您好:
參考書本
import json
import requests
url = "https://www.googleapis.com/books/v1/volumes?maxResults=5&q=Python&projection=lite"
jsonfile = "Books.json"
r = requests.get(url)
r.encoding = "utf8"
json_data = json.loads(r.text)
print(json_data)
with open(jsonfile, 'w') as fp:
json.dump(json_data, fp)
在開發軟體,呈現中文字
但寫入Books.json卻是 \u8cc7
請問這是什麼原因?
該如何處理呢?
謝謝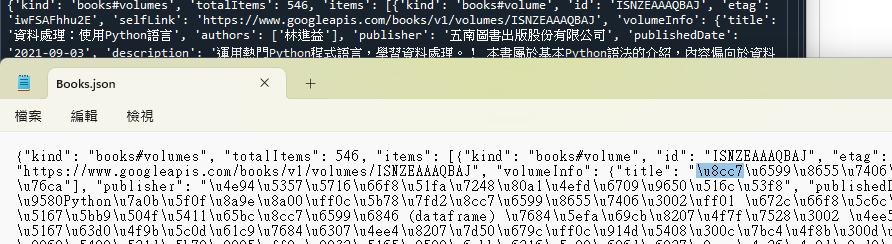
已邀請的邦友 {{ invite_list.length }}/5
Answer from ChatGPT
這種情況是因為在 Python 中,當將 Unicode 字符(例如中文)寫入 JSON 文件時,預設會將其轉換為 Unicode 編碼的轉義序列,例如 \u8cc7,這代表的是「資」這個字。這樣的轉換是為了保證 JSON 文件的兼容性,特別是針對不支持 Unicode 的應用程式。
要解決這個問題,使 JSON 文件直接顯示中文字符而不是轉義序列,你可以在 json.dump() 函數中使用 ensure_ascii=False 這個參數。這樣,Python 會以非 ASCII 編碼(即 Unicode)直接寫入中文字符。
修改範例如下:
import json
import requests
url = "https://www.googleapis.com/books/v1/volumes?maxResults=5&q=Python&projection=lite"
jsonfile = "Books.json"
r = requests.get(url)
r.encoding = "utf8"
json_data = json.loads(r.text)
print(json_data)
with open(jsonfile, 'w', encoding='utf8') as fp:
json.dump(json_data, fp, ensure_ascii=False, indent=4)
這樣處理後,Books.json 中的中文會以可讀形式顯示,而不是以 Unicode 轉義的形式出現。
