您好:
目前資料的結構如下示: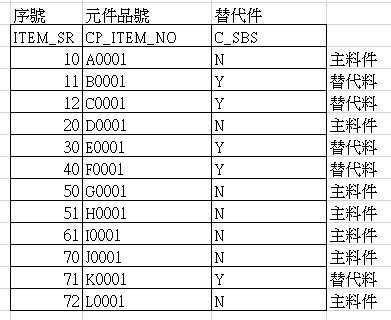
ITEM_SR只是各料輸入的順序,主料與替代料的關連方式為:
當C_SBS為N時的下一筆C_SBS為Y的情況下,這筆C_SBS為N的料是主料,
C_SBS為Y的料是替代料,一直遇到下一筆C_SBS為N的時候停止主料與替代
料的關係。
因此期待查詢的結果如下示: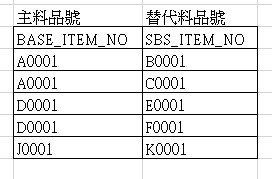
還請各位高手協助如果不在AP端解決的情況下,是否可以使用SQL來達成這樣的查詢,
謝謝您。
已邀請的邦友 {{ invite_list.length }}/5
DECLARE @Test TABLE
(
[ITEM_SR] INT,
[CP_ITEM_NO] NVARCHAR(20) NULL,
[C_SBS] NVARCHAR(20) NULL -- N:主料代 Y:替代料
);
INSERT INTO @Test ([ITEM_SR], [CP_ITEM_NO], [C_SBS])
VALUES (10, 'A0001', 'N'),
(11, 'B0001', 'Y'),
(12, 'C0001', 'Y'),
(20, 'D0001', 'N'),
(30, 'E0001', 'Y'),
(40, 'F0001', 'Y'),
(50, 'G0001', 'N'),
(51, 'H0001', 'N'),
(61, 'I0001', 'N'),
(70, 'J0001', 'N'),
(71, 'K0001', 'Y'),
(72, 'L0001', 'N');
WITH [BASE] AS (SELECT *
FROM @Test
WHERE [C_SBS] = 'N'
),
[SBS] AS (SELECT *
FROM @Test
WHERE [C_SBS] = 'Y'
)
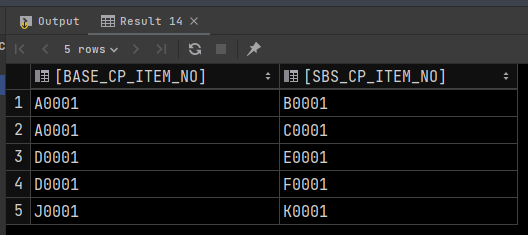
SELECT [BASE2].[CP_ITEM_NO] AS [BASE_CP_ITEM_NO],
[SBS].[CP_ITEM_NO] AS [SBS_CP_ITEM_NO]
FROM [SBS]
OUTER APPLY (SELECT TOP 1 *
FROM [BASE]
WHERE [SBS].[ITEM_SR] > [ITEM_SR]
ORDER BY [ITEM_SR] DESC
) [BASE2]
CREATE TABLE TEST (
ITEM_SR INT,
CP_ITEM_NO NVARCHAR(20) NULL,
C_SBS NVARCHAR(20) NULL);
INSERT INTO TEST (ITEM_SR,CP_ITEM_NO,C_SBS) VALUES
(10,'A0001','N'),
(11,'B0001','Y'),
(12,'C0001','Y'),
(20,'D0001','N'),
(30,'E0001','Y'),
(40,'F0001','Y'),
(50,'G0001','N'),
(51,'H0001','N'),
(61,'I0001','N'),
(70,'J0001','N'),
(71,'K0001','Y'),
(72,'L0001','N'),
-- 額外加入
(110,'A0001','N'),
(111,'B0001','Y'),
(112,'C0001','Y'),
(210,'A0001','N'),
(211,'B0002','Y'),
(212,'C0002','Y');
WITH CTE_X1 AS (
SELECT ITEM_SR,CP_ITEM_NO,C_SBS
FROM TEST
),
CTE_X2 AS (
SELECT CP_ITEM_NO,ITEM_SR AS ITEM_SR_START,C_SBS,
LEAD(ITEM_SR, 1, (SELECT MAX(ISNULL(ITEM_SR,0)) + 1 FROM TEST))
OVER (ORDER BY ITEM_SR) AS ITEM_SR_END
FROM CTE_X1
WHERE C_SBS = 'N')
SELECT DISTINCT B.CP_ITEM_NO AS 'BASE_ITEM_NO',A.CP_ITEM_NO AS 'SBS_ITEM_NO'
FROM CTE_X1 AS A
LEFT JOIN CTE_X2 AS B ON A.ITEM_SR >= B.ITEM_SR_START AND A.ITEM_SR < B.ITEM_SR_END
WHERE A.CP_ITEM_NO <> B.CP_ITEM_NO
ORDER BY B.CP_ITEM_NO,A.CP_ITEM_NO
解法參考 :[SQL]歷史異動資料有生失效區間, 如何用善用PIVOT橫長
(欄位值 = NULL 時抓同群組的第一筆非 NULL 值填入)
【SQL Server 2008】未測
WITH CTE_01 AS (
SELECT CP_ITEM_NO,ITEM_SR,C_SBS,
CASE WHEN C_SBS = 'Y' THEN 0 ELSE 1 END AS NO_TEMP
FROM TEST
),
CTE_02 AS (
SELECT *,
(SELECT SUM(X.NO_TEMP) FROM CTE_01 AS X WHERE X.ITEM_SR <= A1.ITEM_SR) AS NO
FROM CTE_01 AS A1
),
CTE_03 AS(
SELECT CP_ITEM_NO,ITEM_SR,C_SBS,ROW_NUMBER() OVER (ORDER BY ITEM_SR) AS NO
FROM TEST
WHERE C_SBS = 'N')
SELECT DISTINCT B.CP_ITEM_NO AS 'BASE_ITEM_NO',A2.CP_ITEM_NO AS 'SBS_ITEM_NO'
FROM CTE_02 AS A2
LEFT JOIN CTE_03 AS B ON B.NO = A2.NO
WHERE A2.CP_ITEM_NO <> B.CP_ITEM_NO
ORDER BY B.CP_ITEM_NO,A2.CP_ITEM_NO
我不會
因為我不解其精妙之處
照這個設計概念
如果 A0001 要加一個替代料
大概會是
13 B0002 Y
如果再加 7 個替代料
不知道如何處理,因為 ITEM_SR 會變成
14,15,16,17,18,19 (20 已使用了)
大概最多不會有那麼多替代料吧
