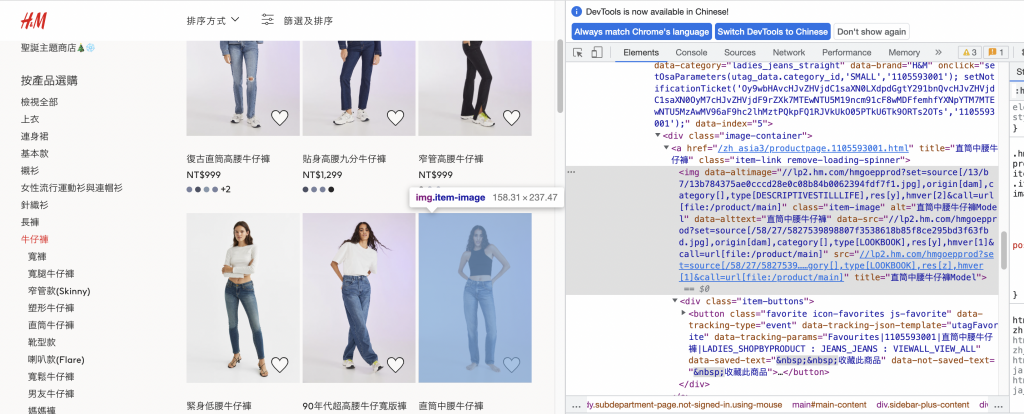
各位前輩好!,因課業需求我需要抓取電商平台網站上的圖片,但是遇到一個問題,我在使用selenium時,會有抓不下來的問題,因為當我游標指到圖片上時,圖片會做更動,如下:
(游標未指)
(游標指向圖片後)
想請問是否不能直接使用find_element(By.CLASSNAME),來做抓取動作,因為一直抱錯或抓不到,謝謝各位!
以下附上我的程式碼以及網頁資訊:
from ast import keyword
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.common.exceptions import TimeoutException
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.chrome.service import Service
import time
import os
import wget
#設定隨機的延遲時間
import random
import time
delay_choices = range(5,15) #延遲的秒數
delay = random.choice(delay_choices) #隨機選取秒數
#time.sleep(delay) #延遲
#設定使用者代理(User-Agent)
import requests
from fake_useragent import UserAgent
keyword = "jeans"
user_agent = UserAgent()
response = requests.get(url="https://www2.hm.com/en_asia3/ladies/shop-by-product/jeans.html", headers={ 'user-agent': user_agent.random })
driver = webdriver.Chrome("/Users/wulixuan/Downloads/chromedriver")
driver.get("https://www2.hm.com/en_asia3/ladies/shop-by-product/jeans.html")
time.sleep(4)
cookie = driver.find_element(By.ID, 'onetrust-accept-btn-handler')
cookie.click()
time.sleep(2)
for i in range(8):
driver.execute_script("window.scrollTo(0, 6900);")
time.sleep(delay)
loadmore = driver.find_element(By.XPATH,"/html/body/main/div/div/div/div[3]/div[2]/button")
loadmore.click()
#By.XPATH, '//*[@id="page-content"]/div/div[3]/div[2]/button'
imgs = driver.find_elements(By.CLASS_NAME, 'item-image')
path = os.path.join("H&M" + keyword)
os.mkdir(path)
count = 0
for img in imgs:
save_as = os.path.join(path, keyword + str(count) + '.jpg')
#print(img.get_attribute("src")) #取得他的屬性也就是src,且要下載就需要取得src
wget.download(img.get_attribute("src"), save_as)
count += 1
time.sleep(6)
driver.quit()
謝謝大家,祝福一切順利。
已邀請的邦友 {{ invite_list.length }}/5
滑鼠移上去的圖片路徑好像放在同一個img的data-altimage
可以試試看下載data-altimage路徑的圖片
