版上各位好
小弟最近想爬嘖嘖募資平台上的專案資訊,但這幾天開始出現某幾頁無法爬出來的問題,原本設定的時間間隔都沒問題...想請問是否有高手知道是什麼部分出問題了嗎?
有改過user agent 或 換不同ip連線去爬都沒改善,因為該平台有用cloudflare保護,因此cfscrape也用過了但好像也沒改善
下圖是爬出來問題圖,18-20爬不到,但21開始又可以了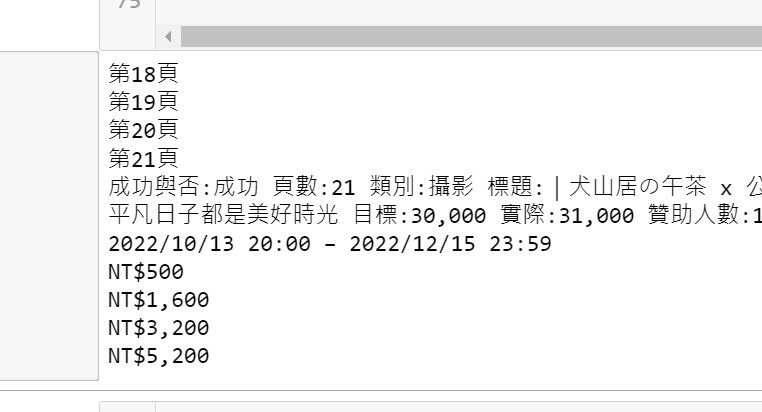
import requests
import bs4
import time
import random
import cfscrape #Anti-CDN
scraper = cfscrape.create_scraper(delay=15) #Anti-CDN
def get_page_info(URL):
headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/105.0.0.0 Safari/537.36'}
response = requests.get(URL,headers=headers)
#response = scraper.get(URL,timeout=60,headers=headers)
soup = bs4.BeautifulSoup(response.text,"html.parser")
data=soup.find_all('div','text-black project text-neutral-600 mx-4 mb-4 pb-12 relative h-full')
for t in data:
href = t.find("a","block").attrs["href"] #取a標籤下href後面的網址
link ="https://www.zeczec.com"+href
result=t.find('span','font-bold').text.strip() #外面頁面擷取專案成功與否資訊
response_2 = requests.get(link,headers=headers)
soup_2 = bs4.BeautifulSoup(response_2.text,"html.parser") #解析取下的網址中的網頁內容
main_info = soup_2.find_all('div','container lg:my-8')
donate_price = soup_2.find_all('div', 'lg:w-full px-4 lg:px-0 flex-none self-start xs:w-1/2')
delay_time_1=[13,15,12]
delay_1=random.choice(delay_time_1)
time.sleep(delay_1)
for i in main_info:
category = i.find_all('a','underline text-neutral-600 font-bold inline-block')[1].text.strip()
title = i.find('h2', 'text-xl mt-2 mb-1 leading-relaxed').text.strip()
final_cash = i.find('div','text-2xl font-bold js-sum-raised whitespace-nowrap leading-relaxed').text.strip()
# goal_cash = i.find('div','text-xs leading-relaxed').text.strip()
goal_cash = i.find('div','text-xs leading-relaxed text-black').text.strip()
people = i.find('span','js-backers-count').text.strip()
timeline = i.find('div','mb-2 text-xs leading-relaxed').text.strip()
final='成功與否:{} 頁數:{} 類別:{} 標題:{} 目標:{} 實際:{} 贊助人數:{} 時間:{}'.format(result,page,category,title,goal_cash[6:],final_cash[3:],people,timeline[2:])
print(final)
for a in donate_price:
price = a.find('div','text-black font-bold text-xl').text.strip()
print(price)
for i in range(18,201,1):
print("第"+str(i)+"頁")
page= i
URL='https://www.zeczec.com/categories?page='+str(i)+'&type=0' #不排序專案的網址
get_page_info(URL)
time.sleep(random.randint(20,30))
已邀請的邦友 {{ invite_list.length }}/5
可試著讓sleep time是隨機的
表現得更像一般人類這樣
Update:
我覺得你可能誤解我的提議/狀況了。(或該說,我說明不清楚。)
我這邊發現的狀況,並不是被檔,而是伺服端以兩個模板(?)交替回應客端的要求。
而在這狀況下,會導致你的搜尋條件 data=soup.find_all('div','text-black project text-neutral-600 mx-4 mb-4 pb-12 relative h-full') 在一個模板能找到資料(len(data) == 12),
在伺服端換用另一個模板時會找不到資料(len(data) == 0),而產生空資料。
(所以我的搜尋條件才會用data = soup.find_all('div', class_='project');不然你可以把條件換成你的來看看結果。)
因以上狀況,我才會放簡單觀察用的程式碼給你參考並觀察伺服端的回應,讓你確認你的狀況是因為被檔還是模板交替而造成的。
如此你才能從問題或現象來設計解決方案。
P.s.
關於程式碼的更新,我在 mySleepD = random.randint(20,30) 這裡改回你設定的時間了,想改時間請自便~(還請不要太超過就是了~)
而顯示的字數([:70])等雜七雜八的你也可以自改~
(就我而言,把回應丟到不同檔案內做對比會比較便捷~)
目前,就我看到的,網站以兩個模板(?)不時地交換以回應請求的內容。
可能原因很多(例如負載轉換、各種的最佳化等),我就懶得說了~
(至於我為何會知道,因為我在思考過濾條件並測試時,注意到 requests 網頁內容的結構在變動~)
想看個大概的話,能試試以下的程式碼(小改(?)自發問者的程式碼;會花上一段時間喔~):
##
import requests, bs4
import random, time
#import cfscrape #Anti-CDN
#scraper = cfscrape.create_scraper(delay=15) #Anti-CDN
##
def get_page_info(URL):
headers = { 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/105.0.0.0 Safari/537.36' }
response = requests.get(URL,headers=headers)
## 列印回應的狀態碼,並印出回應內容的前 70 的字元。
print(' □ status:' + str(response.status_code) + '; text:', (response.text[:70]).replace('\n'," "))
if(response.status_code != 200): return ## 不屬於正常回應時跳出 func.;
##
soup = bs4.BeautifulSoup(response.text,"html.parser")
#data=soup.find_all('div','text-black project text-neutral-600 mx-4 mb-4 pb-12 relative h-full')
data = soup.find_all('div', class_='project')
print(' □ len(data):', str(len(data))) ## 顯示 data 內容數量;
myCount, myLimit = 0, 3 ## 設定只顯示前三個;
for t in data:
if(not(myCount < myLimit)): break ## 第四個時跳出 for loop;
print(' ■ t:', (str(t)[:100]).replace('\n'," ")) ## 顯示 t 與後續共 100 個字元;
for c in t.find_all(True, recursive=False): ## 搜尋 t 直屬子標籤
print(' □ c:', (str(c)[:100]).replace('\n'," ")) ## 顯示 t 直屬子標籤,與後續共 100 個字元;
myCount += 1
return
##
#for i in range(18,201,1):
i = 16
for ctr in range(10): ## 跑10次測試
URL = r'https://www.zeczec.com/categories?page=' \
+ str(i) + r'&type=0' #不排序專案的網址
print('■ ' + str(ctr) + ':第'+str(i)+'頁:', URL)
get_page_info(URL)
mySleepD = random.randint(20,30)
print("■ sleep(s):", mySleepD)
time.sleep(mySleepD)
##
解決方法我是覺得你應該能自行處理(畢竟知道可能原因了~)。
P.s. 改 headers 可能沒用;我試過把 Chrome 送出請求時的大部分 headers 內容都用上了,還是一樣會模板交替~(但你還是能試試,畢竟你我狀況不同~)
@ethank: 請參考我的回答之 update 。
@ethank
該樓主的意思應該是
該網站會有兩種reponse樣式
你可能只處裡了一種,
當遇到另一種的時候你爬蟲可能就失敗了.
非常感謝樓上兩位大大的說明!!
我大致了解了 我來處理看看
