小區域,時間為10月09日22時57,地點為花蓮縣政府南南西方89.5公里(位於花蓮縣卓溪鄉),深度16.8公里,地震規模3.5
小弟目前在學習爬蟲,會利用爬蟲到中央氣象局抓取地震資訊(最新的的資訊)
我想用python,抓取地震規模後面的3.5這個數值
每個抓取的最新地震,字數不會一樣,所以沒辦法用特定的位置來抓取!
想請問有什麼寫法,可以抓取地震規模後面的數字!!
再請各位大大幫幫忙了,非常感謝
已邀請的邦友 {{ invite_list.length }}/5
照你說的話我可能會這樣寫
import re
dataList = ["小區域,時間為10月09日22時57,地點為花蓮縣政府南南西方89.5公里(位於花蓮縣卓溪鄉),深度16.8公里,地震規模3.5",
"小區域,時間為10月09日22時57,地點為花蓮縣政府南南西方89.5公里(位於花蓮縣卓溪鄉),深度16.8公里,地震規模8",
"小區域,時間為10月09日22時57,地點為花蓮縣政府南南西方89.5公里(位於花蓮縣卓溪鄉),深度16.8公里,地震規模8.7"]#你存資料的地方
for i in dataList:
if "地震規模" in i:
index = i.index("地震規模")+4#四個字
square = [float(num) for num in re.findall(r'-?\d+\.?\d*',i[index:])][0]
#避免後面還有字或符號
print(square)
但是,我猜你是直接抓https://www.cwb.gov.tw/V8/C/E/index.html
這網頁的資料,若不是的話沒差再說。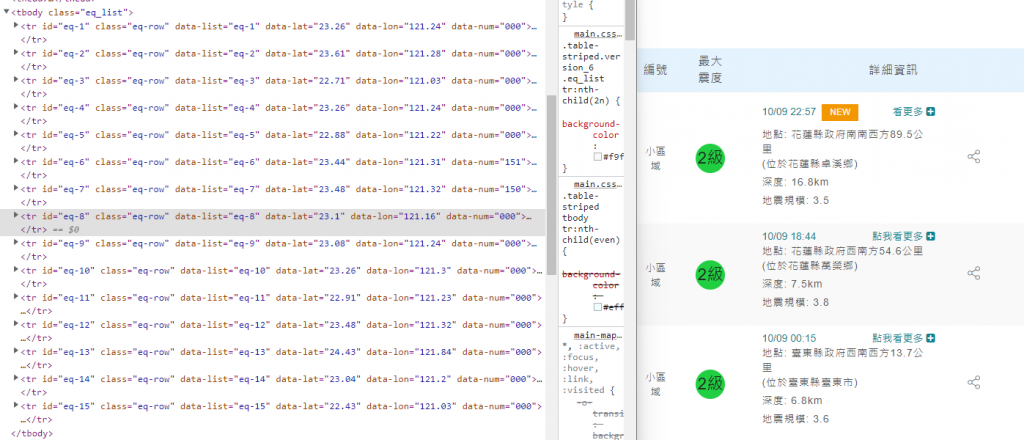
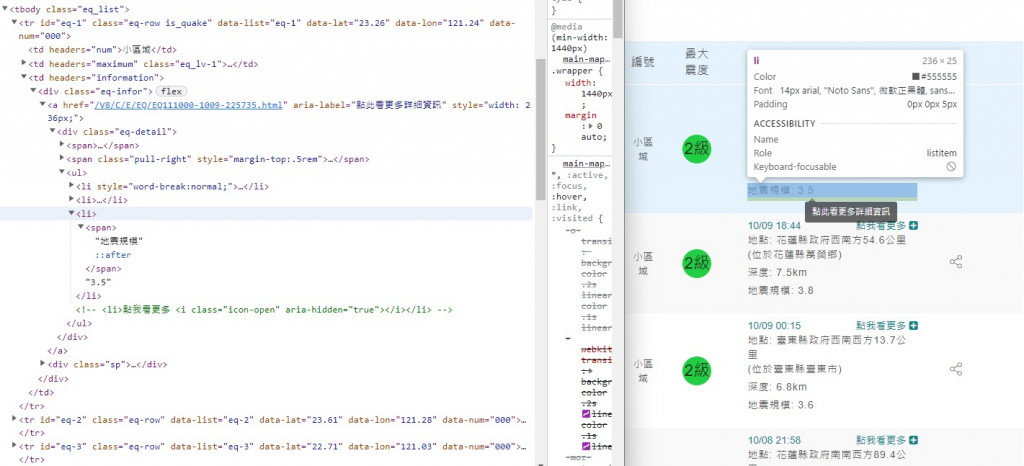
你有沒有想過,直接在爬蟲的時候,直接透過抓取欄位,然後分析規則把裡面的東西爬出來就好呢?
就可以少了一次執行程式的功喔
split('地震規模')[1]
感謝回覆~,雖然這個我不會用??,有詳細一點的寫法嗎!!
參考看看,拆分後變成串列,取出第二個項目
https://steam.oxxostudio.tw/category/python/basic/string.html#a6
好的感謝您
研究了一下要怎麼用爬蟲處理 ajax,由於 ajax 是使用 js 向伺服器發出請求,然後接收到伺服器的回應,所以如果先找出想要的資料是透過哪個網址回傳的回應,就能讓爬蟲也對該網址送出請求,得到的回應裡面就有所需要的資料了
await fetch前面加上let response=,把伺服器回傳的結果存到response變數中html 是文字檔,沒辦法用response.json()處理,在 Using the Fetch API:Processing a text file line by line 找到處理文字檔的範例,只要把範例程式中會用到的變數urlOfFile跟函式processLine(Line)先定義好,再複製貼上就能使用run函式,不過不知道為何範例是直接呼叫使用,照理說應該要加上await才對
以上是一步一步用 js 處理得到資料的過程
若用 python,大概長這樣,header 的部分我是從「於主控台以 Fetch 方式使用」產出的headers複製貼上
from bs4 import BeautifulSoup as bs
import requests
url = f'https://www.cwb.gov.tw/V8/C/E/MOD/MAP_LIST.html?T=2022101102'
header = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36",
"Accept": "*/*",
"Accept-Language": "zh-TW,zh;q=0.8,en-US;q=0.5,en;q=0.3",
"X-Requested-With": "XMLHttpRequest",
"Sec-Fetch-Dest": "empty",
"Sec-Fetch-Mode": "cors",
"Sec-Fetch-Site": "same-origin",
"Pragma": "no-cache",
"Cache-Control": "no-cache"
};
response = requests.get(url, headers=header)
soup = bs(response.text, 'html.parser')
後續的取出數字就是像上面解答的一樣,透過正規表示法抽出來
或是像 retex_z 說的那樣
soup.select('a')[0].getText().split('地震規模')[1]
提供兩個滿常用的方法:
1.使用正則表達式
https://steam.oxxostudio.tw/category/python/library/re.html
2.使用 split 拆分字串
https://steam.oxxostudio.tw/category/python/basic/string.html#a6
