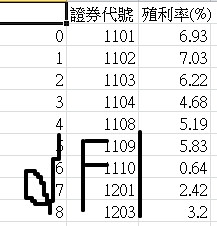
大家好,最近剛開始學python,想請問為什麼將df1的資料引用到df後會出現NaN呢?? 還請各位指教
for i in df['證券代號']:
for x in df1['證券代號']:
if i == x:
df.at[df.index[df['證券代號'] == i].tolist(), "殖利率(%)"] =df1.loc[df1.index[df1['證券代號'] == i].tolist(),'殖利率(%)']
在這段代碼之後CSV檔的殖利率(%)會出現空白而不是出現對應證券代號的殖利率
已邀請的邦友 {{ invite_list.length }}/5
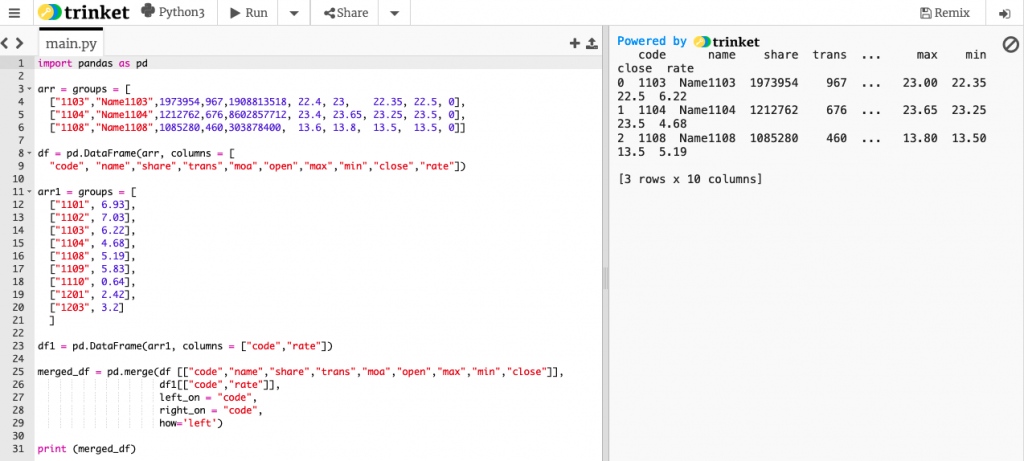
既然已經用 pandas
就不要自己查表比對填值
用 merge 即可
merged_df = pd.merge(df [["code","name","share","trans","moa","open","max","min","close"]],
df1[["code","rate"]],
left_on = "code",
right_on = "code",
how='left')
看起來沒什麼問題~
存csv前print(df)看也是空值嗎
import pandas as pd
df =\
pd.DataFrame([[1103,1104,1108],["","",""]] ).T
df.columns = ["證券代號","殖利率(%)"]
print('df:')
print(df)
df1 =\
pd.DataFrame([[1103,1104,1108],['6.22','4.68','5.19']] ).T
df1.columns = ["證券代號","殖利率(%)"]
print('df1:')
print(df1)
for i in df['證券代號']:
for x in df1['證券代號']:
if i == x:
df.at[df.index[df['證券代號'] == i].tolist(), "殖利率(%)"] =df1.loc[df1.index[df1['證券代號'] == i].tolist(),'殖利率(%)']
print('迴圈後df:')
print(df)
result
df:
證券代號 殖利率(%)
0 1103
1 1104
2 1108
df1:
證券代號 殖利率(%)
0 1103 6.22
1 1104 4.68
2 1108 5.19
迴圈後df:
證券代號 殖利率(%)
0 1103 6.22
1 1104 4.68
2 1108 5.19





 iThome鐵人賽
iThome鐵人賽