
Neural Networks 在影像、文字、語音等自然使用者介面(NUI)處理有突破性的發展,之前我們已經見證過影像及文字的辨識威力了,從這一篇開始,我們要開始見識『自動語音識別』(Automatic Speech Recognition)方面的發展。
人類講話的聲音可以以『示波器』(Oscilloscope)測量成一個隨時間變化的波形信號,這種信號對時間的關係,稱之為『時域』(Time Domain),在電腦對信號進行分析時,通常信號會先被轉換成在不同頻率下對應的振幅及相位,稱之為『頻域』(frequency domain),轉換的公式稱為『傅立葉變換』(Fourier transform),信號經過每隔一段時間取樣,就得到可以進行分析的數位音檔,附檔名通常是 wav。
根據 Nyquist 定理,如果想要從數位信號無損轉到類比信號,我們需要以最高信號頻率的2倍的採樣頻率進行採樣。通常人的聲音的平率大概在3kHz~4kHz ,因此語音辨識通常使用8k或者16k的wav提取特徵。例如,16kHz取樣速率的音訊,經『傅立葉變換』後的頻率範圍為0-8KHz。
-- 節錄自 Kaldi特征提取之-FBank
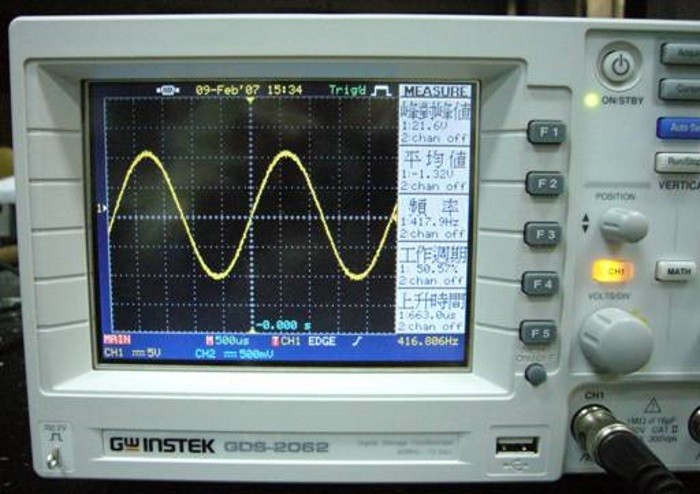
圖. 『示波器』(Oscilloscope),圖片來源:國立臺灣大學普通物理實驗室
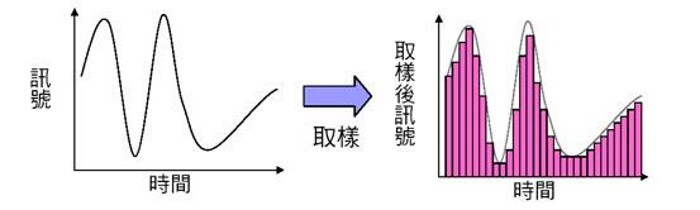
圖. 聲音取樣,圖片來源:國立臺灣大學普通物理實驗室
為了方便作語音辨識,與影像一樣,我們會對語音作特徵抽取(Feature Extraction),目前有 FBank、MFCC(Mel frequency cepstral coefficients) 兩種,特徵抽取前須先對聲音作前置處理:

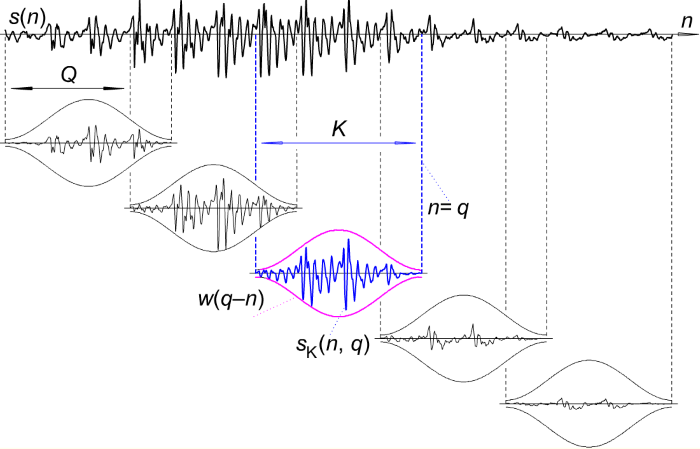
圖. Windowing and frame formation,圖片來源:Preprocessing
FBank相鄰的特徵高度相關(相鄰濾波器組有重疊),需要進行倒譜轉換,通過這樣得到MFCC特徵。MFCC具有更好的判別度,大多數語音辨識論文中用的是MFCC。
-- 節錄自 kaldi之fbank和mfcc特征提取
有了以上的初步概念,我們先以一個簡單範例,揭開語音辨識的序幕。這個範例主要是根據一些事先標註的語音檔,辨識我們輸入的語音是哪一個單字? 範例的標註資料共有 bed、cat、happy 三個單字,分別有幾百個高低音的檔案,實作的方式,我們很熟悉,採CNN,流程如下:
程式碼來自『Building a Dead Simple Speech Recognition Engine using ConvNet in Keras』,我加了一些註解,也可至這裡下載,範例在 SpeechRecognition 資料夾,主程式為 SpeechRecognition.py 如下:
# 導入函式庫
from preprocess import *
import keras
from keras.models import Sequential
from keras.layers import Dense, Dropout, Flatten, Conv2D, MaxPooling2D
from keras.utils import to_categorical
# 載入 data 資料夾的訓練資料,並自動分為『訓練組』及『測試組』
X_train, X_test, y_train, y_test = get_train_test()
X_train = X_train.reshape(X_train.shape[0], 20, 11, 1)
X_test = X_test.reshape(X_test.shape[0], 20, 11, 1)
# 類別變數轉為one-hot encoding
y_train_hot = to_categorical(y_train)
y_test_hot = to_categorical(y_test)
print("X_train.shape=", X_train.shape)
# 建立簡單的線性執行的模型
model = Sequential()
# 建立卷積層,filter=32,即 output size, Kernal Size: 2x2, activation function 採用 relu
model.add(Conv2D(32, kernel_size=(2, 2), activation='relu', input_shape=(20, 11, 1)))
# 建立池化層,池化大小=2x2,取最大值
model.add(MaxPooling2D(pool_size=(2, 2)))
# Dropout層隨機斷開輸入神經元,用於防止過度擬合,斷開比例:0.25
model.add(Dropout(0.25))
# Flatten層把多維的輸入一維化,常用在從卷積層到全連接層的過渡。
model.add(Flatten())
# 全連接層: 128個output
model.add(Dense(128, activation='relu'))
model.add(Dropout(0.25))
# Add output layer
model.add(Dense(3, activation='softmax'))
# 編譯: 選擇損失函數、優化方法及成效衡量方式
model.compile(loss=keras.losses.categorical_crossentropy,
optimizer=keras.optimizers.Adadelta(),
metrics=['accuracy'])
# 進行訓練, 訓練過程會存在 train_history 變數中
model.fit(X_train, y_train_hot, batch_size=100, epochs=200, verbose=1, validation_data=(X_test, y_test_hot))
X_train = X_train.reshape(X_train.shape[0], 20, 11, 1)
X_test = X_test.reshape(X_test.shape[0], 20, 11, 1)
score = model.evaluate(X_test, y_test_hot, verbose=1)
# 模型存檔
from keras.models import load_model
model.save('ASR.h5') # creates a HDF5 file 'model.h5'
# 預測(prediction)
mfcc = wav2mfcc('./data/happy/012c8314_nohash_0.wav')
mfcc_reshaped = mfcc.reshape(1, 20, 11, 1)
print("labels=", get_labels())
print("predict=", np.argmax(model.predict(mfcc_reshaped)))
程式檔有兩個,SpeechRecognition.py及preprocess.py,前者為主程式,後者為公用函數,供主程式呼叫,執行時需要資料檔,請至這裡下載,將data資料夾與程式放置在同一目錄即可。
執行前必須先安裝及升級以下套件(Package):
pip install librosa
pip install NumBa -U
在DOS內執行以下指令:
python SpeechRecognition.py
執行結果如下,『2』代表辨識為『happy』,結果正確。
這個範例只辨識 bed、cat、happy 三個單字,你可以加入更多的單字作訓練資料,只要放入不同的資料夾,程式完全不用改變,甚至放入中文詞檔,應該也沒有問題,因為程式只是辨識頻率,它根本分不清楚是哪一種語言。
原部落文已下架,請至這裡下載,檔案放在 SpeechRecognition 目錄下。
您好
關於此範例您所提供的網址似乎是找不到資料檔的部分(可能被回收了), 不知道能否提供模型存檔的部分ASR.h5可供參考呢?或者是training結束後所得到的weight, 因為想要直接試試看預測的部分run起來是如何, 還是大大也有保留從前資料檔的部分可以讓我範例程式可以成功執行? 感謝您的幫忙
非常感謝~!
你好 我想請問一下導入函式庫這行from preprocess import
有錯誤:ImportError: No module named 'preprocess'
是甚麼問題呢
你少複製一個檔案至目前目錄:preprocess.py
感謝,導入函式庫這個部分已經解決了
不過遇到新的問題
在進行載入Data資料夾:X_train, X_test, y_train, y_test = get_train_test()這行的時候有出現下列的錯誤
File "", line 1, in
File "C:\Users\user\Anaconda3\envs\tensorflow\preprocess.py", line 47, in get_train_test
X = np.load(labels[0] + '.npy')
File "C:\Users\user\Anaconda3\envs\tensorflow\lib\site-packages\numpy\lib\npyio.py", line 372, in load
fid = open(file, "rb")
FileNotFoundError: [Errno 2] No such file or directory: 'bed.npy'
是我載的資料夾有放錯位置,還是少放甚麼嗎
原部落文已下架,請至下列網址下載: https://github.com/mc6666/MyNeuralNetwork
檔案放在 SpeechRecognition 目錄下。
您好,現在想請問說如果我要多新增辨別不同的單字,直接在data資料夾裡面新增了單字的資料夾,那對應的npy檔案要怎麼辦?
preprocess.py 裡面有個 save_data_to_array 函數可將目錄內的wav 檔全部轉成一個npy檔
想請問一下 用自己的錄好的聲音檔去做預測
在執行mfcc = wav2mfcc('./data/happy/012c8314_nohash_0.wav')這行時會跑出
(檔案有改為我自己要預測的檔案)
Traceback (most recent call last):
File "", line 1, in
File "C:\Users\user\preprocess.py", line 24, in wav2mfcc
mfcc = np.pad(mfcc, pad_width=((0, 0), (0, pad_width)), mode='constant')
File "<array_function internals>", line 6, in pad
File "C:\Users\user\Anaconda3\envs\tensorflow\lib\site-packages\numpy\lib\arraypad.py", line 793, in pad
pad_width = _as_pairs(pad_width, array.ndim, as_index=True)
File "C:\Users\user\Anaconda3\envs\tensorflow\lib\site-packages\numpy\lib\arraypad.py", line 564, in _as_pairs
raise ValueError("index can't contain negative values")
ValueError: index can't contain negative values
只有用訓練資料的檔案才能正常運作 為什麼呢
該程式是以短指令的方式辨識,在wav2mfcc轉換時可能有限制,我有改過原版程式如下,但效果不是很好。
def wav2mfcc(file_path, max_pad_len=11):
wave, sr = librosa.load(file_path, mono=True, sr=None)
wave = wave[::3]
# michael added to cut my audio file
i=0
# 訓練資料的長度
wav_length=5334
# 聲音檔過長,擷取片段
if len(wave) > wav_length:
# 尋找最大聲的點,取前後各半
i=np.argmax(wave)
if i > (wav_length):
wave = wave[i-int(wav_length/2):i+int(wav_length/2)]
else:
# 聲音檔過長,取前面
wave = wave[0:wav_length]
mfcc = librosa.feature.mfcc(wave, sr=16000)
pad_width = max_pad_len - mfcc.shape[1]
if pad_width < 0:
pad_width = 0
mfcc = mfcc[:,:11]
mfcc = np.pad(mfcc, pad_width=((0, 0), (0, pad_width)), mode='constant')
return mfcc
您好
關於此範例您所提供的網址似乎是找不到資料檔的部分(可能被回收了), 不知道能否提供以供訓練呢?謝謝您
您好 如果要製作新的database, 除了自己錄音以外,還有什麼方法可以製作嗎?
可以看看現成的資料集,是否剛好符合你的需求:
https://towardsdatascience.com/a-data-lakes-worth-of-audio-datasets-b45b88cd4ad
你好 我遇到了一些問題不知道如何解決
依據大量的聲音數據去做訓練 那可以做非人聲的訓練嗎
懇求Code大幫忙
File "d:/Python/voice/DeadSimpleSpeechRecognizer-master/SpeechRecognition.py", line 9, in
X_train, X_test, y_train, y_test = get_train_test()
File "d:\Python\voice\DeadSimpleSpeechRecognizer-master\preprocess.py",
line 56, in get_train_test
X = np.load(labels[0] + '.npy')
File "D:\Anaconda\lib\site-packages\numpy\lib\npyio.py", line 428, in load
fid = open(os_fspath(file), "rb")
FileNotFoundError: [Errno 2] No such file or directory: 'bed.npy'
請至這裡下載,檔案放在 SpeechRecognition 目錄下。
可以做非人聲的訓練嗎 ==> 可以,模型是依據音頻建立的,並非真的作語意判別。
檔案是指data的資料夾要放在 SpeechRecognition 目錄底下
然後DATA_PATH的路徑要改嗎
因為我還是遇到一樣的問題
還是因為我沒有接麥克風
感謝提點~已解決
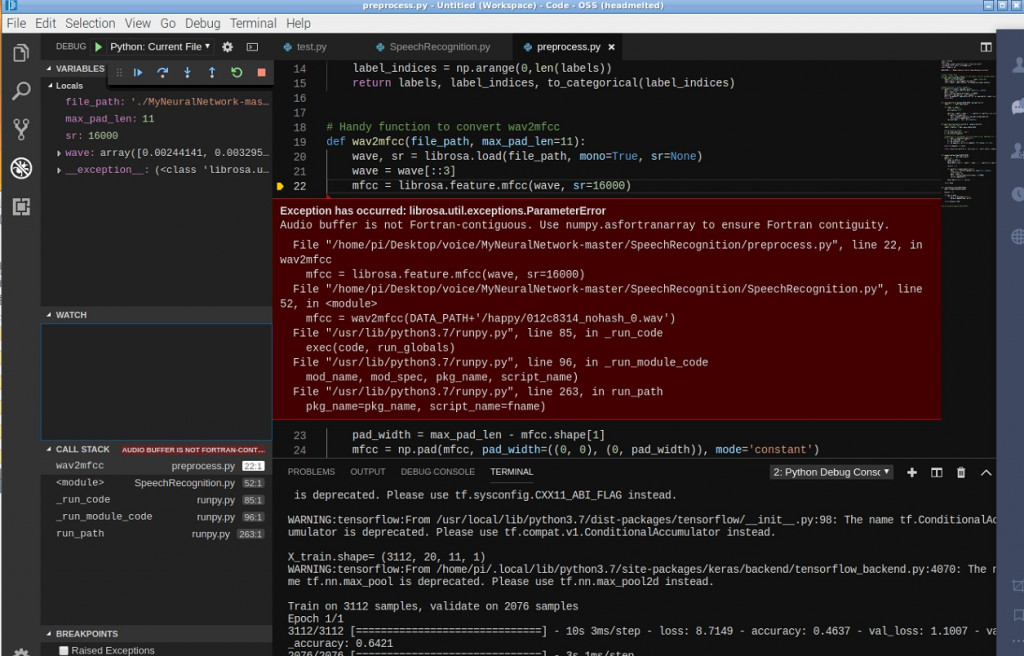
遇到了這個問題 不知如何解決 請求版主幫忙..
找到解決的方法了
def wav2mfcc(file_path, max_pad_len=11):
wave, sr = librosa.load(file_path, mono=True, sr=None)
print(wave)
wave =np.ascontiguousarray(wave[::-1])
mfcc = librosa.feature.mfcc(wave,sr=16000)
pad_width = max_pad_len - mfcc.shape[1]
if pad_width < 0:
pad_width = 0
mfcc = mfcc[:,:11]
mfcc = np.pad(mfcc, pad_width=((0, 0), (0, pad_width)), mode='constant')
return mfcc)
要做一個及時的語音辨識要如何進行呢
您好,我用自己錄製好的聲音檔並用ave_data_to_array轉成npy檔時有遇到問題
有成功轉過其他地方載的database,只是不知道為什麼自己錄製的就不行~
請問是甚麼問題呢?
該程式是以短指令的方式辨識,在wav2mfcc轉換時可能有限制,我有改過原版程式如下,但效果不是很好。
def wav2mfcc(file_path, max_pad_len=11):
wave, sr = librosa.load(file_path, mono=True, sr=None)
wave = wave[::3]
# michael added to cut my audio file
i=0
# 訓練資料的長度
wav_length=5334
# 聲音檔過長,擷取片段
if len(wave) > wav_length:
# 尋找最大聲的點,取前後各半
i=np.argmax(wave)
if i > (wav_length):
wave = wave[i-int(wav_length/2):i+int(wav_length/2)]
else:
# 聲音檔過長,取前面
wave = wave[0:wav_length]
mfcc = librosa.feature.mfcc(wave, sr=16000)
pad_width = max_pad_len - mfcc.shape[1]
if pad_width < 0:
pad_width = 0
mfcc = mfcc[:,:11]
mfcc = np.pad(mfcc, pad_width=((0, 0), (0, pad_width)), mode='constant')
return mfcc
File "SpeechRecognition.py", line 52, in <module>
mfcc = wav2mfcc('./data/happy/012c8314_nohash_0.wav')
File "C:\Users\user\Desktop\音頻測試\MyNeuralNetwork-master\SpeechRecognition\preprocess.py", line 23, in wav2mfcc
mfcc = librosa.feature.mfcc(wave, sr=16000)
File "C:\Users\user\AppData\Local\Programs\Python\Python35\lib\site-packages\librosa\feature\spectral.py", line 1692, in mfcc
S = power_to_db(melspectrogram(y=y, sr=sr, **kwargs))
File "C:\Users\user\AppData\Local\Programs\Python\Python35\lib\site-packages\librosa\feature\spectral.py", line 1817, in melspectrogram
pad_mode=pad_mode)
File "C:\Users\user\AppData\Local\Programs\Python\Python35\lib\site-packages\librosa\core\spectrum.py", line 2528, in _spectrogram
window=window, pad_mode=pad_mode))**power
File "C:\Users\user\AppData\Local\Programs\Python\Python35\lib\site-packages\librosa\core\spectrum.py", line 215, in stft
util.valid_audio(y)
File "C:\Users\user\AppData\Local\Programs\Python\Python35\lib\site-packages\librosa\util\utils.py", line 278, in valid_audio
raise ParameterError('Audio buffer is not Fortran-contiguous. '
librosa.util.exceptions.ParameterError: Audio buffer is not Fortran-contiguous. Use numpy.asfortranarray to ensure Fortran contiguity.
抱歉 想詢問 大大 我照著 步驟做 但是 卻出現 以下錯誤 是因為 librosa版本問題嗎?
想問一下大大能否有能讓我直接 RUN的範例 感謝
我執行沒有出現問題,本機的版本是 0.6.2。
你可以執行 pip install librosa==0.6.2 試試看。
evalue : [0.2773901812592252, 0.9426782131195068]
labels= (['bed', 'cat', 'happy'], array([0, 1, 2]), array([[1., 0., 0.],
[0., 1., 0.],
[0., 0., 1.]], dtype=float32))
predict= 1
結果出來 在 predict 顯示 是2
而且我必須把
def wav2mfcc(file_path, max_len=11):
wave, sr = librosa.load(file_path, mono=True, sr=None)
** #wave = wave[::3]**// 這段 給刪掉才能 進行
mfcc = librosa.feature.mfcc(wave, sr=16000)
# If maximum length exceeds mfcc lengths then pad the remaining ones
if (max_len > mfcc.shape[1]):
pad_width = max_len - mfcc.shape[1]
mfcc = np.pad(mfcc, pad_width=((0, 0), (0, pad_width)), mode='constant')
# Else cutoff the remaining parts
else:
mfcc = mfcc[:, :max_len]
return mfcc
您好,想請問怎麼產生bed cat happy的 .npy檔
在preprocess中有save_data_to_array(path=DATA_PATH, max_pad_len=11):這個function可以用,可是將存放traing data資料夾的路徑打上去後卻沒辦法成功
想問大大是怎用甚麼方法產生的呢?
save_data_to_array的path,還有一層子目錄label,說明樣本的實際答案,例如cat、bed、...。
save_data_to_array內第6行:
wavfiles = [path + label + '/' + wavfile for wavfile in os.listdir(path + '/' + label)]
您好,請問這適合可以換data做情緒辨識嗎?
例如data換成開心的語音、生氣的語音,等等。
應該適合,可以試試看。
版主你好,請教你幾個問題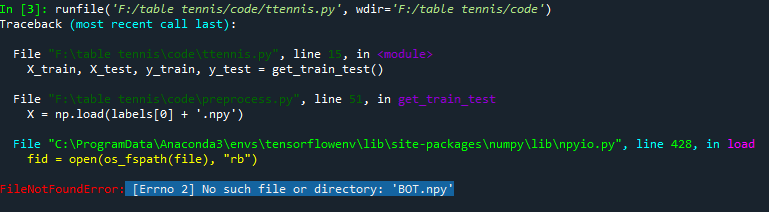
我遇到第一張圖片的問題,我有看到其他人也問相同問題,但我還是沒有解決,我是套用我的DATA,我的程式是放在code資料夾,DATA資料夾也是放在code資料夾裡,不知道這樣放有沒有錯,上面是我修改的路徑還有我資料夾的截圖。不小心發問在別篇抱歉
範例使用 https://github.com/mc6666/MyNeuralNetwork/blob/master/SpeechRecognition/preprocess.py 中的 save_data_to_array 函數,將DATA資料夾存成 npy 檔,以利後續反覆測試時可快速讀取資料。
你應該是漏了這個步驟。
謝謝 問題解決了 我把save_data_to_array(max_len=11)貼到主程式就可以了
讚 !
版主您好,我想請教您幾個問題
我用jupyter執行您的程式碼時發生了以下錯誤
FileNotFoundError: [Errno 2] No such file or directory: 'mini_speech_commands.zip.npy'
想問怎麼解決
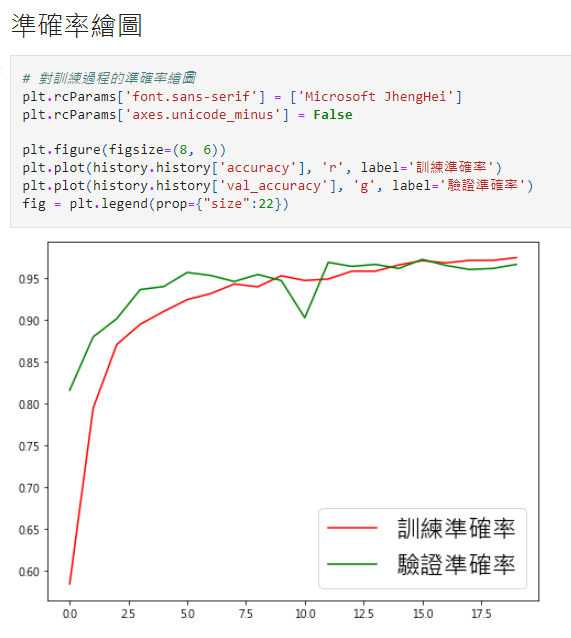
我想詢問準確率繪圖的橫軸表示什麼?
最後這張圖的橫軸跟縱軸是甚麼意思 其實我有點看不懂 抱歉我剛入門
他的訓練資料要怎麼下載
準確率繪圖的橫軸是訓練的執行週期。
最後一張圖好像不在文章中?
最後一張圖是 MFCC 的值。


