不知為何我執行後我的貼文全部被吃掉只剩下最後一句,求大神幫個忙 感恩
後來我改用list讀取excel一樣被吃掉呢
<更新提供部分程式碼>
程式碼提供如下:
# 捲動
for x in range(5):
chrome.execute_script("window.scrollTo(0,document.body.scrollHeight)")
time.sleep(5)
soup = BeautifulSoup(chrome.page_source, 'html.parser')
print("------------我是分隔線---------------")
titles = soup.find_all(
"div", class_="ecm0bbzt")
for title in titles:
# 定位每一行標題
posts = title.find_all("div", dir="auto")
# 如果有文章標題才印出
if len(posts):
for post in posts:
q1=post.text
a_list =[q1]
print(a_list)
print("------------我是分隔線---------------")
import csv
with open('songs.csv', 'w', newline='', encoding="big5") as csvfile:
# 建立 CSV 檔寫入器
writer = csv.writer(csvfile)
# 寫入一列資料
writer.writerow(["貼文"])
...
writer.writerow([a_list])
# 建立資料夾
import os
import requests
if not os.path.exists("images"):
os.mkdir("images")
# 下載圖片
images = soup.find_all(
"img", class_=["i09qtzwb n7fi1qx3 datstx6m pmk7jnqg j9ispegn kr520xx4 k4urcfbm bixrwtb6", "i09qtzwb n7fi1qx3 datstx6m pmk7jnqg j9ispegn kr520xx4 k4urcfbm"])
if len(images) != 0:
for index, image in enumerate(images):
img = requests.get(image["src"])
with open(f"images/img{index+1}.jpg", "wb") as file:
file.write(img.content)
print(f"第 {index+1} 張圖片下載完成!")
# 等待5秒
time.sleep(5)
# 關閉瀏覽器
chrome.quit()
已邀請的邦友 {{ invite_list.length }}/5
先猜一個
把
writer.writerow([q1.text])
搬到
print(q1.text)
的前一列試試看
解法就這樣
import csv
titles = soup.find_all("div", class_="ecm0bbzt")
for title in titles:
posts = title.find_all("div", dir="auto")
if len(posts):
with open('songs.csv', 'w', newline='', encoding="big5") as csvfile:
# 建立 CSV 檔寫入器
writer = csv.writer(csvfile)
for post in posts:
q1=post
print(q1.text)
print("------------我是分隔線---------------")
writer.writerow([q1.text])
謝謝你 不過我測試後的成果沒抓到內文 excel也沒任何變化呢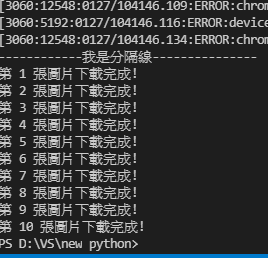
import csv
posts= ["第一篇","第二篇", "第三篇", "第四篇"]
if len(posts):
with open('songs.csv', 'w', newline='', encoding="big5") as csvfile:
# 建立 CSV 檔寫入器
writer = csv.writer(csvfile)
for post in posts:
q1=post
print(q1)
print("------------我是分隔線---------------")
writer.writerow([q1])
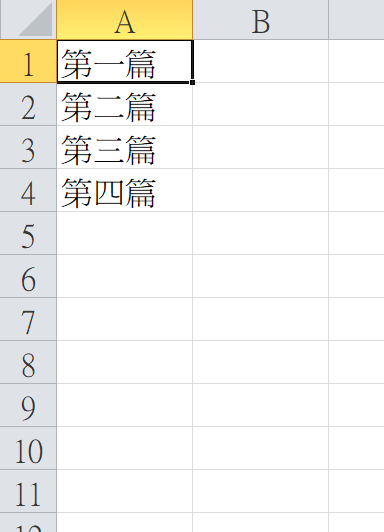
我帶假資料來測試EXCEL寫入這一段應該要是對的才對,能貼看看你的code嗎?
code 我放在本貼文了若再不行我再貼完整的給你好嗎?
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from bs4 import BeautifulSoup
import time
options = webdriver.ChromeOptions()
# options.add_argument("--headless") #不開啟實體瀏覽器背景執行
options.add_argument("--start-maximized") #最大化視窗
options.add_argument("--incognito") #開啟無痕模式
options.add_argument("--disable-popup-blocking ") #禁用彈出攔截
# 使用 Chrome 的 WebDriver
chrome = webdriver.Chrome(options = options)
options.add_argument("--disable-notifications")
# 'C:\\Users\\USER\\AppData\\Local\\Programs\\Python\\Python310\\Scripts\\chromedriver.exe'
chrome.get("https://www.facebook.com/")
email = chrome.find_element_by_id("email")
password = chrome.find_element_by_id("pass")
email.send_keys('your fb account')
password.send_keys('your password')
password.submit()
time.sleep(10)
# 螢幕最大化
chrome.maximize_window()
chrome.get('https://www.facebook.com/search/top?q=%E7%AB%B9%E8%BC%AA%E9%9B%BB%E5%8B%95%E8%BB%8A')
# 捲動
for x in range(5):
chrome.execute_script("window.scrollTo(0,document.body.scrollHeight)")
time.sleep(2)
soup = BeautifulSoup(chrome.page_source, 'html.parser')
print("------------我是分隔線---------------")
titles = soup.find_all("div", class_="ecm0bbzt")
import csv
with open('songs.csv', 'w', newline='', encoding="BIG5", errors='ignore') as csvfile:
# 建立 CSV 檔寫入器
writer = csv.writer(csvfile)
# 寫入一列資料
writer.writerow(["貼文"])
if titles:
for title in titles:
#將貼文內容寫入到EXCEL檔案裡
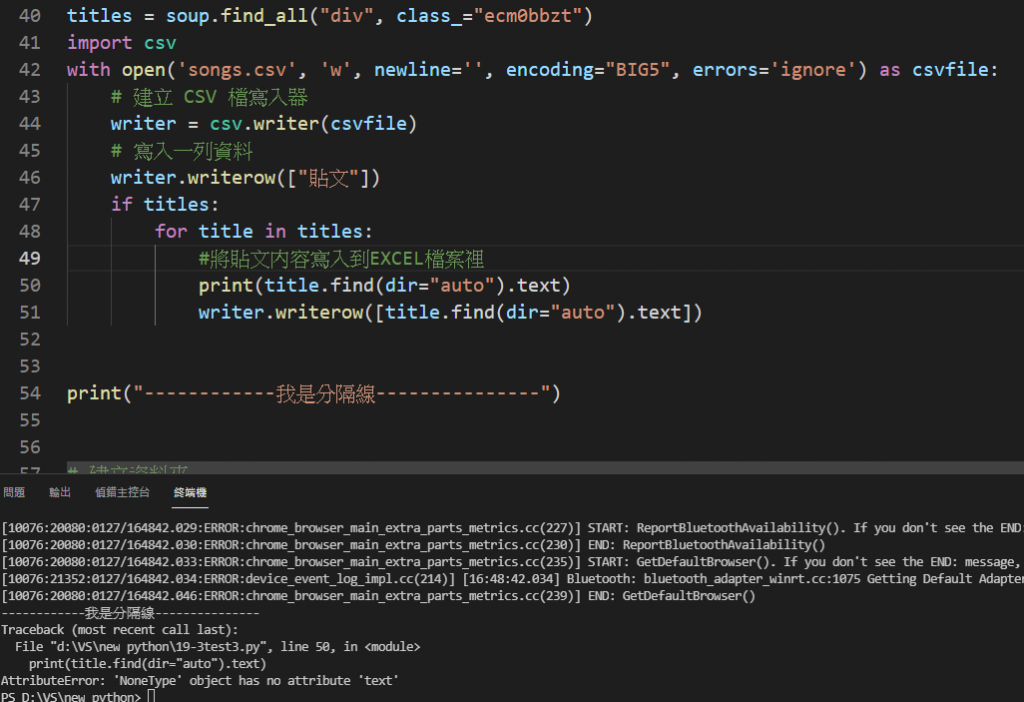
print(title.find(dir="auto").text)
writer.writerow([title.find(dir="auto").text])
print("------------我是分隔線---------------")
# 建立資料夾
import os
import requests
if not os.path.exists("images"):
os.mkdir("images")
# 下載圖片
images = soup.find_all(
"img", class_=["i09qtzwb n7fi1qx3 datstx6m pmk7jnqg j9ispegn kr520xx4 k4urcfbm bixrwtb6", "i09qtzwb n7fi1qx3 datstx6m pmk7jnqg j9ispegn kr520xx4 k4urcfbm"])
if len(images) != 0:
for index, image in enumerate(images):
img = requests.get(image["src"])
with open(f"images/img{index+1}.jpg", "wb") as file:
file.write(img.content)
print(f"第 {index+1} 張圖片下載完成!")
# 等待5秒
time.sleep(5)
# 關閉瀏覽器
chrome.quit()
完整的code補在這邊囉,請樓主大大自行參考^^
大大我的會出錯...到底是為什麼呢?