各位大大好!
想詢問關於一些關於爬蟲的問題
之前有做關於IG的爬蟲,然而最近可能IG有改版導致那隻爬蟲不能使用了,
但遇到了一些困擾,上網找也找不太到相符合的資料,所以上來發文問各位大大,
我所需要的資料在F12->Network中 "https://www.instagram.com/api/graphql" 這個網址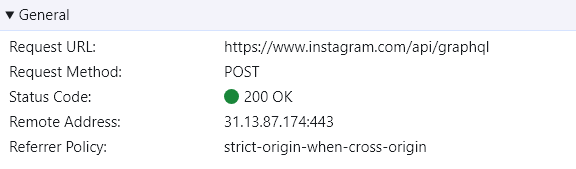
所需資料
但在Network中有許多相同網址,代表他所帶的payload都不同,得出不同的資料,
但在處理好headers(其中cookie是抓取電腦上登入IG後的cookie)和payload後,post後也成功response 200,但卻得到一個HTML
而我使用request.url獲得我目前網址前往查看,抓下來的確實是其中的HTML,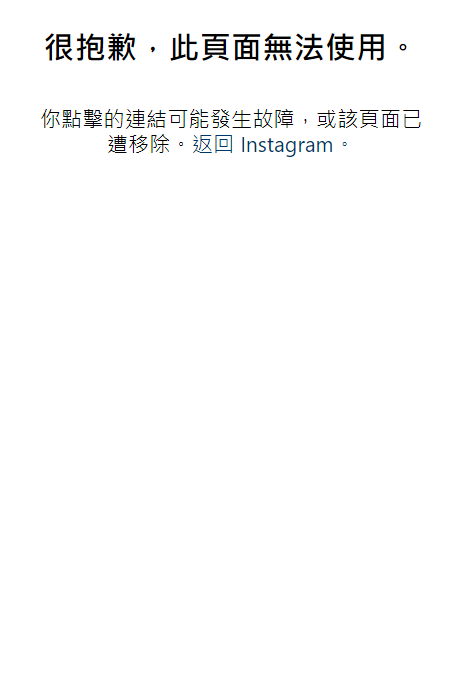
想詢問各位大大這部分的如何使用 requests 去解決呢?
或是問題可能可以往哪裡去處理呢?
非常抱歉目前想說給自己挑戰只使用requests解決,所以想詢問各位大大
程式碼:
import requests
import json
url = f'https://www.instagram.com/api/graphql'
payload = {
'av':fbid,
'variables':{"data":{"count":12,"include_relationship_info":True,"latest_besties_reel_media":True,"latest_reel_media":True},"username":f"{user}","__relay_internal__pv__PolarisShareMenurelayprovider":False},
'__d':'www',
'__user': '0',
'__a': '1',
'__req': '2',
'__hs': '19797.HYP:instagram_web_pkg.2.1..0.1',
'dpr': '1.5',
'__ccg': 'UNKNOWN',
'__rev': f'{rev[0]}',
'__s': '4bty40:w41dwq:jbfeh4',
'__hsi': f'{hsi[0]}',
'__dyn': 'xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx',
'__csr': 'xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx',
'__comet_req': '7',
'fb_dtsg': f'{token[0]}',
'jazoest': f'{jazoest}',
'lsd': f'{lsd[0]}',
'__spin_r': f'{rev[0]}',
'__spin_b': 'trunk',
'__spin_t': f'{spin_t[0]}',
'fb_api_caller_class': 'RelayModern',
'fb_api_req_friendly_name': 'PolarisProfilePostsQuery',
'server_timestamps': True,
'doc_id': f'{doc_id}'
}
payload = json.dumps(payload)
request = requests.post(url,headers={
'cookie':f'ig_did={ig_did}; ig_nrcb=1;datr=xxxxxxxxxxxx;fbm_{fbm}=base_domain=.instagram.com; ps_n=0; ps_l=0;'+cookies+f'fbsr_{fbm}=xxxxxxxxxxxxxxxxxx',
'User-Agent':'Instagram 219.0.0.12.117 Android',
'Content-Type':'application/x-www-form-urlencoded',
'X-Ig-App-Id':f'{XIGAppID}'
},data=payload
)
已邀請的邦友 {{ invite_list.length }}/5
目前API分成兩種,一種是透過網頁反向工程得到的,一種則是Meta修訂後的API服務。
query,且須附上query_hash參數,使網址變為「 https://www.instagram.com/graphql/query/?query_hash=...&variables=... 」希望有幫助到您=^w^=
