請教版上各問大大
關於
count(*) / count(0) / count(1) / count(行列) 效能問題請益
小弟平常多數使用 count(*) 進行資料統計
有點不太清楚,以上count 的用法差異效能如何 ?
想請大神指點迷經
目前所使用的版本如下
Microsoft SQL Server Management Studio 14.0.17289.0
已邀請的邦友 {{ invite_list.length }}/5
https://learn.microsoft.com/zh-tw/sql/t-sql/functions/count-transact-sql?view=sql-server-ver16
https://dev.mysql.com/doc/refman/8.0/en/counting-rows.html
可以看到 count(*) 是特別用來計算number of rows的,優化器會特別處理.
而不是 * 就是展開,取所有欄位. 而是 count(*) 本身與 * 都有各自的處理方式.
所以以前會有人以為用了 count(*) 會展開,要使用 count(1) 來減少,
這是很久以前的看法了,也不盡然.
另外,要比對不同SQL的效能,要注意到 cache, 有時候第二道SQL效能本身並沒有比較好,
但是第一道先跑,資料進了cache,第二道就好像比較快. CPU時間=0,有沒有覺得驚喜.
至於怎樣清理cache,在此就不展開了.
Microsoft SQL Server Management Studio,這只是介面,不是DB.
要先分清楚.

Google 到這篇的寫法蠻有趣的
不知道小雨大看法如何
select 10 * count(*) from wsh_exceptions sample block (10)
Oracle 可以使用 Hint , 例如這裡有展示的 /*+ parallel */
或者這個取 sample(10) 這是10%, 然後乘10.
這招不是很好,因為有些資料庫 在取 sample 時, 跟預期的數量會差很多,時常會有驚喜.我就不明說是哪一家的產品了.以免破壞了城裡面的祥和.
其實我以前有問過一次怎樣count大的table,不過大家沒什麼反應.
有些情境是不需要絕對精確.我說的大的table當然不會是某些人的
百萬筆balabala,很久沒看到他了.
改天再寫些例如使用布隆過濾器之類的分享.
基本上還是跟 sql 優化器有關吧
因為有些資料庫 在取 sample 時, 跟預期的數量會差很多,時常會有驚喜
這讓我聯想起在Google時有人回覆的答案是我們應該思考為什麼要select count(x) from table 以及為什麼要討論這個問題
https://ithelp.ithome.com.tw/questions/10193112
以前的問答,可以參考一下.
ChatGPT 這麼說:
這幾個 SQL 指令的主要功能是用來計算符合條件的資料筆數,但它們的使用方式略有不同。
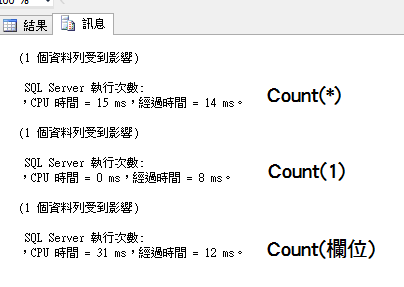
count(*):會計算資料表中所有的資料筆數,包括重複的和 NULL 值。這個指令通常會比其他三個指令更有效率,因為它不需要對任何欄位進行運算。
count(0) 和 count(1):這兩個指令會對指定的欄位進行運算,但它們都不是很有效率,因為它們只是在計算值為 0 或 1 的欄位數量而已。
count(行列):這個指令會對指定的行列進行運算,它會計算指定的行列中所有不是 NULL 值的資料筆數。這個指令會比 count(0) 和 count(1) 更有效率,因為它只是在計算特定欄位中有值的資料筆數而已。
總體而言,count(*) 是最有效率的指令,因為它不需要對任何欄位進行運算,且通常也是最符合需求的指令。但是在特定情況下,使用其他的指令可能會更加合適,例如當只需要計算特定欄位的非 NULL 值的數量時,可以使用 count(行列)。
有待 SQL 大師解惑....
之前在MYSQL5的時候。曾經被高手唸過
count(欄位名)算是效率最好的。不過欄位特性也會影響效率。
基本上是主鍵的欄位名是最好。其次是帶索引的。
count(*)是效能比較不好的。
count(1)則聽說是再搭配有JOIN時。會比較差。沒搭配的話會比較好。
不過這個我是沒在用。
但聽說MYSQL8有針對這部份做優化過。我是還沒時間去驗証就是了。
我個人目前都是沒用JOIN的用欄位主鍵。有用JOIN的還是會用星號。
但自從用ORM就沒在理它用啥了。反正count()就出來了。
不過我映像中,ORM好像是用主鍵來COUNT。
不過畢竟ORM不太有JOIN。所以我想用主鍵也是理所當然的。