各位大神 前輩們好,
小弟參考了:
[ASP.net MVC] 將HTML轉成PDF檔案,使用iTextSharp套件的XMLWorkerHelper (附上解決顯示中文問題)
這篇高大的文,
但按照範例去寫一樣無法有效解決中文亂碼問題,
也爬過其他的文都沒得到解決方式,
有想過是不是沒有成功引用到 UnicodeFontFactory Class,
但我不確定是哪裡出了問題...
以下是我的程式碼,
再請大神們指點!
Controller:
public ActionResult FluSign()
{
return View();
}
public ActionResult _ExportSummary()
{
WebClient wc = new WebClient();
//從網址下載Html字串
string htmlText = wc.DownloadString("http://localhost:53878/Data/Sign");
byte[] pdfFile = this.ConvertHtmlTextToPDF(htmlText);
return File(pdfFile, "application/pdf", "test.pdf");
}
public byte[] ConvertHtmlTextToPDF(string htmlText)
{
if (string.IsNullOrEmpty(htmlText))
{
return null;
}
//避免當htmlText無任何html tag標籤的純文字時,轉PDF時會掛掉,所以一律加上<p>標籤
htmlText = "<p>" + htmlText + "</p>";
MemoryStream outputStream = new MemoryStream();//要把PDF寫到哪個串流
byte[] data = Encoding.UTF8.GetBytes(htmlText);//字串轉成byte[]
MemoryStream msInput = new MemoryStream(data);
Document doc = new Document();//要寫PDF的文件,建構子沒填的話預設直式A4
PdfWriter writer = PdfWriter.GetInstance(doc, outputStream);
//指定文件預設開檔時的縮放為100%
PdfDestination pdfDest = new PdfDestination(PdfDestination.XYZ, 0, doc.PageSize.Height, 1f);
//開啟Document文件
doc.Open();
//使用XMLWorkerHelper把Html parse到PDF檔裡
XMLWorkerHelper.GetInstance().ParseXHtml(writer, doc, msInput, null, Encoding.UTF8, new UnicodeFontFactory());
//將pdfDest設定的資料寫到PDF檔
PdfAction action = PdfAction.GotoLocalPage(1, pdfDest, writer);
writer.SetOpenAction(action);
doc.Close();
msInput.Close();
outputStream.Close();
//回傳PDF檔案
return outputStream.ToArray();
}
UnicodeFontFactory Class:
public class UnicodeFontFactory : FontFactoryImp
{
private static readonly string arialFontPath = Path.Combine(Environment.GetFolderPath(Environment.SpecialFolder.Fonts),
"arialuni.ttf");//arial unicode MS是完整的unicode字型。
private static readonly string 標楷體Path = Path.Combine(Environment.GetFolderPath(Environment.SpecialFolder.Fonts),
"KAIU.TTF");//標楷體
public override Font GetFont(string fontname, string encoding, bool embedded, float size, int style, BaseColor color, bool cached)
{
//可用Arial或標楷體,自己選一個
BaseFont baseFont = BaseFont.CreateFont(標楷體Path, BaseFont.IDENTITY_H, BaseFont.EMBEDDED);
return new Font(baseFont, size, style, color);
}
}
View:
<!DOCTYPE html>
<html>
<body>
<table style='width:100%;'>
<tr>
<td colspan='2' style='color:#808080;'>
[廠商名稱]
</td>
</tr>
<tr style='font-size:13px;'>
<td style='width:600px;color:#808080;font-size:16px;'>Taiwan Limited 4F,144 Changchun Rd., Taipei 104, Taiwan</td>
<td style='width:80%;color:#808080;font-size:16px;text-align:right;'>[頁碼]/[總頁數]</td>
</tr>
</table>
</body>
</html>
另外詢問是否有比 iTextSharp 還好用的套件呢?
table裡面不能加 br 或 div 之類的HTML語法,
好像有點難用...?
已邀請的邦友 {{ invite_list.length }}/5
我試過那篇高大的文,可以正常轉換
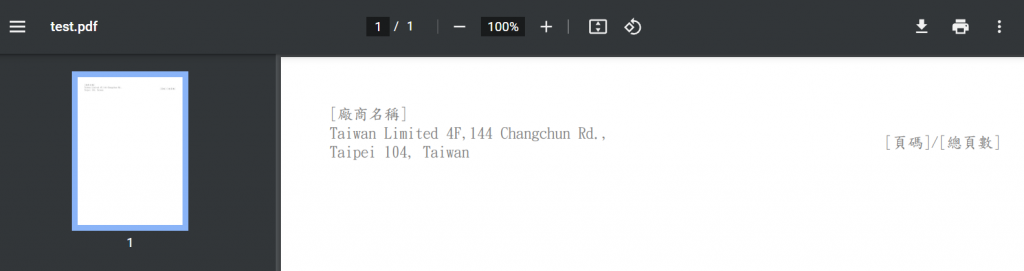
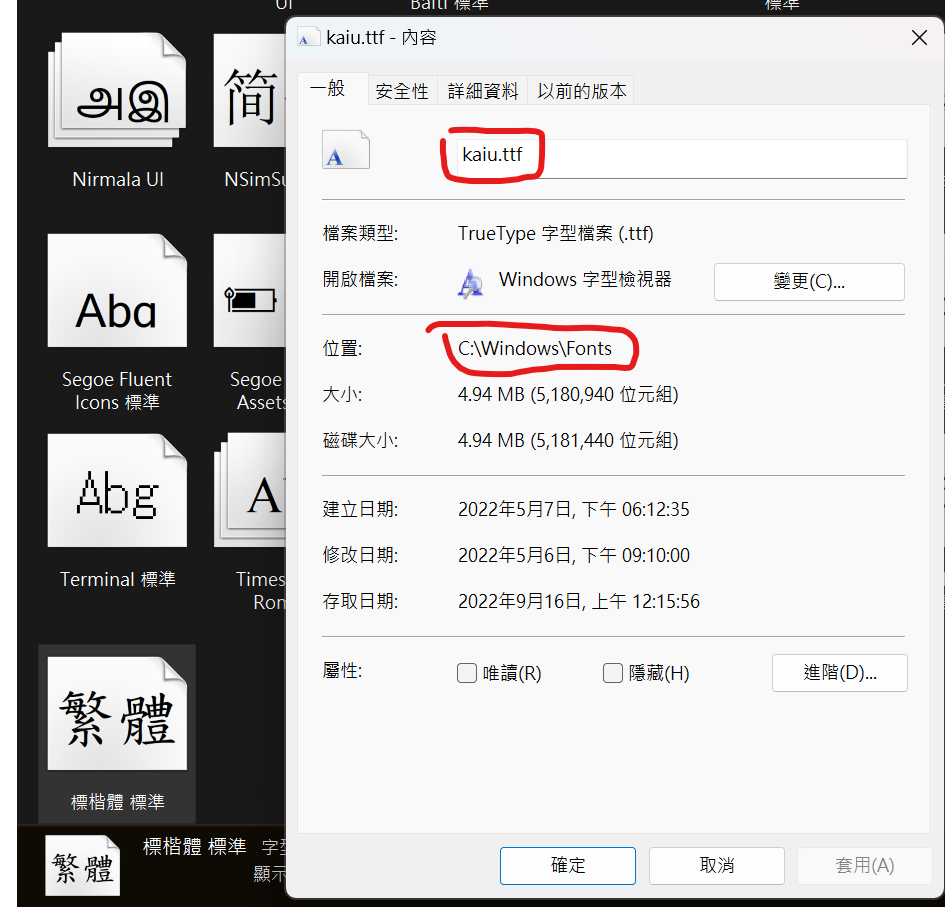
我是指定標楷體測試的,可以確認一下這一段Path.Combine(Environment.GetFolderPath(Environment.SpecialFolder.Fonts), "KAIU.TTF") 字型檔案,預設會上會放置在 C:\Windows\Fonts\kaiu.ttf
可以檢查一下沒有安裝標楷體,沒有的話可以安裝一下
如果還是不行可以確認看看 wc.DownloadString 這段抓到的是不是亂碼 (要用UTF8編碼)
以上兩個方向給您參考
不要只會用孤味語言,在工作上很吃虧,多學一套不會怎樣
我用PYTHON + BORB
from borb.pdf.document import Document
from borb.pdf.page.page import Page
from borb.pdf.pdf import PDF
from borb.pdf.canvas.layout.paragraph import Paragraph
from borb.pdf.canvas.layout.page_layout.multi_column_layout import SingleColumnLayout
from borb.io.read.types import Decimal
document = Document()
page = Page()
#建立PDF基本頁面排版,應付XML用的
layout = SingleColumnLayout(page)
# 把字體以20點TAHOMA字型寫入PDF,一行一行寫
layout.add(Paragraph("Hello World", font_size=Decimal(20), font="TAHOMA"))
# 加入PDF頁面
document.append_page(page)
# 寫成PDF
with open("output.pdf", "wb") as pdf_file_handle:
PDF.dumps(pdf_file_handle, document)
在windows或linux下,基本上都不會遇到亂碼的問題,除非你的XML本身就不是UTF8
