這兩天在學網頁爬蟲 現在遇到問題卡關
爬了好多文都沒有解答 因此上來求助
我想要抓取 select html 中 td colspan=2 下的文字
但這裡沒有標籤也沒有Class 我不知道要怎麼選到
實際html如下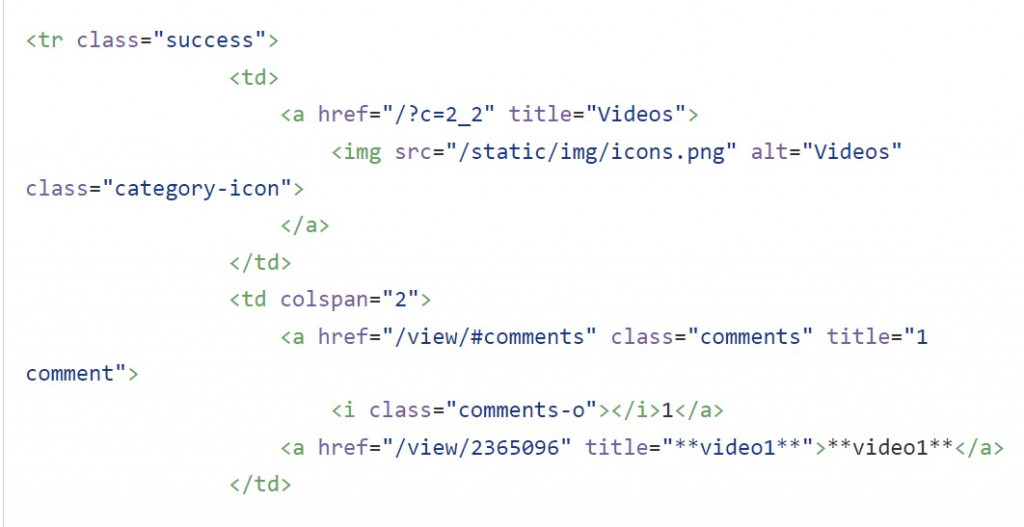
我想抓取video1的這個文字部分 但不知怎麼select
謝謝解惑
已邀請的邦友 {{ invite_list.length }}/5
以下寫法不是最佳解,只是我第一時間隨便想到的,如有必要請自行最佳化。
#from bs4 import BeautifulSoup
## 如果 CSS selector 找到的目標 'tr.success' 在第一個:
soup = BeautifulSoup(content)
getStr = soup.select('tr.success')[0] \
.find_all('td', recursive=False)[0] \
.find_all('a', recursive=False)[1] \
.string
print(getStr)
另,巡航/遍歷物件請參考 "Navigating the tree" / "遍历文档树"
AttributeError: ResultSet object has no attribute 'find_all'. You're probably treating a list of elements like a single element. Did you call find_all() when you meant to call find()?
你好 我試了幾次一直得到此錯誤 請問是甚麼意思 謝謝
請確認你安裝的版本。
我用的是 "beautifulsoup4",其內有 "find_all()" ;
而 "BeautifulSoup" (v3) 裡面沒有 "find_all()" 。
( 舊的 BeautifulSoup 3 倒是有 "findAll()",我不清楚差異,請自參閱比較舊的 "Beautiful Soup 3 Doc" 與新的 "Beautiful Soup 4 Doc" )
另,就網頁上的說明,BeautifulSoup 已停止維護且建議使用 beautifulsoup4;但我不知你的狀況與需求,請自行確認與判斷。
了解謝謝 另外請問一下
如果我想要select的tr class不只success
例如還有tr class = default
(裡面html內容一樣 只是class不同)
我要怎麼寫在select function裡面?
找tr success or default底下的內容
謝謝
你是要列出所有符合 CSS selector 選出的?
#from bs4 import BeautifulSoup
soup = BeautifulSoup(content, features='html.parser')
for item in soup.select('tr.success, tr.default'):
myStr = item \
.find_all('td', recursive=False)[0] \
.find_all('a', recursive=False)[1] \
.string
print(myStr)

 iThome鐵人賽
iThome鐵人賽