各位大大好!小弟最近用python的openpyxl、pandas、numpy這三個模組讀data.xlsx和data2.xlsx檔,遇到瓶頸!! 

這是data.xlsx照片: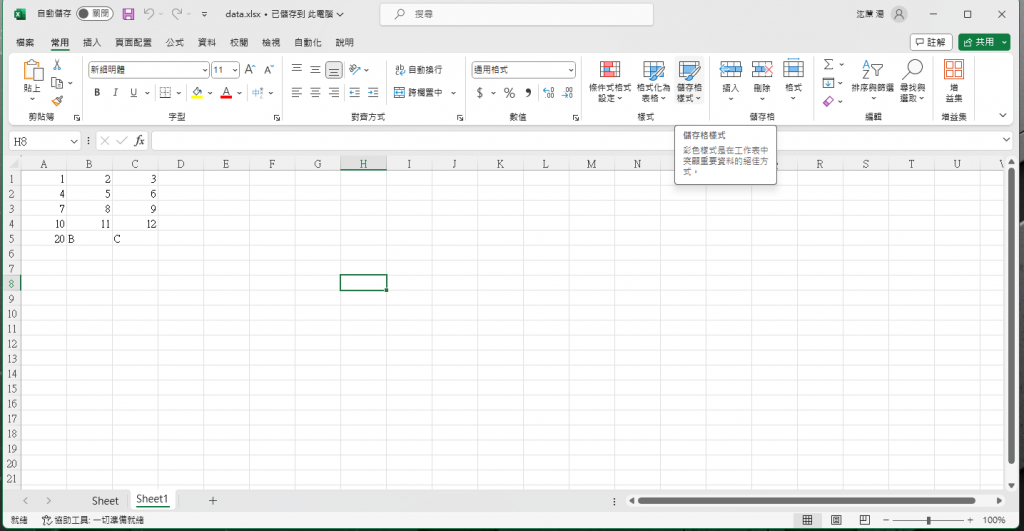
這是data2.xlsx照片: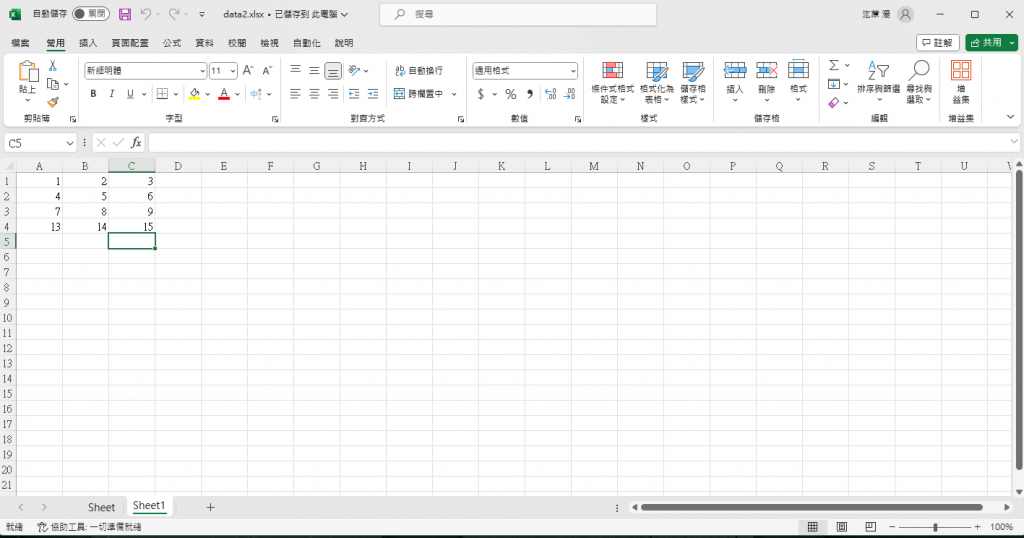
這是我寫的python的程式碼:
import openpyxl
import pandas as pd
import numpy as np
# 讀取第一個 Excel 檔案
wb1 = openpyxl.load_workbook('data.xlsx')
sheet1 = wb1['Sheet1']
# 讀取第二個 Excel 檔案
wb2 = openpyxl.load_workbook('data2.xlsx')
sheet2 = wb2['Sheet1']
# 提取兩個工作表的最大行和最大列
max_row = max(sheet1.max_row, sheet2.max_row)
max_column = max(sheet1.max_column, sheet2.max_column)
# 將 Excel 檔案轉換為 pandas DataFrame
df1 = pd.DataFrame(sheet1.values)
df2 = pd.DataFrame(sheet2.values)
# 找出兩者的差異之處,產生布林 DataFrame
diff_df1 = df1.ne(df2)
diff_df2 = df2.ne(df1)
# 產生最終的差異 DataFrame(兩者都有差異的地方)
final_diff_df = diff_df1 | diff_df2
# 創建新的工作簿
wb3 = openpyxl.Workbook()
sheet3 = wb3.active
# 創建用於存儲結果的 DataFrame
result_df = pd.DataFrame(columns=["原本的欄位1","原本的欄位2","新增的欄位1", "新增的欄位2", "修改的欄位1", "修改的欄位2", "刪除的欄位1", "刪除的欄位2"])
# 用雙層 for 迴圈的方式分別遍歷行和列數據,然後判斷單一格數據的值是否相等
for i in range(1, max_row + 1):
for j in range(1, max_column + 1):
cell_1 = sheet1.cell(i, j)
cell_2 = sheet2.cell(i, j)
if cell_1.value != cell_2.value:
#data = [cell_1.value, cell_2.value]
#sheet3.append(data)
result_df = result_df.append({"原本的欄位1": None, "原本的欄位2": None,
"新增的欄位1": cell_1.value,"新增的欄位2": cell_2.value,
"修改的欄位1": None, "修改的欄位2": None,
"刪除的欄位1": None, "刪除的欄位2": None
}, ignore_index=True)
elif cell_1.value == cell_2.value:
result_df = result_df.append({"原本的欄位1": cell_1.value, "原本的欄位2": cell_2.value,
"新增的欄位1": None,"新增的欄位2": None,
"修改的欄位1": None, "修改的欄位2": None,
"刪除的欄位1": None, "刪除的欄位2": None
}, ignore_index=True)
# 儲存新的 Excel 檔案
wb3.save('data3.xlsx')
# 顯示結果 DataFrame
print(result_df)
# 將結果存儲到 data3.xlsx
result_df.to_excel('data3.xlsx', index=False)
上面python程式碼執行完後的data3.xlsx檔的照片: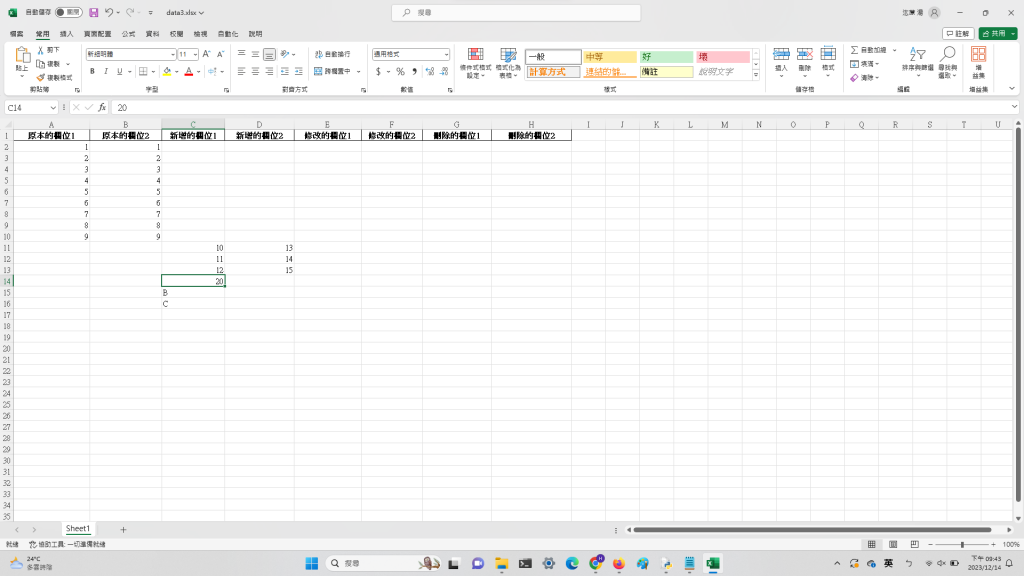
這是我理想的data3.xlsx檔照片: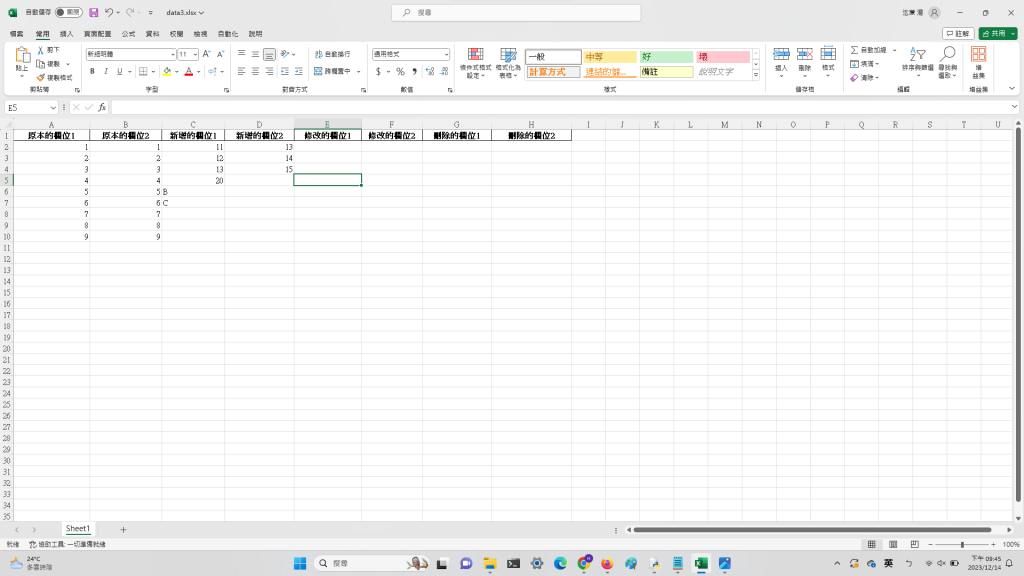
這是我想請教各位大大的問題,我要怎麼修改上述python程式碼,執行完後存到data3.xlsx才能變成自己理想的data3.txt檔照片的排版呢? 
已邀請的邦友 {{ invite_list.length }}/5
參考
共通部分
# 用雙層 for 迴圈的方式分別遍歷行和列數據,然後判斷單一格數據的值是否相等
o1 = []
o2 = []
a1 = []
a2 = []
for i in range(1, max_row + 1):
for j in range(1, max_column + 1):
cell_1 = sheet1.cell(i, j)
cell_2 = sheet2.cell(i, j)
if cell_1.value != cell_2.value:
a1.append(cell_1.value)
a2.append(cell_2.value)
elif cell_1.value == cell_2.value:
o1.append(cell_1.value)
o2.append(cell_2.value)
方法一
Add columns of a different Length to a DataFrame in Pandas
s_dict = {
"原本的欄位1": o1,
"原本的欄位2": o2,
"新增的欄位1": a1,
"新增的欄位2": a2,
}
result_df = pd.DataFrame(
dict(
[(key, pd.Series(value))
for key, value in s_dict.items()]
)
)
方法二
How to Fix: Length of values does not match length of index
result_df["原本的欄位1"] = pd.Series(o1)
result_df["原本的欄位2"] = pd.Series(o2)
result_df["新增的欄位1"] = pd.Series(a1)
result_df["新增的欄位2"] = pd.Series(a2)
