今天要來教大家的是,透過VBA來抓取網頁資料,其實,VBA可以完的把戲很多,「抓取」資料只是個初步,當使用的更熟後,「送出」資料的用途就更多了。
不過我們今天不談這麼多,緊針對抓取這部份來討論,要用的例子,是網路雜誌issuu.com的服務,要怎麼透過VBA抓取下來。
我們先來研究這個網站,當連到首頁後,可以挑選不同的雜誌閱讀,我們先隨便挑一本,然後研究他的網頁內容:
我們挑選中間那本為例子:
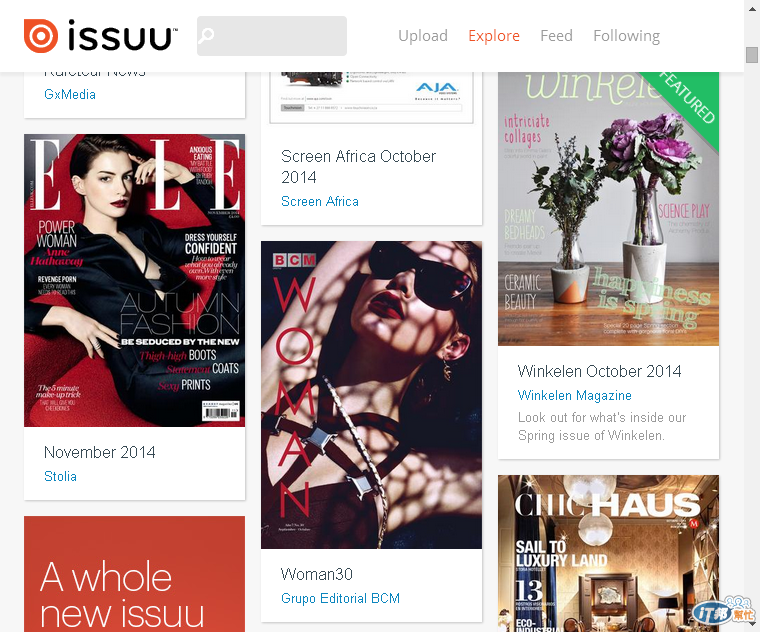
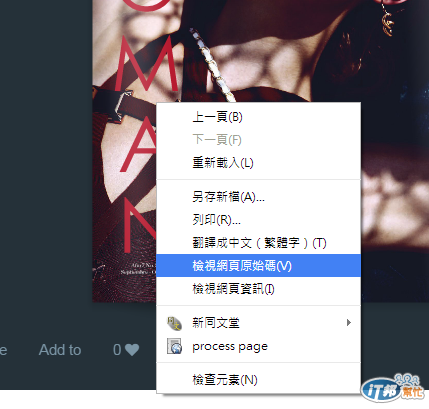
進去後,即可看到雜誌第一頁,我們於下方空白處按下右鍵叫出「檢視網頁原始碼」,瀏覽器差異可能會有不同的叫出方式,本範例為使用Chrome瀏覽器。
檢查一下後,可以發現第一頁的JPG
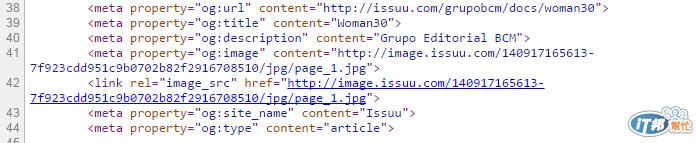
單獨取出路徑後開啟,確認檔案位置正確

接下來,要能夠知道這本雜誌總共有幾頁,查看網頁原始碼後,可發下以下資料串:
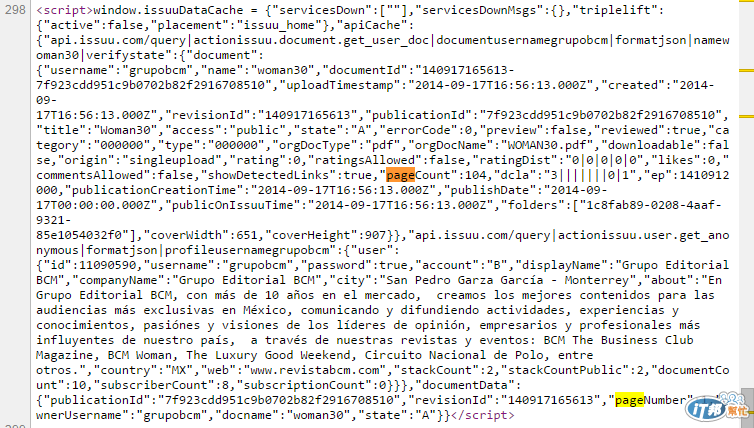
其中的PageCount就是一共有幾頁,而上面一點的documentId指的是該份文件在issuu.com的文件代碼,我們嘗試在網址列輸入圖片位置:
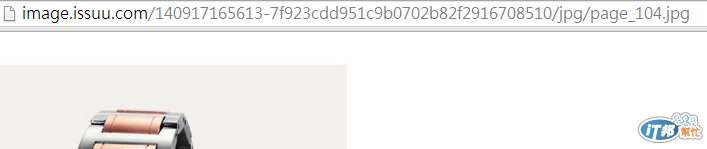
Bingo!這樣我們就可以知道大概的圖片擺放位置,都是由 image.issuu.com/documentId/jpg/page_PageNumber.jpg
藍色部份是變數,我們只需要透過for迴圈來產生圖片檔案路徑後,透過ADODB.Stream來儲存取回的網頁資料,即可產生圖片檔,最後,全部圖片取回後,在透過PDFCreator內附的Image2PDF程式,即可把圖片整批會成一個PDF檔案,以便儲存。
以下我們就來看看程式:
主程式,用來呼叫GetISSUU子程式
Sub doGetISSUU()
Call GetISSUU("http://issuu.com/grupobcm/docs/woman30")
MsgBox "Done!"
End Sub
子程式,用來讀取網頁內容,並取得相關變數,然後呼叫下載的副程式繼續處理下子事宜:
Function GetISSUU(ISSUU_URL As String)
Dim myURL As String
Dim WinHttpReq As Object
Dim strBody As String
Dim strDocumentId As String, iPageCount As Integer, strTitle As String
Dim strPath As String
Dim strFileName As String
strPath = "D:\temp\ISSUU"
Dim iDocumentId_Start As Integer, iDocumentId_End As Integer
Dim iPageCount_Start As Integer, iPageCount_End As Integer
Dim iTitle_Start As Integer, iTitle_End As Integer
'使用Microsoft.XMLHTTP物件,傳送網址(ISSUU_URL)給對方,然後取回(GET)回傳資料
Set WinHttpReq = CreateObject("Microsoft.XMLHTTP")
'WinHttpReq.Open "GET", myURL, False, "username", "password"
WinHttpReq.Open "GET", ISSUU_URL, False
WinHttpReq.send
'將回傳資料放到strBody變數
strBody = WinHttpReq.responseText
'確認回傳的狀態是否正常,200代表正常
If WinHttpReq.Status = 200 Then
'Debug.Print strBody
'用InStr取出所需變數
iDocumentId_Start = InStr(strBody, """documentId"":") + 14
iDocumentId_End = InStr(Mid(strBody, iDocumentId_Start, Len(strBody)), ",") + iDocumentId_Start
iPageCount_Start = InStr(strBody, """pageCount"":") + 12
iPageCount_End = InStr(Mid(strBody, iPageCount_Start, Len(strBody)), ",") + iPageCount_Start
iTitle_Start = InStr(strBody, """title"":") + 9
iTitle_End = InStr(Mid(strBody, iTitle_Start, Len(strBody)), ",") + iTitle_Start
strDocumentId = Mid(strBody, iDocumentId_Start, iDocumentId_End - iDocumentId_Start - 2)
iPageCount = Mid(strBody, iPageCount_Start, iPageCount_End - iPageCount_Start - 1)
strTitle = Mid(strBody, iTitle_Start, iTitle_End - iTitle_Start - 2)
'Debug.Print strTitle
End If
'檔名以目前時間取名
strFileName = Format(Now, "yyyymmdd-hhmmss")
Debug.Print strFileName & ": " & strTitle
'呼叫下載副程式
Call Download_ISSUU_File(strDocumentId, iPageCount, strPath, strFileName)
'執行PDFCreator內建的Images2PDF子程式,將JPEG檔包成PDF檔
Call RunCmd("""" & Environ("ProgramFiles") & "\PDFCreator\Images2PDF\Images2PDFC.exe" & """" & " /i """ & strPath & "\" & strFileName & "\*.jpg"" /e """ & strPath & "\" & strFileName & ".pdf""", True, 1)
End Function
下載副程式,用來批次下載每頁圖片檔案:
Function Download_ISSUU_File(strDocumentId As String, iPageCount As Integer, strSavePath As String, strFileName As String)
'strDocumentId ISSUU的書本ID
'iPageCount 頁數
'strSavePath 存放路徑
'strFileName 檔案名稱
Dim myURL As String
Dim WinHttpReq As Object
strFileName = Replace(strFileName, "/", "")
MkDir (strSavePath & "\" & strFileName)
'下載每頁圖片檔
For i = 1 To iPageCount
myURL = "http://image.issuu.com/" & strDocumentId & "/jpg/page_" & Format(i, "0") & ".jpg"
Set WinHttpReq = CreateObject("Microsoft.XMLHTTP")
'WinHttpReq.Open "GET", myURL, False, "username", "password"
WinHttpReq.Open "GET", myURL, False
WinHttpReq.send
If WinHttpReq.Status = 200 Then
Set oStream = CreateObject("ADODB.Stream")
oStream.Open
oStream.Type = 1
oStream.Write WinHttpReq.responseBody
oStream.SaveToFile strSavePath & "\" & strFileName & "\" & strFileName & "_" & Format(i, "000") & ".jpg", 2 ' 1 = 不複寫, 2 = 複寫
oStream.Close
End If
Next
End Function
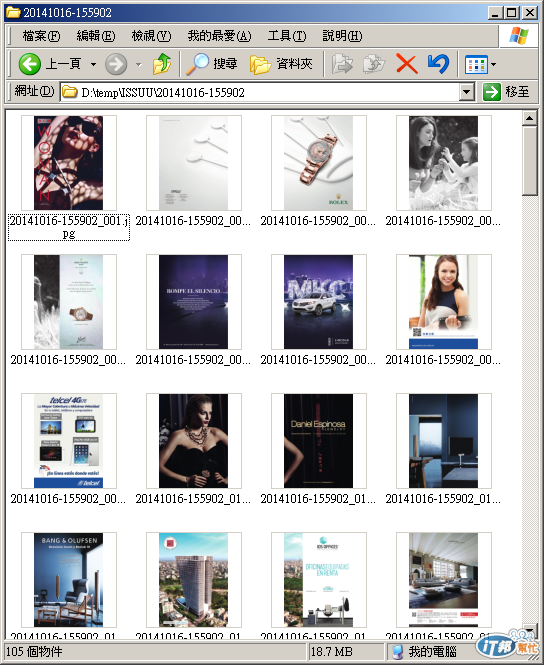
下載下來的每張圖片檔
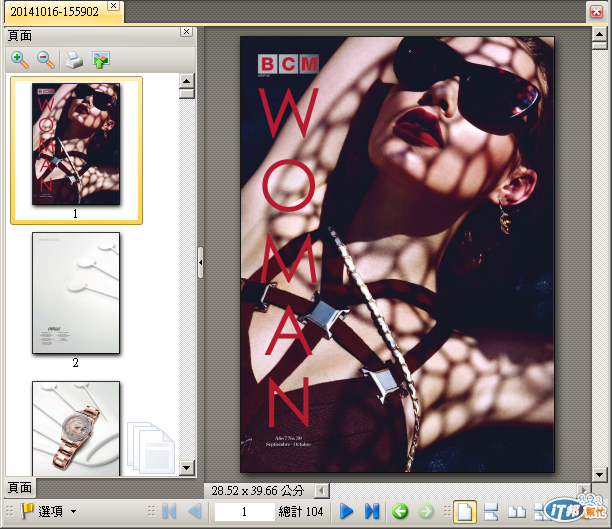
儲存成PDF檔案後開啟的樣子:
由今天的內容,您是否學得讀取網頁、分析網頁內容,然後在擴大抓取所需資料?這程式就像網頁爬蟲程式一樣,只是還是十分初級,僅單一功能,不過相信這樣的介紹已經足夠,接下來,就是看自己的需求,去創造自己的程式了!

