各位前輩好,首次在iT邦發文,希望可以獲得iT邦的神之力。
連結: 玩股網法人買賣超排行
問題: 小弟,目前在做大數據分析,以Python程式解析網頁中含有Javascript的動態網頁原始碼,我找過許多網站,這個網站的資訊比較完整且好用,首次就拿玩股網的買賣超排行開刀。
由於連結的網頁原始碼是JS程式,就直接跳過原始碼的部分,來開發人員模式(F12),[網路]-[Ctrl+R] 先重新讀取網頁資料,找到網頁中的XHR請求,從請求名稱可以找到與之相關的名稱,如圖所示!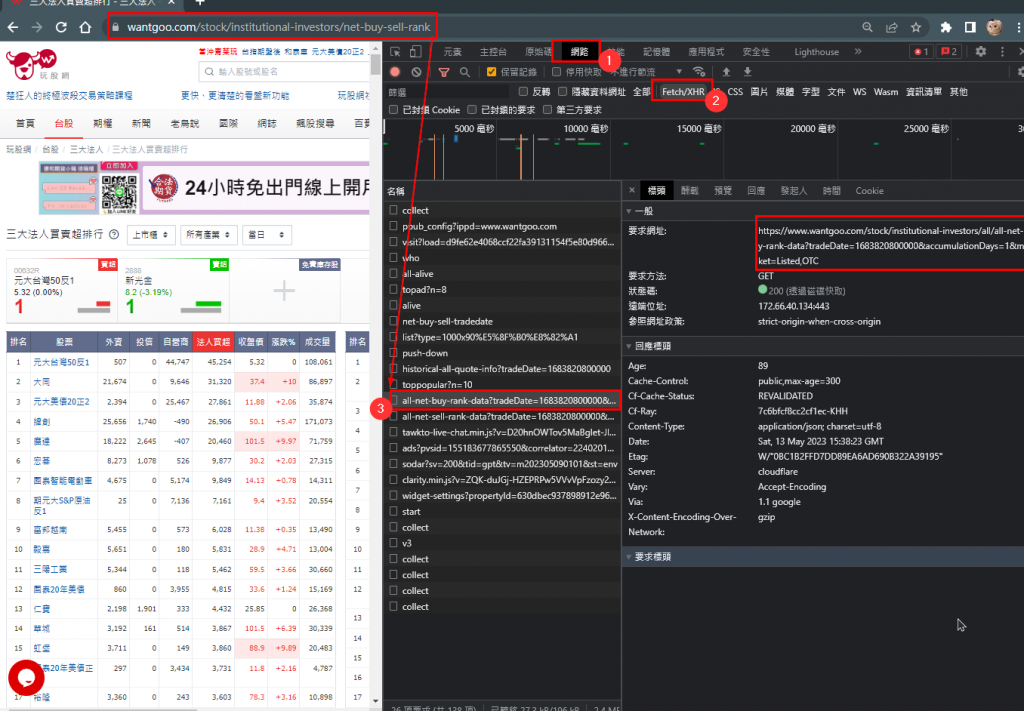
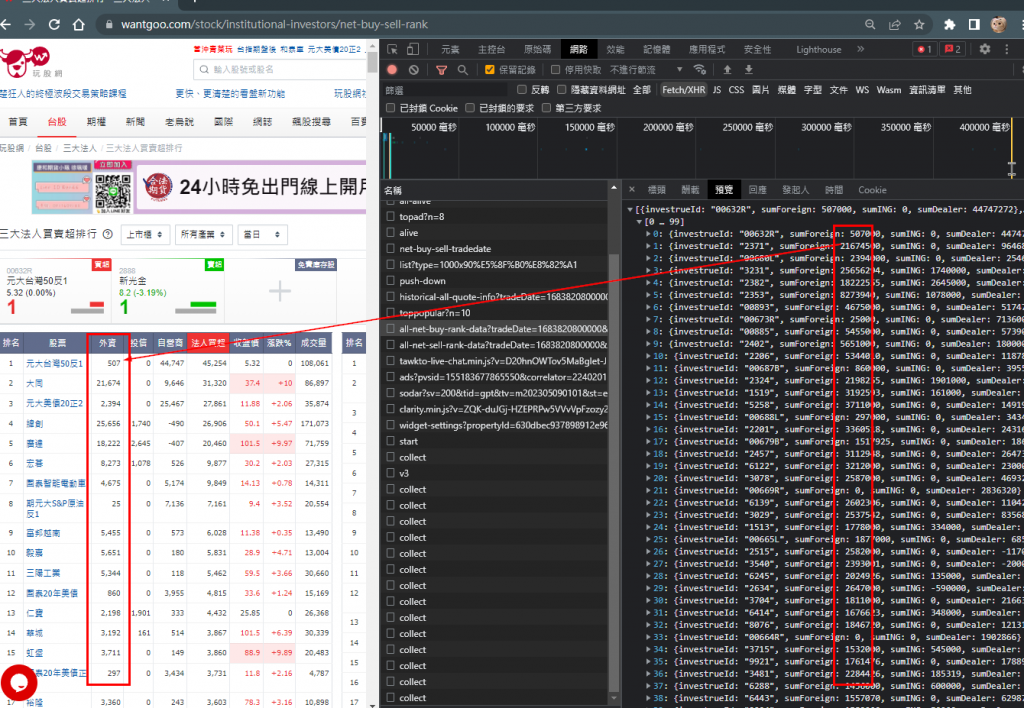
從右邊得連結要求網址,可以獲取json格式的原始碼,如下圖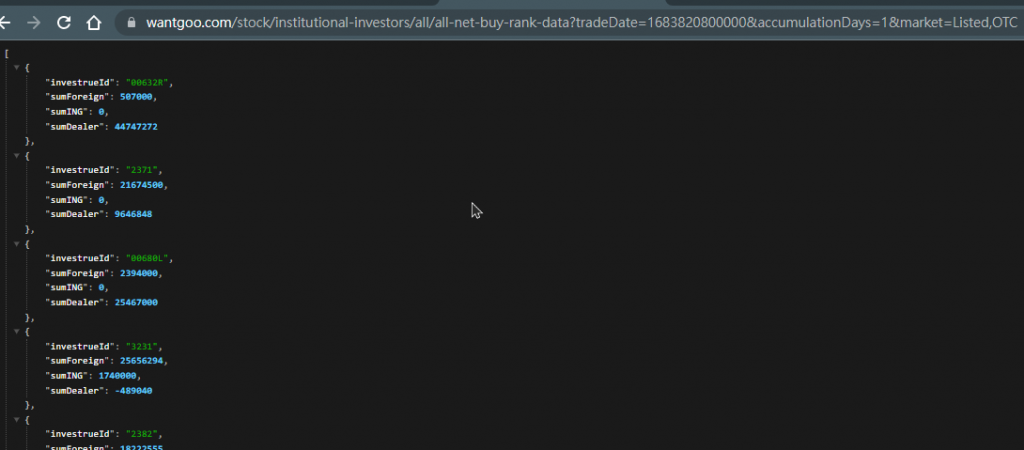
但網站似乎有限制timeout,一段時間後就會回傳 400-BadRequest 的錯誤,請教要做這個網頁的爬蟲程式碼要如何做才可以做到以下這種效果。
1.將爬蟲tmp_url設為 玩股網法人買賣超排行
2.將每次執行tmp_url 自動取得上方xhr網址,再利用request了將html原碼加以做解析。
解析的部分我可以自己解決,唯獨上方產生的xhr url 是ajax動態產生的,故還需要再向伺服端請求一次,才會取得json檔案,這邊我就不熟悉了。
是否需要使用到 selenium 才可以實作這樣的程式呢?
已邀請的邦友 {{ invite_list.length }}/5
看你要選 selenium 或 request
selenium 比較間單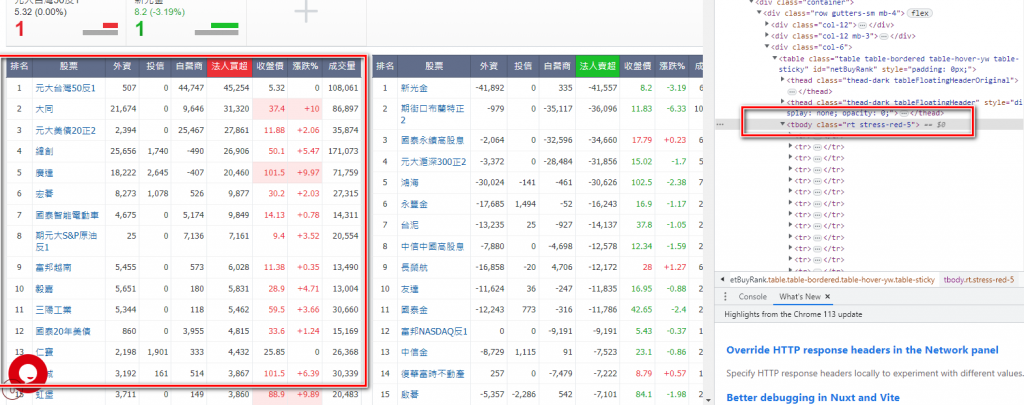
看選到
class="rt stress-red-5" 就有red 那些資料
class="rt stress-green-5" 就有 green 那些資料
這如果網頁變了改程式幅度也比較小
當然拆解 xhr網址 去取資料也可
這比較麻煩, 如果api變了就又要改程式更改的幅度比較大
回應echochio:
話說selenium可能比較簡單,但我試圖使用webdriver.Chrome去瀏覽網址,得到結果如下圖,是不是沒有接到js的資料?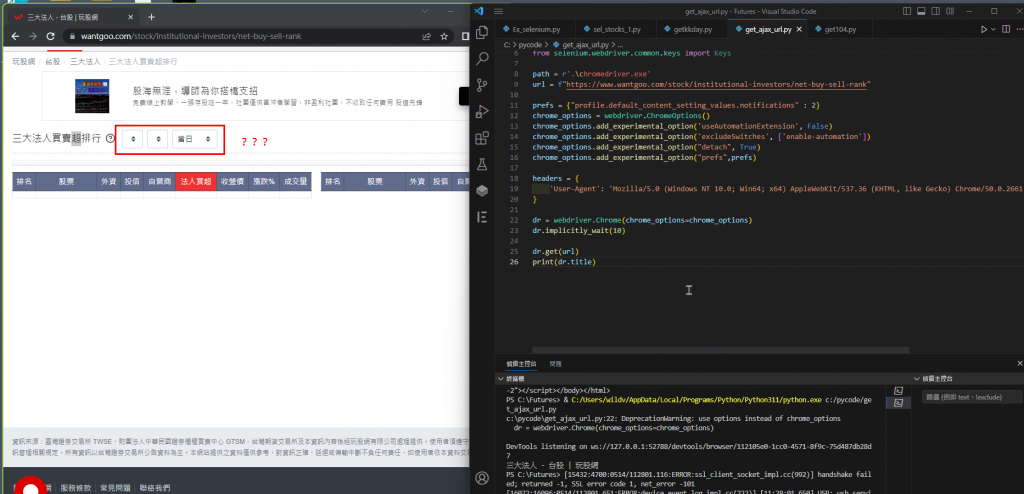
是這樣沒錯, 但網站的api不會說改就改, 也不曉得怎樣才可以取的網頁的所有xhr網址
出國在忙現在才看到那網址有防爬
換 Headers User-Agent Headless 正常都可抓到
可找找
https://www.learncodewithmike.com/2020/09/7-tips-to-avoid-getting-blocked-while-scraping.html
Honeypot Traps 比較難防

 iThome鐵人賽
iThome鐵人賽