前面幾天介紹了幾個比較常用的 vue directive & vue option 接下來,將會練習套用 vuex 到系統中。
從前幾個範例中,可以發現,資料都是存放在各自 page 的 data 裡面,再傳給 component 進而完成一個頁面呈現。
ex: token, user info, shopping cart list etc..
因此我們需要一個集中所有資料的地方:store
單向資料流
action
如果你有以上的問題可以使用看看:vuex(基於單向資料流 Flux 設計模式 在 Vue 框架中的實作)
Vue+ flux=vuex

圖片來源:https://www.youtube.com/watch?v=RY7vcYvb69kPen-Pineapple-Apple-Pen - PPAP Song (original) PIKO-TARO
演員:PIKO-TARO
一樣透過 npm 或 YARN 安裝
npm install vuex --save
打開 main.js 宣告使用 vuex
// 引入 vuex
import Vuex from 'vuex'
// 告訴 Vue 使用 vuex
Vue.use(Vuex)

我們使用 vuex 官方流程圖來解釋:所有的動作都是從 action 出發,接著到了 store 把結果存起來改變 state 然後因為 state 改變了,所以 view(元件或頁面)就會跟著改變。
只有一個重點,就是這一連串的行為是不可逆的,因此稱為:單向資料流。

在 vuex 的設計中,view(元件或頁面)的變化不是他的職權範圍,這塊單純的讓 vue(專業的)去控制,因此在上面這張圖裡面,有一個塊綠色虛線所包含的內容才是 vuex 的工作項目,與 Vue 的工作完全沒有重疊,各司其職的搭配。
所有個動作都是從 action 開始的!因此我們從 action 開始看這張圖:
定義了整個應用程式的行為如:按下 login 這顆按鈕,它是一個 action!現在我們要開始登入囉!這樣的行為通常需要與 server 溝通,因此 call API 的行為(非同步)也會在 action 中執行!
它使用 commit 向 Mutations 溝通(傳遞資料)
負責接收 action(commit) 資料並計算邏輯後改變 State
只有 mutation 可以改變 state!
到這邊,也許大家會覺得.. 為什麼流程要如此麻煩?
action --> commit --> mutation
我直接執行 mutation 不行嗎?
不行!最大的差別在於:
非同步的事件,再利用 commit 與 mutation 溝通。同步的。想像一下我們過去的程式流程,常常卡在處理這些非同步的流程上面,如果我們到 mutation 這層處理非同步的事件,那問題就沒有被解決,依然要等待 server response 並且計算邏輯後,才可以改變狀態。
現在我們將這些事件,往前一層到 action 去處理的話,就可以保證到了 mutation 資料都是即時的,計算後的狀態也是現在進行式。
負責記錄應用程式所有的 State
| 步驟 | 流程描述 | Flux(vuex) 流程 |
|---|---|---|
| 1 | 在登入頁按下 login 按鈕 | vue |
| 2 | 按鈕觸發 action | action |
| 3 | action 調用 login API | action |
| 4 | server response success 帳號密碼正確 | action (commit) |
| 5 | 接收 action 資料,計算邏輯,改變狀態 | mutation |
| 6 | State 改變 ex: login: true or token: '3345678' |
state |
| 7 | 轉跳到 index 頁面 | vue |
實作小範例入門 Vue & Vuex 2.0 - github 完整範例
使用 git checkout 切換每天範例。
我一步一步學到這,覺得你解釋得很清楚
然後想再詳問你
為什麼最後這張圖可以代表你對vuex的感覺?
我其實初學,還是不懂這張圖的含義
hi qaz3182 你好,
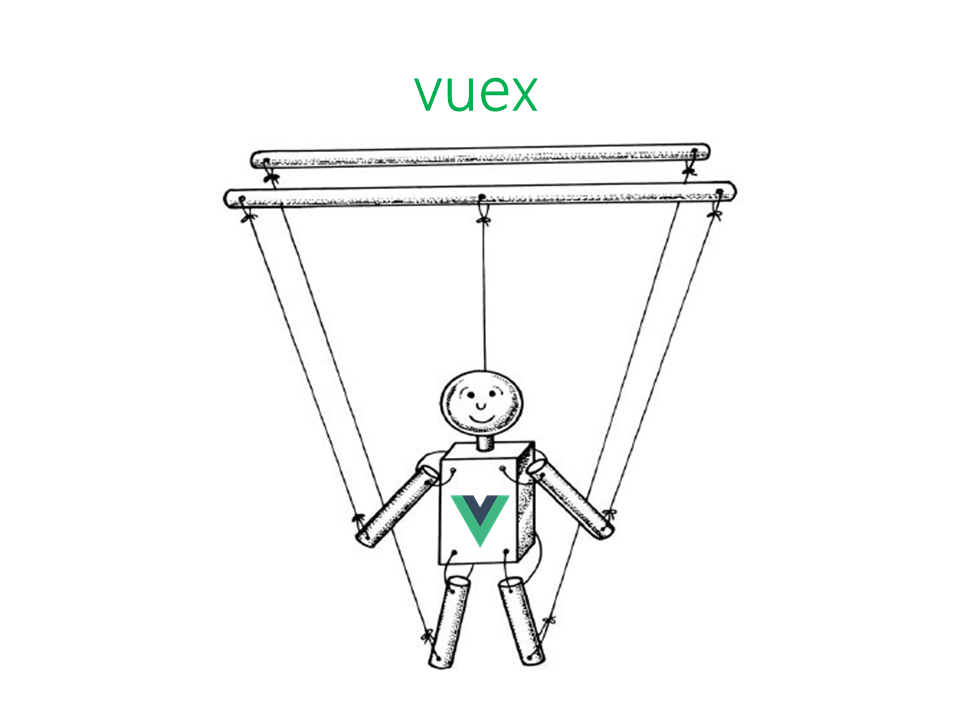
最後這張木偶圖解釋一下:
有鑑於 vue 作者的中心概念是 數據驅動 所有畫面上的狀態都是因為數據改變而改變 UI 樣式。
多個 vue 元件要統一存取一個狀態的話,必須仰賴第三方套件如: vuex
我們導入了 vuex 將所有 web app 的狀態都統一存放於 vuex 因此就像是系統的控制端,類似大腦的概念,所以 vue 單純就是元件,好像小木偶一樣被 vuex 操控著。
邏輯不在
vue身上了,在大腦中vuex。
後面有幾個 vuex 範例可以試著做做看,大部分都是我自己亂想的題目,我會在文章前面寫出今天的目標,內容是我簡易實作的結果,歡迎參考。
謝謝你的閱讀。
把非同步處理都提到 action 去處理,就可以保證到了 mutation 資料都是即時的:所以Vuex整個設計好像就是為了在mutation時可以snapshot到實際update後的state,以便在如google devtool裡debug。是不是這樣呢?
換句話說,如果不是為了這個目的,即使是像大大您在[錯誤流程]那樣,在mutation裡等待server response,也不會有什麼問題吧? 還是這就是您說"卡在處理這些非同步的流程"的意思呢?
抱歉個人寫前端資歷很淺,還請賜教!
Hi Amigo 你好:
很高興你閱讀我的文章。
其實主要是設計模式的關係 Vuex、Redux、Flux
都是基於Flux 單向資料流架構的開發流程 / 工具
所以在這裏面我們(Vuex)定義了處理同步(mutation) / 非同步(action) 的區域,所以相關的操作一定要放在對的地方。
使用不同前端開發 Library / Framework 會有不同的稱呼,但是一樣會定義操作這兩個區域的方法。
劃分好工作區域未來不管維護/開發什麼專案,只要專案是使用單向資料流設計模式我們可以很快速的上手,這就是設計模式的好處。
最後我用一張圖橫向剖析解釋看看:
主要目的是:透過Flux 單向資料流優美的處理非同步事件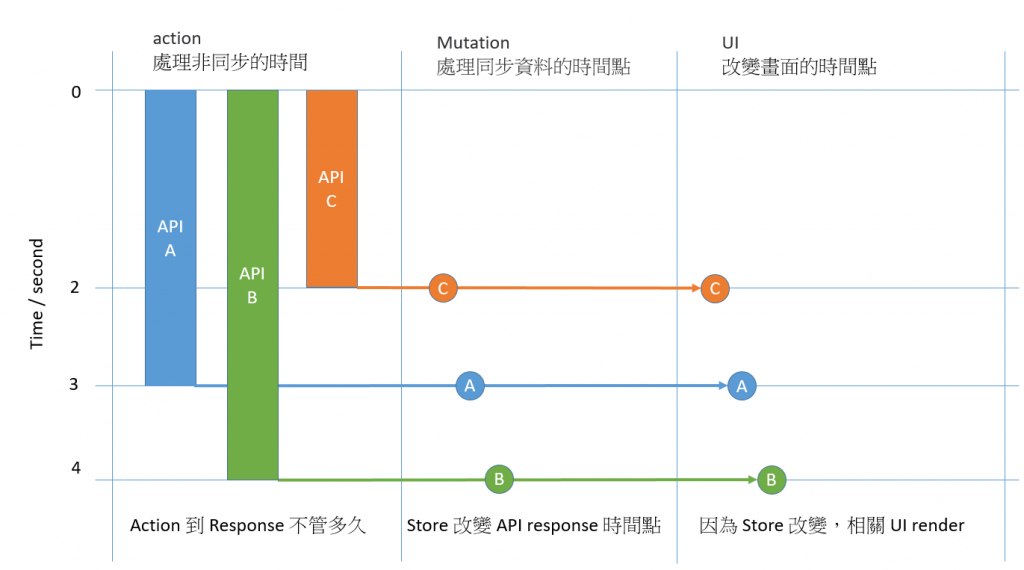
假設我們有一個畫面需要 A、B、C 三個不同的 API 資料來組成,
三隻 API 根據需要的資料 response 的時間一定不同!!
在這種情況下我們透過 ajax 取得資料後存到 Vuex store
store 改變了,就會改變監聽 store 的 UI 畫面就會更新
因此我們不再需要在 Page 內寫完所有的邏輯!
只要在進入 Page 時候執行三個 Action 呼叫 A、B、C API 取得資料就會更新畫面,
而且取得 A、B、C API 方法可以重複利用
例如:我們有 Page 2 剛好需要 B 加上新的 D API 資料來組成,
那麼你現在有 B 的方法了,只要開發 D 的方法,就可以完成這個工作.
不知道這些解釋有沒有回答到你,如果有問題再提出,謝謝。
Jacky你好:
謝謝你第一段的說明,很切中我的問題,受益良多。現在我知道這些規範(或許沒有強制)都是為了將state的改變(同步)集中在一個地方(mutations),不僅可以追蹤,大家都有這樣的共識程式也容易閱讀。非同步的codes(二分法)就另外規畫在actions,Vuex又提供plugin讓actions也可以追蹤,這樣actions的用處我就懂了。
還有原來這不只是Vuex的設計理念。
另外第二段,我知道這是codes共用(library)的概念,但要實現"Flux單向資料流"一定要由同一組codes去維護state嗎? 還是這並不是單向的必要的規範?


