有時候,網頁上的data除了產生表格外,會貼心的有列印,另存html, 另存csv的功能,
雖然抓網頁也不是很困難,但是有整理好的格式不用, 也說不過去了.
只是它的網址有時候有點不易看出來,要用點工具來找。因為家裏只有Linux desktop(ubuntu), 沒有原先規畫好的fiddle可用,筆者改用fire fox的plugin.試試!
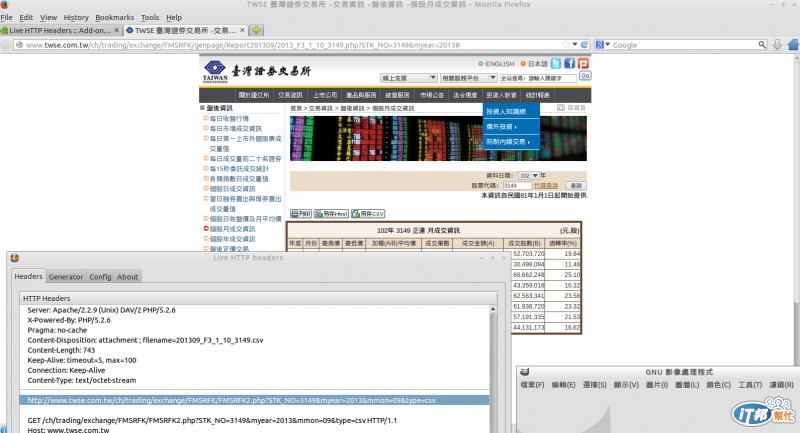
裝好插件後,在tools/Live Http Headers, 點兩下打開,當有網址異動時,就會有訊息浮現。
証交所上的個股月成交資訊,URL是這種格式,http://www.twse.com.tw/ch/trading/exchange/FMSRFK/genpage/Report201309/2013_F3_1_10_3149.php?STK_NO=3149&myear=2013#,
這會抓整張網頁下來,用上述的小工具,可抓到http://www.twse.com.tw/ch/trading/exchange/FMSRFK/FMSRFK2.php?STK_NO=3149&myear=2013&mmon=09&type=csv,
試一下看看!
url = 'http://www.twse.com.tw/ch/trading/exchange/FMSRFK/FMSRFK2.php?STK_NO=3149&myear=2013&mmon=09&type=csv'
response = urllib.request.urlopen(url)
html = response.read()
print(html.decode('cp950','ignore')) #.encode('utf-8')
output:
"102年 3149 正達 月成交資訊(元,股)"
年度,月份,最高價,最低價,加權(A/B)平均價,成交筆數,成交金額(A),成交股數(B),週轉率(%)
102,1,76.70,65.00,69.54,"34,768","3,665,467,833","52,703,720",19.84
102,2,73.60,67.50,71.11,"18,391","2,168,838,114","30,498,094",11.48
102,3,75.80,67.70,71.73,"42,305","4,781,729,141","66,662,248",25.10
102,4,71.70,62.40,66.26,"26,880","2,873,029,618","43,359,018",16.32
102,5,68.50,61.20,65.04,"38,742","4,069,324,698","62,563,341",23.56
102,6,61.00,50.00,55.44,"34,873","3,434,395,636","61,938,720",23.32
102,7,61.90,50.50,57.14,"28,386","3,268,354,276","57,191,335",21.53
102,8,60.60,52.70,56.63,"23,895","2,499,503,198","44,131,173",16.62
說明: 1. 本統計資訊含一般、零股、盤後定價、鉅額交易,不含拍賣、標購。
相對於抓整張網頁,那麼大的資訊量,這個資訊量顯得很親和。
証交所的data, 只能一次把一家公司一整年的月成交價產生,所以我們要自己處理一千多家的月成交。
接著今晚的練習:
練習一:產生所有公司的股票代號(從月營收data)
import sqlite3
conn = sqlite3.connect('revenue.db')
conn.text_factory = str
c = conn.cursor()
for row in c.execute("SELECT DISTINCT cpy FROM rvn WHERE date='201301'"):
print (row[0])
output:
1101
1102
1103
..........................
9944
9945
9955
9105
練習二:所有公司的股票代號(從月營收data)的筆數
c.execute("SELECT COUNT(*) FROM rvn WHERE date='201301'") #DISTINCT cpy
result=c.fetchone()
print(result)
1204筆
把1204筆另存csv檔
import urllib.request
import sqlite3
conn = sqlite3.connect('revenue.db')
conn.text_factory = str
c = conn.cursor()
for row in c.execute("SELECT DISTINCT cpy FROM rvn WHERE date='201301'"):
url = 'http://www.twse.com.tw/ch/trading/exchange/FMSRFK/FMSRFK2.php?STK_NO='+row[0]+'&myear=2013&mmon=09&type=csv'
print (url)
response = urllib.request.urlopen(url)
html = response.read()
s=html.decode('cp950','ignore') #.encode('utf-8')
#print(s)
fnm='/home/timloo/stock/month/2013_'+row[0]+'.csv'
f = open(fnm,'w')
f.write(s)
f.close()
這枝小程式跑了2分鐘左右,把1204家的今年各月的單價寫另存csv檔。
接著,開本系列文章的第二個資料表來放每月平均股價。
import sqlite3
conn = sqlite3.connect('revenue.db')
c = conn.cursor()
c.execute('''CREATE TABLE m_prc
(yr text, mon text, hhp real,
lwp real,mnp real,cnt real,amt real,scnt real,rate real)''') #月成交檔:年度,月份,最高價,最低價,加權(A/B)平均價,成交筆數,成交金額(A),成交股數(B),週轉率(%)
conn.commit()
筆者幾乎是只用單純的幾個sqlite3指令,所以沒有安裝GUI manager才協助開table一類的工作。
資料面的小異常:
本來要一口氣寫入sqlite3,現在發生了一些狀況,並不是每家公司都是
固定有8筆(1~8月)的data, 有些是新上市的公司,也許才只有2個月的股價,
目前筆者對csv.reader傳回的物件,還沒法分析其動態的筆數,故留待明天來解。
一些奇怪的data, 抓不到data, 証交所抓不到data.
查無資料:102年 股票代碼:9946
,yahoo有
http://tw.stock.yahoo.com/q/ts?s=9946

