您好:
參考
https://www.runoob.com/python3/python-urllib.html
from urllib.request import urlopen
myURL = urlopen("https://www.runoob.com/")
f = open("runoob_urllib_test.html", "wb")
content = myURL.read() # 读取网页内容
f.write(content)
f.close()
結果卻是亂碼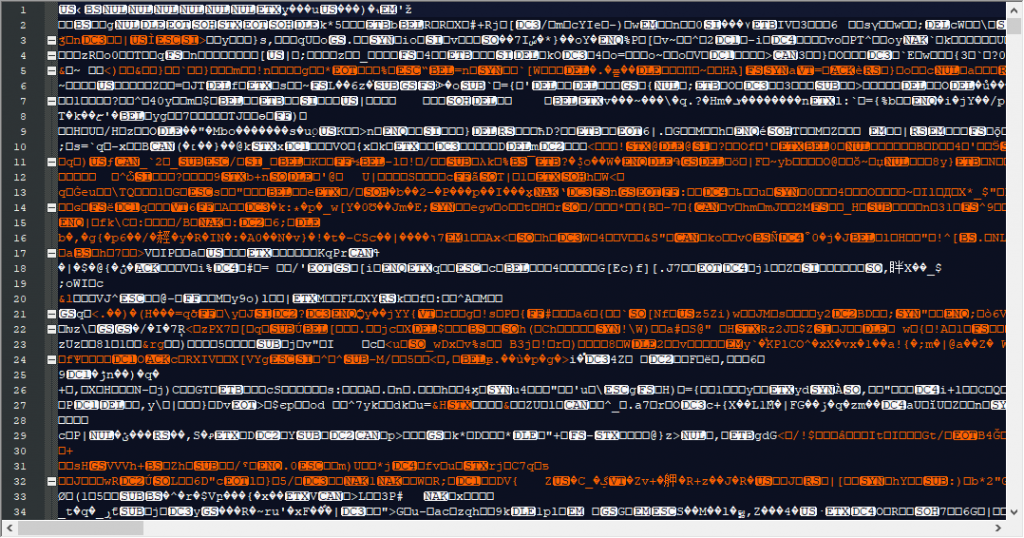
另外一個範例
import urllib.request
import urllib.parse
url = 'https://www.runoob.com/?s=' # 菜鸟教程搜索页面
keyword = 'Python 教程'
key_code = urllib.request.quote(keyword) # 对请求进行编码
url_all = url+key_code
header = {
'User-Agent':'Mozilla/5.0 (X11; Fedora; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36'
} #头部信息
request = urllib.request.Request(url_all,headers=header)
reponse = urllib.request.urlopen(request).read()
fh = open("./urllib_test_runoob_search.html","wb") # 将文件写入到当前目录中
fh.write(reponse)
fh.close()
結果也是亂碼
與
https://www.runoob.com/wp-content/uploads/2021/04/6BD0D456-E929-4C11-9118-F09C85AEA427.jpg
的結果不同
請問這是哪邊需要調整
謝謝!
已邀請的邦友 {{ invite_list.length }}/5
from urllib.request import urlopen
import gzip
from io import BytesIO
myURL = urlopen("https://www.runoob.com/")
f = open("runoob_urllib_test.html", "wb")
gziped_buffer = BytesIO(myURL.read())
gziped_response = gzip.GzipFile(fileobj=gziped_buffer)
html_binary = gziped_response.read()
f.write(html_binary)
f.close()
網頁被gzip壓縮了,需要在記憶體中建立一個file-like object(BytesIO)做buffer,然後解壓縮。
用 requests 套件可以更快完成你要做的事情,附上範例以及安裝套件方式
pip install requests
import requests
res = requests.get(url="https://www.runoob.com/")
with open("./runoob_urllib_test.html", "w", encoding="utf-8") as file:
file.write(res.text)
根據 requests 套件,你的第二個範例也可以修改成如下方式,可以看到 keyword 的部分可以直接寫進 url 當中,python 會自動替您進行編碼,無須再透過 urllib.request.quote 進行操作
import requests
url = "https://www.runoob.com/?s=Python 教程"
headers = {'User-Agent': 'Mozilla/5.0 (X11; Fedora; Linux x86_64) '
'AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/58.0.3029.110 Safari/537.36'}
res = requests.get(url=url, headers=headers)
file_path = "./urllib_test_runoob_search.html"
with open(file_path, "w", encoding="utf-8") as file:
file.write(res.text)
附上你這個網站對應的教學網址:https://www.runoob.com/python3/python-requests.html

 iThome鐵人賽
iThome鐵人賽
{kind=link}