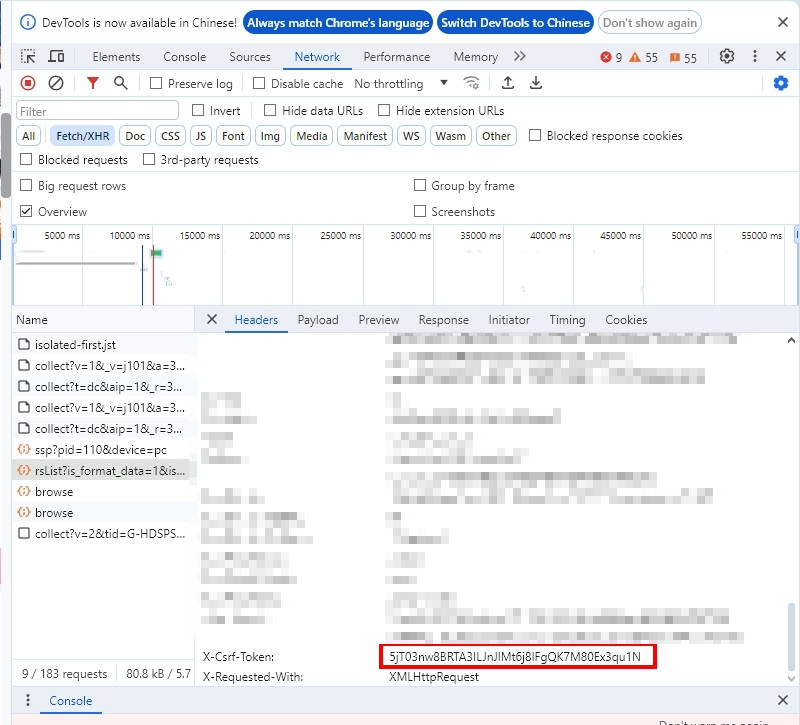
小弟最近在練習用python爬取591的資訊,但怎麼找都找不到X-CSRF-TOKEN,想請問各位大神該如何解決?
以下是程式碼,我是參考 https://blog.jiatool.com/posts/house591_spider/ 這篇文章
參考架構並學習
import requests
import json
import time
import random
import re
from bs4 import BeautifulSoup
class rent591():
def __init__(self):
self.headers = {
'User-Agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.0.0 Mobile Safari/537.36',
}
def search(self, filter_p=None, sort_p=None, the_page=1):
total_count = 0
house_list = []
page = 0
s = requests.Session()
url = 'https://rent.591.com.tw/'
r = s.get(url, headers=self.headers)
soup = BeautifulSoup(r.text, 'html.parser')
token_item = soup.select_one('meta[name="csrf-token"]')
headers = self.headers.copy()
headers['X-CSRF-TOKEN'] = token_item.get('content')
# search house
url = 'https://rent.591.com.tw/home/search/rsList'
params = 'is_format_data=1&is_new_list=1&type=1'
if filter_p:
params += ''.join([f'&{key}={value}' for key,
value, in filter_p.items()])
else:
params += '®ion=8&kind=0'
s.cookies.set('urlJumpIp', filter_p.get('region', '8')
if filter_p else '8', domain='.591.com.tw')
if sort_p:
params += ''.join([f'&{key}={value}' for key,
value, in sort_p.items()])
while page < the_page:
params += f'&firstRow={page*30}'
r = s.get(url, params=params, headers=headers)
if r.status_code != requests.codes.ok:
print("opps, there's a problem", r.status_code)
break
page += 1
data = r.json()
total_count = data['records']
house_list.extend(data['data']['data'])
time.sleep(random.uniform(2, 5))
return total_count, house_list
def house_detail(self, house_id):
s = requests.Session()
url = f'https://rent.591.com.tw/home/{house_id}'
r = s.get(url, headers=self.headers)
soup = BeautifulSoup(r.text, 'html.parser')
token_item = soup.select_one('meta[name="csrf-token"]')
headers = self.headers.copy()
headers['X-CSRF-TOKEN'] = token_item.get('content')
headers['deviceid'] = s.cookies.get_dict()['T591_TOKEN']
headers['device'] = 'pc'
url = f'https://bff.591.com.tw/v1/house/rent/detail?id={house_id}'
r = s.get(url, headers=headers)
if r.status_code != requests.codes.ok:
print("opps, there's a problem", r.status_code)
return
house_detail = r.json()['data']
return house_detail
if __name__ == "__main__":
houserent_591 = rent591()
filter_p = {
'region': '8',
'kind': '0',
'multiPrice': '5000_10000',
'keywords': '%E7%A6%8F%E4%B8%8A%E5%B7%B7',
'section': '104',
'searchtype': '1'
# 'showMore': '1',
}
sort_p = {
'order': 'posttime',
'orderType': 'desc'
}
total_count, houses = houserent_591.search(
filter_p, sort_p, the_page=1)
print('totalnumber: ', total_count)
house_detail = houserent_591.house_detail(houses[0]['post_id'])
print(house_detail)
執行後會顯示
已邀請的邦友 {{ invite_list.length }}/5
The challenges in developing a web crawler for the 591 housing platform in Python, especially in locating the X-CSRF-TOKEN, which is crucial to performing difficult levels in basket random and requires success where accuracy is key.

 iThome鐵人賽
iThome鐵人賽