我之前有讀過倒傳遞類神經網路(BPNN)且公式也有自己推導過一次,對神經網路略懂一點點,而上禮拜二開始接觸Faster R-CNN,原以為概念會與BPNN類似,結果在第一步就卡關,我知道Faster R-CNN的架構,但很多細節較不清楚,目前我想先理解從輸入圖像至特徵圖的部分,希望各位前輩們能夠協助我理解,首先附上Faster R-CNN架構圖。
這裡Faster R-CNN架構圖稱為訓練模型,汽車稱為欲辨識物件,問題用粗體表示。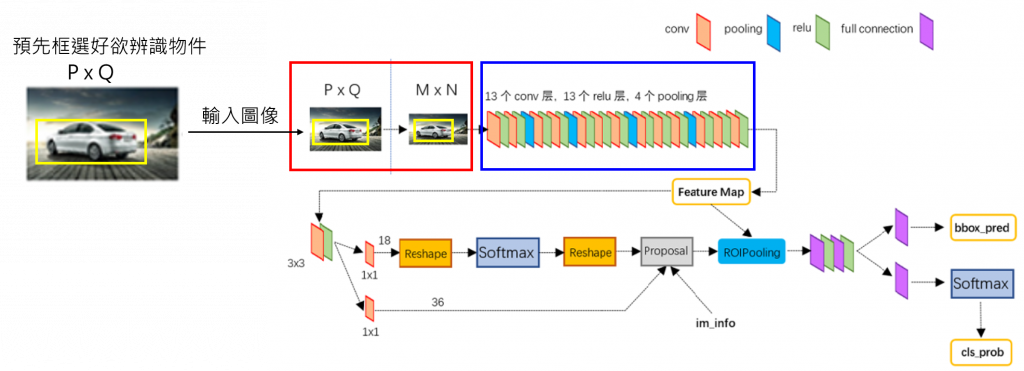
將一張任意大小PxQ的原始圖像輸入至Faster R-CNN訓練模型前會先框選欲辨識物件(架構圖黃框),目的是要先設定我想要訓練及辨識什麼目標,之後才把原始圖像輸入至訓練模型中。
(架構圖紅框)下一步為將一張大小PxQ的原始圖像Reshape成固定大小MxN的圖像,這邊會採用resize(一般影像處理)還是SPP-net,會不會造成圖像特徵失真?
(架構圖藍框)這裡我猜是VGG的做法,但我沒看到全連接層所以不確定,為什麼會需要這麼多卷積、relu與池化層,它的目的是什麼?我看一些文章都說是提取原始圖片的feature map特徵,但我不知道特徵圖上到底有哪些東西(不確定我的理解是對的),更不用說從特徵圖裡面提取什麼資訊。
而我目前對Faster R-CNN前半段的理解是:架構圖紅框的部分先讓每一張原始圖像大小固定,目的是為了後續全連接層的計算,此時訓練模型還不知道欲辨識物件是誰,因此透過這一串卷積、relu與池化層提取欲辨識物件的特徵來告訴訓練模型我想要辨識的物件有哪些,之後再將這些物件輸入至特徵圖上。
以上希望前輩們能協助我理解Faster R-CNN,如果有公式的話也能協助我理解,謝謝:)
已邀請的邦友 {{ invite_list.length }}/5
為什麼會需要這麼多卷積、relu與池化層,它的目的是什麼?
A:多層的卷積可使特徵變的更清晰,可參考下列網址的 圖 1.22:
https://kknews.cc/zh-tw/tech/e4rxzqy.html
