這是我們要做專題所需要用到的資料
資料部分是用kaggle
https://www.kaggle.com/yelp-dataset/yelp-dataset?select=yelp_academic_dataset_business.json
使用其中的
yelp_academic_dataset_business.json"資料
想要把json轉成csv的格式,但也同時要拉第二層巢狀結構的資料上來
前3筆資料結構如下
[{'business_id': '6iYb2HFDywm3zjuRg0shjw',
'name': 'Oskar Blues Taproom',
'address': '921 Pearl St',
'city': 'Boulder',
'state': 'CO',
'postal_code': '80302',
'latitude': 40.0175444,
'longitude': -105.2833481,
'stars': 4.0,
'review_count': 86,
'is_open': 1,
'attributes': {'RestaurantsTableService': 'True',
'WiFi': "u'free'",
'BikeParking': 'True',
'BusinessParking': "{'garage': False, 'street': True, 'validated': False, 'lot': False, 'valet': False}",
'BusinessAcceptsCreditCards': 'True',
'RestaurantsReservations': 'False',
'WheelchairAccessible': 'True',
'Caters': 'True',
'OutdoorSeating': 'True',
'RestaurantsGoodForGroups': 'True',
'HappyHour': 'True',
'BusinessAcceptsBitcoin': 'False',
'RestaurantsPriceRange2': '2',
'Ambience': "{'touristy': False, 'hipster': False, 'romantic': False, 'divey': False, 'intimate': False, 'trendy': False, 'upscale': False, 'classy': False, 'casual': True}",
'HasTV': 'True',
'Alcohol': "'beer_and_wine'",
'GoodForMeal': "{'dessert': False, 'latenight': False, 'lunch': False, 'dinner': False, 'brunch': False, 'breakfast': False}",
'DogsAllowed': 'False',
'RestaurantsTakeOut': 'True',
'NoiseLevel': "u'average'",
'RestaurantsAttire': "'casual'",
'RestaurantsDelivery': 'None'},
'categories': 'Gastropubs, Food, Beer Gardens, Restaurants, Bars, American (Traditional), Beer Bar, Nightlife, Breweries',
'hours': {'Monday': '11:0-23:0',
'Tuesday': '11:0-23:0',
'Wednesday': '11:0-23:0',
'Thursday': '11:0-23:0',
'Friday': '11:0-23:0',
'Saturday': '11:0-23:0',
'Sunday': '11:0-23:0'}},
{'business_id': 'tCbdrRPZA0oiIYSmHG3J0w',
'name': 'Flying Elephants at PDX',
'address': '7000 NE Airport Way',
'city': 'Portland',
'state': 'OR',
'postal_code': '97218',
'latitude': 45.5889058992,
'longitude': -122.5933307507,
'stars': 4.0,
'review_count': 126,
'is_open': 1,
'attributes': {'RestaurantsTakeOut': 'True',
'RestaurantsAttire': "u'casual'",
'GoodForKids': 'True',
'BikeParking': 'False',
'OutdoorSeating': 'False',
'Ambience': "{'romantic': False, 'intimate': False, 'touristy': False, 'hipster': False, 'divey': False, 'classy': False, 'trendy': False, 'upscale': False, 'casual': True}",
'Caters': 'True',
'RestaurantsReservations': 'False',
'RestaurantsDelivery': 'False',
'HasTV': 'False',
'RestaurantsGoodForGroups': 'False',
'BusinessAcceptsCreditCards': 'True',
'NoiseLevel': "u'average'",
'ByAppointmentOnly': 'False',
'RestaurantsPriceRange2': '2',
'WiFi': "u'free'",
'BusinessParking': "{'garage': True, 'street': False, 'validated': False, 'lot': False, 'valet': False}",
'Alcohol': "u'beer_and_wine'",
'GoodForMeal': "{'dessert': False, 'latenight': False, 'lunch': True, 'dinner': False, 'brunch': False, 'breakfast': True}"},
'categories': 'Salad, Soup, Sandwiches, Delis, Restaurants, Cafes, Vegetarian',
'hours': {'Monday': '5:0-18:0',
'Tuesday': '5:0-17:0',
'Wednesday': '5:0-18:0',
'Thursday': '5:0-18:0',
'Friday': '5:0-18:0',
'Saturday': '5:0-18:0',
'Sunday': '5:0-18:0'}},
{'business_id': 'bvN78flM8NLprQ1a1y5dRg',
'name': 'The Reclaimory',
'address': '4720 Hawthorne Ave',
'city': 'Portland',
'state': 'OR',
'postal_code': '97214',
'latitude': 45.5119069956,
'longitude': -122.6136928797,
'stars': 4.5,
'review_count': 13,
'is_open': 1,
'attributes': {'BusinessAcceptsCreditCards': 'True',
'RestaurantsPriceRange2': '2',
'ByAppointmentOnly': 'False',
'BikeParking': 'False',
'BusinessParking': "{'garage': False, 'street': True, 'validated': False, 'lot': False, 'valet': False}"},
'categories': 'Antiques, Fashion, Used, Vintage & Consignment, Shopping, Furniture Stores, Home & Garden',
'hours': {'Thursday': '11:0-18:0',
'Friday': '11:0-18:0',
'Saturday': '11:0-18:0',
'Sunday': '11:0-18:0'}}]
目前我的程式碼如下
import pandas as pd
import json
path = "yelp_academic_dataset_business.json"
reviewList = []
i = 0
with open(path, 'r', encoding='utf-8') as f:
try:
while i<100:
line_data = f.readline()
if line_data:
data = json.loads(line_data)
reviewList.append({
'business_id': data['business_id'],
'name': data['name'],
'address': data['address'],
'city': data['city'],
'state': data['state'],
'postal_code': data['postal_code'],
'latitude': data['latitude'],
'longitude': data['longitude'],
'stars': data['stars'],
'review_count': data['review_count'],
'is_open': data['is_open'],
'attributes': data['attributes'],
'RestaurantsTableService': data['attributes']['RestaurantsTableService'],
'WiFi': data['attributes']['WiFi'],
'BikeParking': data['attributes']['BikeParking'],
'attributes': data['attributes']['BusinessParking'],
'categories': data['categories'],
'hours': data['hours']
})
i+=1
else:
break
except Exception as e:
print(e)
f.close()
i
df = pd.DataFrame(reviewList)
df.to_csv('dataset_business3.csv')
顯示結果如下
'RestaurantsTableService'
輸出的csv資料也只有一行
如下圖
其原因是第二筆資料的['attributes']底下沒有['RestaurantsTableService']這個key
所以造成中斷了資料轉成csv
如果我想讓其如果這筆資料沒有這個key那就補空值或缺失值跑完所有資料,我該怎麼做
想要呈現的結果如下
另外這是在第二層結構下每筆資料可能key不相同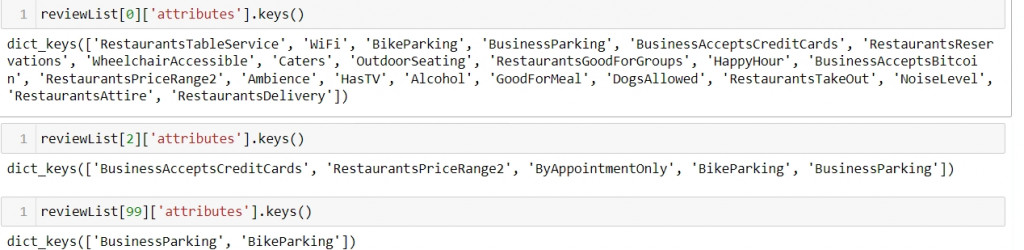
我想要append這筆資料遇到沒有的key自動補缺值讓我能順利輸出每筆資料
先行感謝各位大神
已邀請的邦友 {{ invite_list.length }}/5

