大家好,小弟目前再寫碩士論文,程式上遇到一點小麻希望大家能幫幫忙。
目前在做文字探勘詞頻的部分,使用TF-IDF來計算詞頻,計算出來,但卻不好分類,還請大家幫幫忙。
目前將文字斷詞斷句後呈現如下(僅列出6筆資料):
all=[['停工', '停工'], ['受影響', '停工', '停工', '停工', '停工'], ['出現問題', '打包', '狀況', '缺乏', '措手不及', '隔離', '隨意', '爆出'], ['不實', '虛偽', '違反', '罰鍰', '檢舉'], ['不能勝任', '抗議', '裁員', '裁撤', '解僱'], ['不當', '申訴', '歧視', '涉及', '解僱']]
得出的結果如下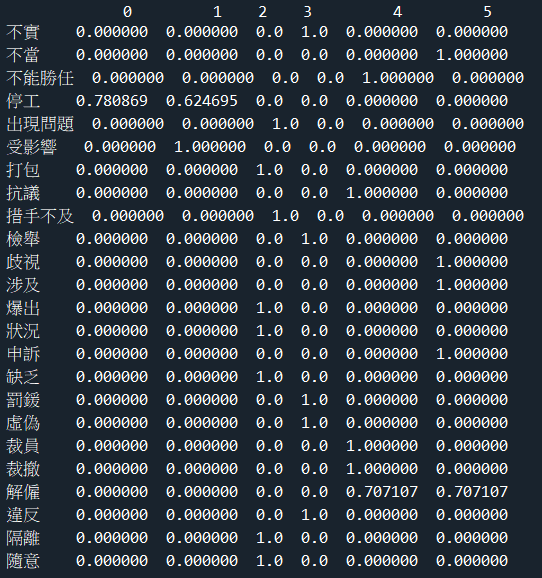
但希望能呈現出
result=[{'停工': 0.780869}, {'受影響': 1, '停工': 0.624695}, {'出現問題': 1, '打包': 1, '狀況': 1, '缺乏': 1, '措手不及': 1, '隔離': 1, '隨意': 1, '爆出': 1}, {'不實': 1, '虛偽': 1, '違反': 1, '罰鍰': 1, '檢舉': 1}, {'不能勝任': 1, '抗議': 1, '裁員': 1, '裁撤': 1, '解僱': 0.707107}, {'不當': 1, '申訴': 1, '歧視': 1, '涉及': 1, '解僱': 0.707107}]
請問有什麼方法可以解決嗎?因為資料有接近三千筆QQ
因為我剛學python,有冒犯的地方請大家見諒
已邀請的邦友 {{ invite_list.length }}/5
提供本人的解法
x=pd.DataFrame(results).transpose()
x1=x.to_dict()
for k in list(x1.keys()):
for j in list(x1[k].keys()):
if x1[k][j] == 0:
del x1[k][j]
print(x1)
