ALU 所提供的加法與減法運算就其本質都是使用加法器來實現的
前面所介紹的加法器是由一個一個的全加器串連而成
也就是前一個全加器的進位輸出會是下一個全加器的進位輸入
但是在性能上卻存在著很大的問題,這一篇將先分析這種加法器的性能
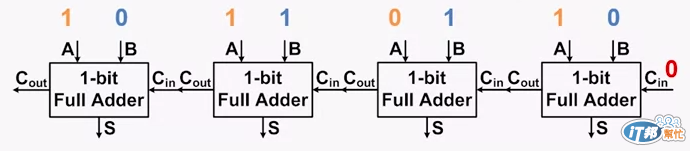
一樣以 4bits 的加法器為例,我們可以看到只有最右邊的全加器三個輸入都準備好
其他三個暫時是還不能運算的,只有等到前面的算完之後才能夠進行加法運算
也因此這種加法器我們又稱為 行波進位加法器 (Ripple-Carry Adder RCA)
其優點為電路布局簡單,設計方便
但是缺點也很明顯,就是高位運算必須等到低位運算完成,延遲時間會比較長
下圖是針對四位元的加法器延遲時間分析

要找出最長的延遲時間就是先找出從輸入到輸出的最長路徑,主要考慮的是門延遲時間
假設每個門延遲時間是T,所以從上圖可以看到這個最長的門延遲時間就是 (2*4+1)T
也就可以歸納出如果有n個全加器,其總延遲時間就是 (2n+1)T
以 32bits 的 RCA 來說就是 65T,那這個延遲時間是多少呢?
我們以 iPhone 的 A7 SoC 為例,其主頻是 1.3GHz (0.66ns),也就是 Clock 相連兩個上升延的時間差
所以在從暫存器讀取數值→進入全加器運算→輸出運算結果,其時間不能超過 0.66ns
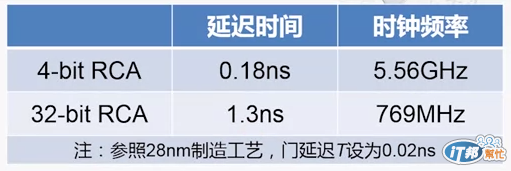
但是以 28nm 的製造工藝而言,65T 也就是 1.3ns,換算成時鐘頻率最多只能到 769MHz
這樣加法器就變成了在性能上的一個考慮重點,那該如何對性能進行優化呢?
下一篇就將繼續介紹加法器的優化思路,以及實現過程


 iThome鐵人賽
iThome鐵人賽