如下結果:
C表(結果)
a|b|c|d|e|f|g
------------- | -------------
24| 6| 64| Sigmoid| RMSprop| 256| 0.1
72| 3| 128| Tanh| SGD| 128| 0.01
144| 1| 32| ReLU| Adam| 64| 0.05
24| 6| 64| ReLU| SGD| 128| 0.1
72| 3| 128| Sigmoid| Adam| 64| 0.05
144| 1| 32| Tanh| RMSprop| 256| 0.01
小弟是這樣做的
# 读取表
df_my_books = pd.DataFrame(pd.read_excel('./實驗設計組合.xlsx', sheet_name='工作表1'))
df_my_author = pd.DataFrame(pd.read_excel('./水準表.xlsx', sheet_name='工作表1'))
df_my_books1=df_my_books
for i in range(0,df_my_books.shape[1]):
for j in range(0,df_my_books.shape[0]):
df_my_books1.iloc[j,i]=df_my_author.iloc[df_my_books.iloc[j,i],i]
df_my_books1
但結果會出現這個錯誤
ValueError: Location based indexing can only have [integer, integer slice (START point is INCLUDED, END point is EXCLUDED), listlike of integers, boolean array] types
根據小弟測試,好像是最後一欄有小數點那部分出問題
想問一下有甚麼辦法解決或是有更好的寫法
已邀請的邦友 {{ invite_list.length }}/5
我來獻醜一下:
第一種方式:
import pandas as pd
import numpy as np
df1 = pd.read_excel('實驗設計試解.xlsx', sheet_name = '實驗設計')
df2 = pd.read_excel('實驗設計試解.xlsx', sheet_name = '水準表')
df = pd.DataFrame(np.full((6, 7), np.nan))
df.columns = list(df1.columns)
for i in df.columns:
for j in df.index:
df[i][j] = df2[i][df1[i][j]]
df
第二種方式,應該效率再好一點:
import pandas as pd
import numpy as np
df1 = pd.read_excel('實驗設計試解.xlsx', sheet_name = '實驗設計')
df2 = pd.read_excel('實驗設計試解.xlsx', sheet_name = '水準表')
df = pd.DataFrame(np.full((6, 7), np.nan))
df.columns = list(df1.columns)
for x in df.columns:
for y in df2.index:
df[x] = np.where(df1[x] == y, df2[x][y], df[x])
df
第三種方式,改良第一種的語法:
import pandas as pd
import numpy as np
df1 = pd.read_excel('實驗設計試解.xlsx', sheet_name = '實驗設計')
df2 = pd.read_excel('實驗設計試解.xlsx', sheet_name = '水準表')
df = df1
for x in df.columns:
for y in df2.index:
df.loc[df[x] == y, x] = df2[x][y]
df
感覺這做法跟我原本得差不多
只是差在你是建空資料表
我還是不懂我原本那個做法怎麼g欄會出問題
這是我一開始的code:
import pandas as pd
import numpy as np
df1 = pd.read_excel('實驗設計試解.xlsx', sheet_name = '實驗設計')
df2 = pd.read_excel('實驗設計試解.xlsx', sheet_name = '水準表')
df = df1.copy()
#df = pd.DataFrame(np.full((6, 7), np.nan))
#df.columns = list(df1.columns)
for i in df.columns:
for j in df.index:
df[i][j] = df2[i][df1[i][j]]
df
結果也是g欄一直出錯如下:
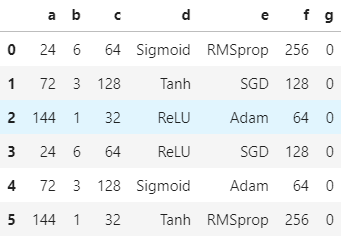
我覺得第一種寫法就蠻好的,但因為資料量不大,其實很難說哪個效率比較好
只寫到這裡ㄗㄐ+U
import pandas as pd
cbt = pd.read_excel("./excel.xlsx", sheet_name="實驗設計組合")
alg = pd.read_excel("./excel.xlsx", sheet_name="水準表")
for _, row in cbt.iterrows():
row[sorted(cbt)] = 1
結果是cbt變1
