技術文章
技術問答
iT 徵才
聊天室
2026 鐵人賽
登入/註冊
文章
問答
Tag
邦友
鐵人賽
搜尋
DAY
11
0
Azure 30天
系列 第
11
篇
Day 11. 初探Machine Learning (下)
鐵人賽
wtc
2014-10-11 00:12:33
1804 瀏覽
分享至
續上篇
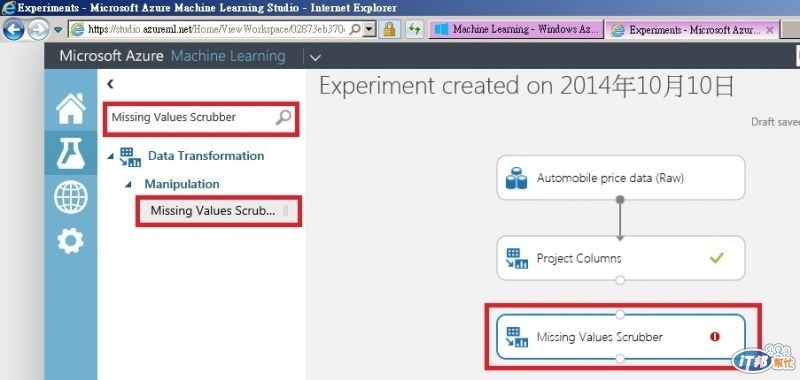
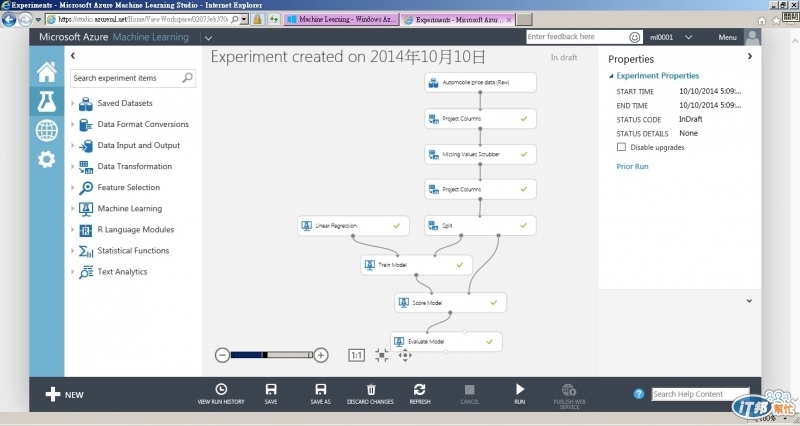
再來選擇Missing Values Scrubber元件加到設計視窗
同樣將Project Columns的資料傳給Missing Values Scrubber, 接著在右方For missing values的選項點'Remove entire row', 這個步驟會將一些缺數值的資料整行移除, 算是資料清裡
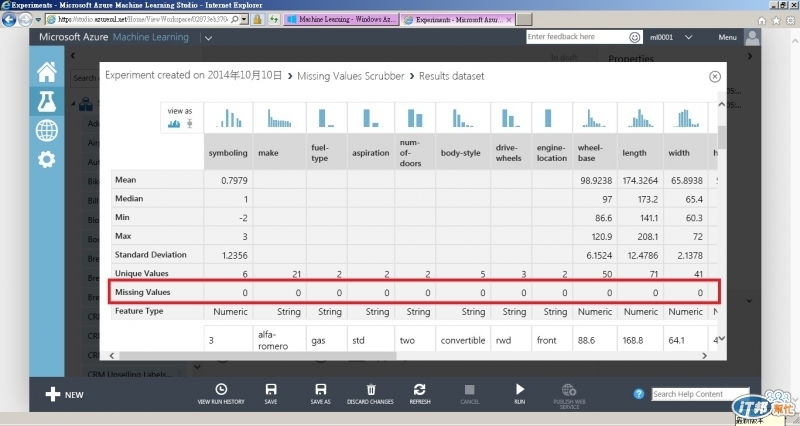
這時同樣按執行, 再去Missing Values Scrubber元件選Visualize再看結果, 即可看到Missing Values都是0
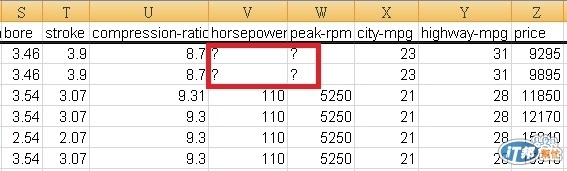
到底移除了什麼, 比對前後資料就可發現像是?的資料, 因為無法處理, 就整行從dataset移除
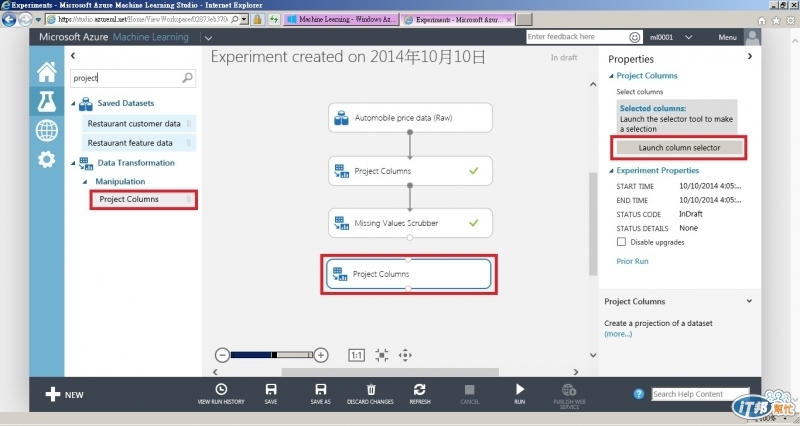
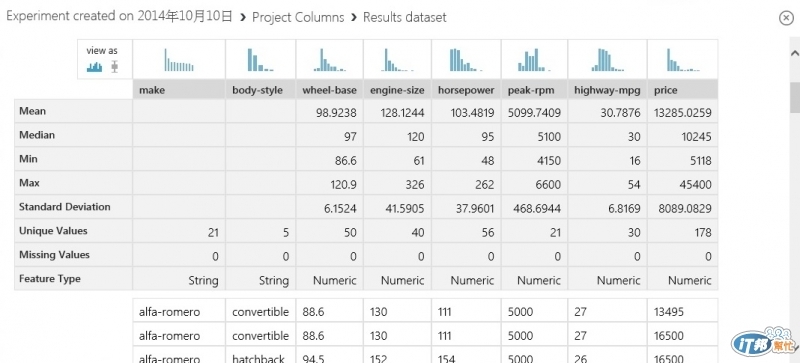
接著新增一個Project Columns, 並啟動cloumn selector
這次Begin With 'no columns', include column names 貼上以下字串再確定
make, body-style, wheel-base, engine-size, horsepower, peak-rpm, highway-mpg, price
同樣可先執行一次, 再看資料就可看出現在只會列出上面所選取的欄位
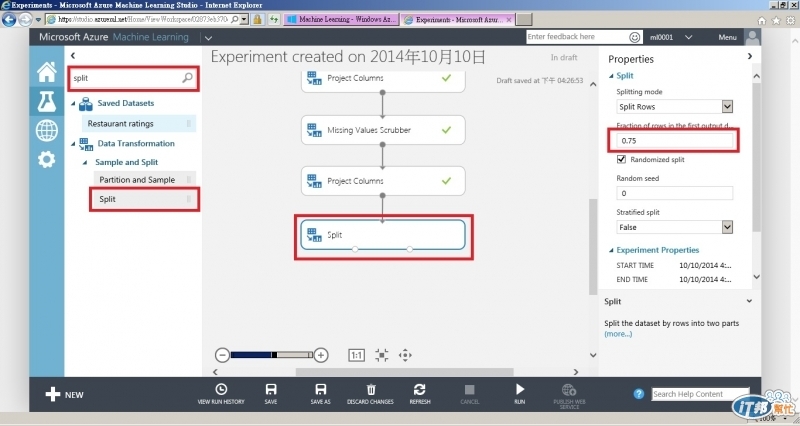
再來要將資料作切分, 將最後選出的資料75%拿來作訓練, 25%作測試驗證. 選取split, 放到最後一個Project Columns下方, 右邊將Fraction of rows in the first output dataset設為0.75
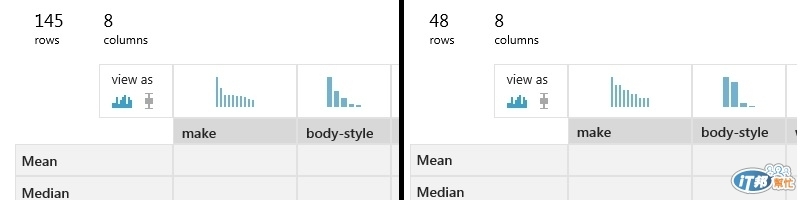
執行後, 在split下方可看到兩個dataset, 分別可看出有145與48筆資料, 也就是75%, 25%的比例
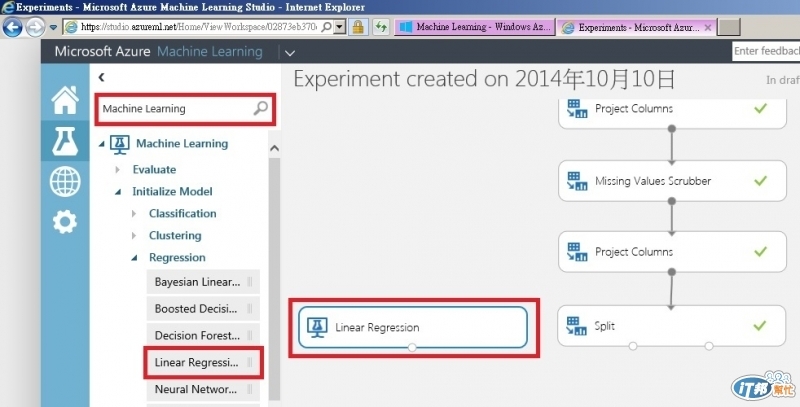
搜尋Machine Learning, 會列出多種演算法, 選擇Linear Regression當作這次實作的預測演算法
有了演算法, 也有資料, 接著就要訓練資料. 選取Train Model到設計框內, 上方兩個連接點一個接演算法, 另一個接資料來源
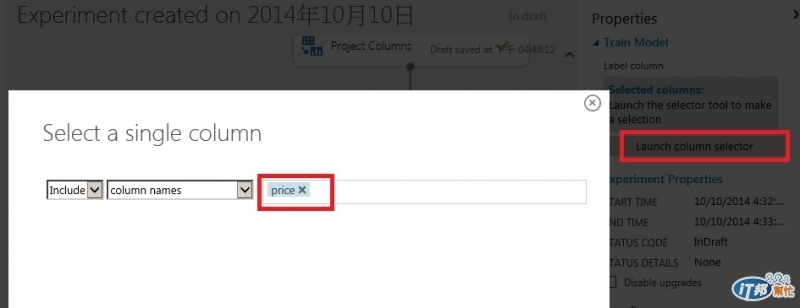
點右方的Launch column selector, 選取要預測的欄位, 也就是價格price
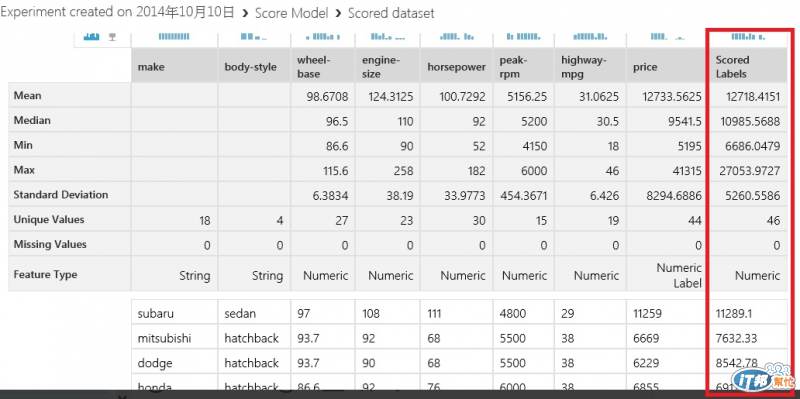
接著用Score Model來驗證剛剛切出來的25%資料, 將連結線接好之後執行
Visualize執行後的Score Model, 可看到最右邊多一欄預測的價格, 可與左邊原本的price價格作比對, 看這個演算模型的正確性
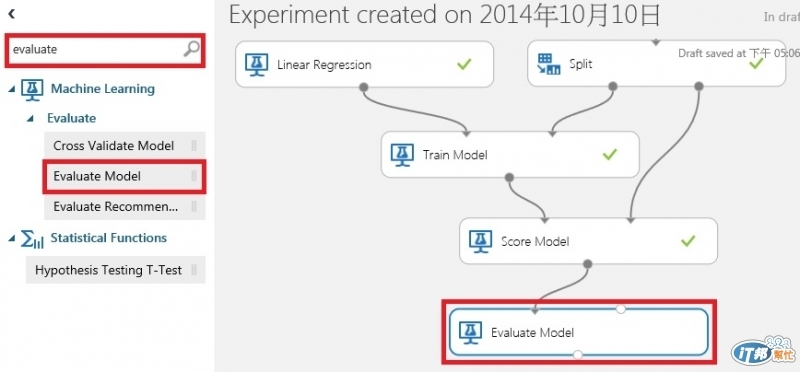
最後在新增一個Evaluate Model, 左邊的資料來源承接Score Model, 再執行一次
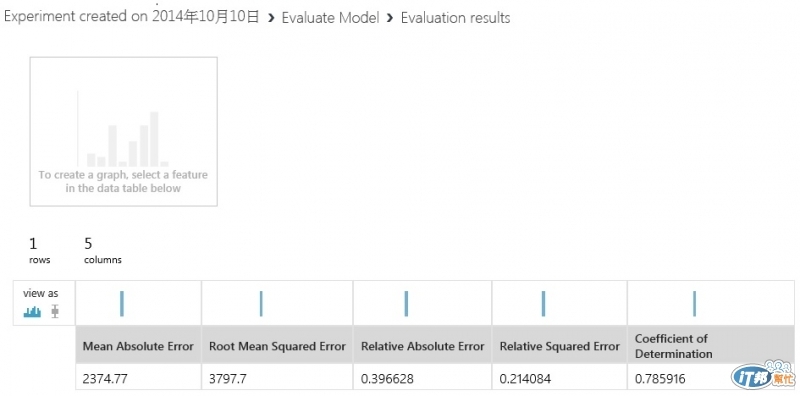
Visualize最後的結果, 幾個error數值越小越好, 最後一個Coefficient of Determination則是要趨近於1才算好, 至於修正則是可以靠調整不同演算法設定, 來達到最好的預測結果
最後整個完成的全貌
感覺起來像是圖型化的資料採礦預測.
留言
追蹤
檢舉
上一篇
Day 10. 初探Machine Learning (上)
下一篇
Day 12. Machine Learning與Web Service
系列文
Azure 30天
共
30
篇
目錄
RSS系列文
訂閱系列文
5
人訂閱
26
Day 26. Azure SQL 複製, 匯入與匯出
27
Day 27. Azure SQL 同步機制
28
Day 28. Azure Schedule Job
29
Day 29. Azure 附加元件
30
Day 30. My Azure Girl
完整目錄
熱門推薦
{{ item.subject }}
{{ item.channelVendor }}
|
{{ item.webinarstarted }}
|
{{ formatDate(item.duration) }}
直播中
立即報名
尚未有邦友留言
立即登入留言
iThome鐵人賽
參賽組數
902
組
團體組數
37
組
累計文章數
19838
篇
完賽人數
528
人
看影片追技術
看更多
{{ item.subject }}
{{ item.channelVendor }}
|
{{ formatDate(item.duration) }}
直播中
熱門tag
15th鐵人賽
16th鐵人賽
13th鐵人賽
14th鐵人賽
17th鐵人賽
12th鐵人賽
11th鐵人賽
鐵人賽
2019鐵人賽
javascript
2018鐵人賽
python
2017鐵人賽
windows
php
c#
linux
windows server
css
react
熱門問題
趣味SQL,給了一組編號後,用SQL產生亂數編碼的結果(更新Copilot及Google AI見解,SQL只能貼圖)
關於ASUS RS100-E11-PI2的磁碟陣列
已解決已解決
AI會議轉錄如何盡可能縮小明文攻擊面?
熱門回答
關於ASUS RS100-E11-PI2的磁碟陣列
趣味SQL,給了一組編號後,用SQL產生亂數編碼的結果(更新Copilot及Google AI見解,SQL只能貼圖)
熱門文章
從注入攻擊到詐騙防護:@martin_yeung/llm-up-guardrail 為你的 AI 打造生產級安全防線
AI 推論正在吞噬雲端
從企業導入 AI Agent 現況,到 AI 投資市場敘事的差異
用 AI 寫 MCP server 很快就會跑,但「會跑」不等於「安全」——多租戶隔離的五條 best practice
Memory 系統 — 讓 Claude 不只記得「專案」,還記得「你」
IT邦幫忙
×
標記使用者
輸入對方的帳號或暱稱
Loading
找不到結果。
標記
{{ result.label }}
{{ result.account }}






 iThome鐵人賽
iThome鐵人賽