我最近在學如何使用BS4時遇到這個問題
body = inner.find("div" ,itemprop = "articleBody")被報說錯
find() takes no keyword arguments
改成find_all後又被說str沒有這個attribute
但是我單把這項拿出來另開個檔案測試卻又抓得到原本要抓的內文
請問個為大大如何解決這問題?
import bs4
root=bs4.BeautifulSoup(data,"html.parser")#data是透過網路抓下來的資料(html原始碼)丟給bs4會用html解析
titleLinks = root.find_all("div",class_="c-articleItem__title")
page = root.find("a",class_="c-pagination c-pagination--next")
for titleLink in titleLinks:
titles = titleLink.a.text
articleLink = "https://www.mobile01.com/" + titleLink.a["href"]
ws.cell(i,1,i)
ws.cell(i,2,titles)
ws.cell(i,3,articleLink)
mWeb.save("mobile.xlsx")
request=req.Request(articleLink,headers={
"User-Agent":"Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/106.0.0.0 Mobile Safari/537.36"
})
with req.urlopen(request) as response:
inner = response.read().decode("utf-8")
body = inner.find("div" ,itemprop = "articleBody")
article = body.text
ws.cell(i,6,article)
print(article)
mWeb.save("mobile.xlsx")
i = i+1
n = 1
#抓時間作者資料
titleInfos = root.find_all("div",class_="l-listTable__td l-listTable__td--time")
for titleInfo in titleInfos:
author = titleInfo.div.a.text
#timeInfo = titleInfo.div.next_sibling.text
timeInfo = titleInfos.find("div" , class_ = "o-fNotes")
ws.cell(n,4,author)
ws.cell(n,5,timeInfo)
mWeb.save("mobile.xlsx")
n = n+1
url = "https://www.mobile01.com/" + page["href"]
還有另外一個問題就是不知為何我titleInfos = root.find_all("div",class="l-listTabletd l-listTabletd--time" 這行不會執行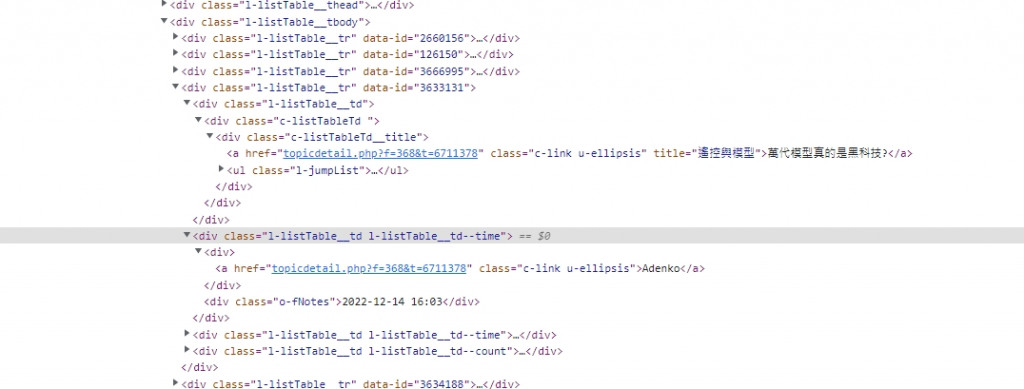
已邀請的邦友 {{ invite_list.length }}/5
