各位大大好!
假如我現在有一個二元的list=
['1', '0', '1', '0', '1', '1', '0', '0', '1', '0', '1', '0', '0', '0', '0', '0', '0', '0', '0', '0', '0', '1', '1', '0', '0', '0', '0', '0', '1', '0', '0', '0', '0', '0', '1', '1', '1']
我要怎麼計算每次碰到1之前出現的0的次數累積(但1也要計算如果有重複的話
如
1 0
1 0
11 00
1 0
1 00000000000
11 00000
1 00000
111
所以資料會變成
category(1,0)
1,1
1,1
2,2
1,1
1,10
2,5
3,0
以此類推....
#因為我的帳號是新手訓練帳號不能進行回應 不過的確就是遇到1會製造一個斷點
已邀請的邦友 {{ invite_list.length }}/5
我只會用最笨的方法(自己加總)寫
結果如下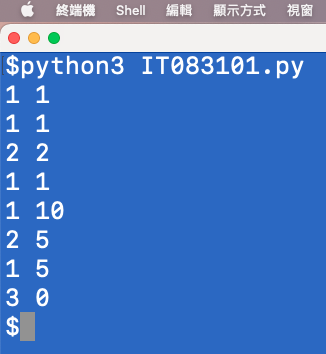
我是以第一個值一定是 '1' 為基準寫的,如果有 '0' 開始的,那就要改一下邏輯,就自己加幾個判斷自己寫吧。
from itertools import zip_longest
data = [[arr[0], 1]]
for n in arr:
if data[-1][0] == n:
data[-1][1] += 1
else:
data.append([n, 1])
for one, zero in list(zip_longest(data[::2], data[1::2], fillvalue=['0', 0])):
print(f'{one[1]},{zero[1]}')
試解如下,不曉得是不是樓主要的:
from itertools import groupby
mylist = (['1', '0', '1', '0', '1', '1', '0', '0', '1', '0', '1',
'0', '0', '0', '0', '0', '0', '0', '0', '0', '0', '1',
'1', '0', '0', '0', '0', '0', '1', '0', '0', '0', '0', '0', '1', '1', '1'])
res = [(len(list(cgen))) for c, cgen in groupby(mylist)]
if mylist[-1] == '1':
res.append(0)
res
[1, 1, 1, 1, 2, 2, 1, 1, 1, 10, 2, 5, 1, 5, 3, 0]
for i in range(0, len(res), 2):
print(res[i], res[i+1])
1 1
1 1
2 2
1 1
1 10
2 5
1 5
3 0
