延續先前的範例,假設我只想看見一點的股票交易資料勒?例如:
最近一個小時內,總交易次數總為何?交易量最高的五支股票為何?
OK,來分析問題。首先每批資料的區間只有短短數妙,但條件是一個小時內。所以一定是跨多個批次處理,那就會落在stateful的範疇。但先前介紹的updateStateByKey跟mapWithState都是一直持續狀態下去地老天荒阿。當然還是能做,在State裏面存放時間相關狀態,然後更新時比較並砍過期值。不過若沒有特殊設計,這樣的作法必須full scan State的KV,感覺就不是很好的作法。而這種監控某個時段內的需求也不少見,所以Spark當然也有對應的函式啦:那就是Window Operation!
先來看個官方的示意圖先: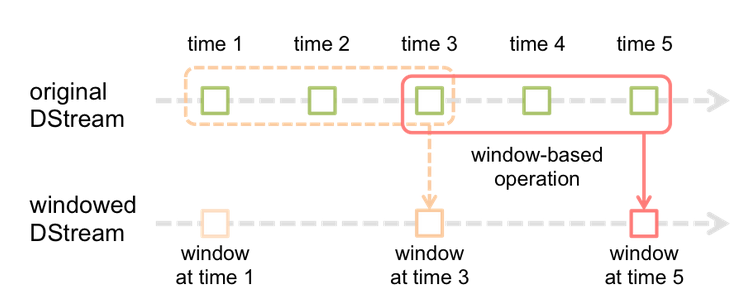
從圖中可以很看出來,Window Operation的概念簡言之就是一次吃N個批次(而一個micro-batch的資料可能被多個Window框進去~)的資料進來一起更新並維護Window內的狀態。而Window最重要的兩個參數是:
Window Duration: 一次計算要吃幾批資料。假設每個micro-batch的區間為5秒,以上圖來說一次Window會看三批資料,所以Window Duration=15秒Sliding Duration:計算頻率,以上圖來說,每間隔一個批次才啟動計算,所以Sliding Duration=10秒。而有些Windows函式若沒有指定Sliding Duration預設會等於micro-batch的區間,也就是每個進來都更新Windows。注意設定時**Sliding Duration跟Window Duration都要是micro-batch區間的整數倍*
回頭看看任務需求,
Windows Operation常用的函式列表如下:
其中XXXByKey就是for pairDStream RDD用的
開始解題吧:
有沒有感覺這個問題其實跟簡單的WordCount有點像XD?只差在用了感覺很威的Streaming還有Window Opeartion。既然像WordCount當然就會講到MapReduce啦,而在此map階段不用自己給1了,而是從amount直接取。Reduce階段就差不多了,疊加就是了。就決定是你了map+Window+reduceByKey!
[Snippet.43]map+ReduceByKey+Window應用
val stocksPerWindow = orders.map(x => (x.symbol, x.amount)). ①
window(Minutes(60)). ②
reduceByKey(_ + _) ③
①將orders轉成pair DStream
②在pairDStream上建立Window,必填欄位是Sliding Duration,長度為Duration型別的Minutes(60)
③對這個Window內的pair DStream 執行reduceByKey。每個K對應到的V的操作是最常見的疊加
到這邊就完成90%了,那前五名勒?還記得之前的作法嗎?沒錯!一樣XD:
val topStocks = stocksPerWindow.
transform(_.sortBy(_._2, false).
zipWithIndex.
filter(_._2 < 5)).
map(_._1).
repartition(1).
map(_._1.toString).
glom.
map(arr => ("TOP5STOCKS", arr.toList))
這樣就用union能整合了:
val finalStream = buySellList.union(top5clList).union(topStocks)
當然你也能寫在一起:
val stocksPerWindow = orders.map(x => (x.symbol, x.amount)).
reduceByKeyAndWindow((_ + _), Minutes(60)).
transform(_.sortBy(_._2, false).
zipWithIndex.
filter(_._2 < 5)).
map(_._1).
repartition(1).
map(_._1.toString).
glom.
map(arr => ("TOP5STOCKS", arr.toList))
不過最好不要寫這麼長,這樣只有爽到自己XD
而且之前重複的部份(計算前5名的部份)可以拉出去封裝成函式
整合後輸出結果:
-------------------------------------------
Time: 1483947930000 ms
-------------------------------------------
(SELLS,List(19835))
(BUYS,List(20165))
(TOP5CLIENTS,List(36, 34, 15, 64, 9))
(TOP5STOCKS,List(BP, SIRI, LUV, AMD, INTC))
-------------------------------------------
Time: 1483947940000 ms
-------------------------------------------
(SELLS,List(24883))
(BUYS,List(25117))
(TOP5CLIENTS,List(15, 41, 23, 19, 64))
(TOP5STOCKS,List(AMD, INTC, BP, TOT, EGO))
剛剛的操作有用到Window還有ReduceByKey...那不就是函式列表中的reduceBykeyAndWindow嗎?沒錯XD!
[Snippet.44]reduceBykeyAndWindow
val stocksPerWindow = orders.map(x => (x.symbol, x.amount)).
reduceByKeyAndwindow((_ + _),Minutes(60)). ①
①第一個參數就是reduce參數,第二個就是Window Duration。
有沒有發現我都沒有寫Sliding Duration,因為我都用預設值,若要指定可以加在Window Duration後面,例如:reduceByKeyAndwindow((_ + _),Minutes(60),Seconds(10))這樣
而上述不管是Windows Opeartion中的reduceByKey或是reduceByWindow,都有另外一個版本,讓我們可以導入invertReduceFunction。原理是因為原始的方式每次計算是都要對整個Window執行reduce操作。這樣其實很沒有效率,因為可能大部分的元素都不會更動到,所以我們可以提供一個invertReduceFunction,類似提供若要離開Window的話該怎麼做的作法,這樣Window可以只將新的批次(而不是整個Windows Duration)的值reduce並更新,閉且對離開window的元素執行invertReduceFunction來更新Window。這樣就變成只關注進出,效率可以加快許多。
那之前範例的invertReduceFunction該怎麼寫?離開就減掉阿~easy:(-)
[Snippet.45]reduceBykeyAndWindow (with invertReduce)
val stocksPerWindow = orders.map(x => (x.symbol, x.amount)).
reduceByKeyAndwindow((_ + _),(_ - _),Minutes(60)). ①
①參數順序是reduceFun,invertReduceFun, Window Duration。
這個問題就簡單啦,Window中一筆資料就是一個交易次數對吧,那不就是計算Window中有框到幾個元素,該用哪個函式勒?
[Snippet.46]countByWindow
val transNum = orders.countByWindow(Minutes(60), Seconds(10)).
map(num => ("CountsOneHour", List(num.toString)))
一行就結束了XD~注意這裡不用轉pair DStream直接count就好啦。
反而後面的map比較多餘,那是要配合finalStream的KV格式做的轉換。
輸出整合結果:
-------------------------------------------
Time: 1484012220000 ms
-------------------------------------------
(SELLS,List(19835))
(BUYS,List(20165))
(TOP5CLIENTS,List(36, 34, 15, 64, 9))
(TOP5STOCKS,List(BP, SIRI, LUV, AMD, INTC))
(CountsOneHour,List(40000))
-------------------------------------------
Time: 1484012240000 ms
-------------------------------------------
(SELLS,List(24799))
(BUYS,List(25201))
(TOP5CLIENTS,List(23, 87, 41, 15, 32))
(TOP5STOCKS,List(AMD, INTC, RDS.B, SIRI, AUY))
(CountsOneHour,List(140000))
其他的函式就留給各位玩耍囉~


