我個人目前用Python寫的是有關於噪聲辨識的程式,但本人是新手不知道該如何下手目前已能將音頻轉換成WAV並且自動切割時長(15秒分割一次)並做FFT轉換,然後我就卡住了。我想用下圖的輸出圖來做音頻的圖像辨識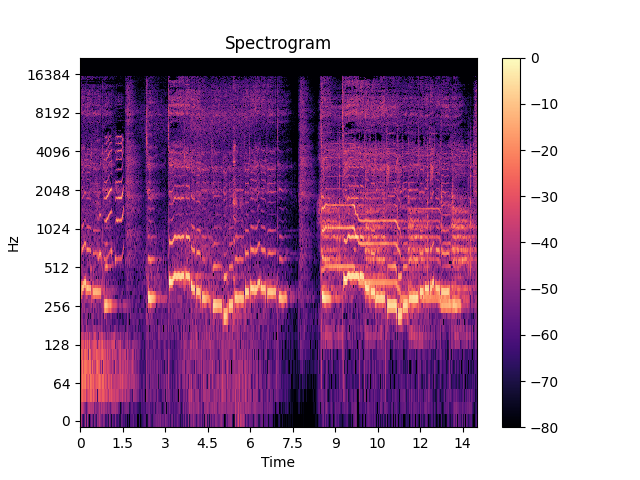
現在遇到的問題是若有一段音頻長達三分鐘,意思是分割並轉換的圖像將會有很多,如下圖所示
目前我已經有很多聲音源當資料庫,我需要知道要如何把同一筆資料做分割後的逐一比對並辨識圖像,並能夠輸出辨識結果。
(備註:本人使用的編輯器是Visual Studio Code)
已邀請的邦友 {{ invite_list.length }}/5
可轉為MFCC或fBank,參閱【Day 25:自動語音識別(Automatic Speech Recognition) -- 觀念與實踐】。
