各位高手,自學想練習取各章節的標題,我google了半天找不到相關訊息,不知道要從哪個角度去學習
再麻煩各位指導我個方向,感謝大家
程式碼:
import requests
from bs4 import BeautifulSoup
import time
from selenium import webdriver
Path = "D:\python pratice/chromedriver.exe"
driver = webdriver.Chrome(Path)
driver.get("https://www.comicabc.com/html/103.html")
soup = BeautifulSoup(driver.page_source, 'lxml') #driver.page_source =右鍵點屬性
target_url = "https://www.comicabc.com/html/103.html"
# 取鏈接和章節名
r = requests.get(url = target_url)
bs = BeautifulSoup(r.text, 'lxml')
list_con_li = bs.find('tr')
cartoon_list = list_con_li.find_all('a')
chapter_names = []
chapter_urls = []
for cartoon in cartoon_list:
href = cartoon.get('href')
name = cartoon.text
chapter_names.insert(0, name)
chapter_urls.insert(0, href)
print(cartoon_list)
之前嘗試取其他網站有成功,但這網站就不行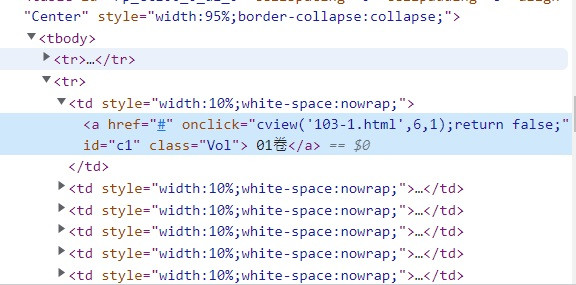
已邀請的邦友 {{ invite_list.length }}/5
使用Xpath做要抓取元素的定位
links = driver.find_elements_by_xpath("//table[@id='rp_ctl00_0_dl_0']/tbody/tr/td/a")
for i in links:
print(i.text)
第一層先抓特定id的Table
再依序往下直到你所想要的資料為止
感謝obarisk熱心回覆
這段語法應改為
links = driver.find_elements(By.XPATH,"//table[@id='rp_ctl00_0_dl_0']/tbody/tr/td/a")
且要多引用
from selenium.webdriver.common.by import By
才不會造成語法錯誤

 iThome鐵人賽
iThome鐵人賽