Spark 1.6版時提出了新的stateful函式:mapWithState。本篇延續之前的範例,然後介紹mapWithState。
我們建立了兩個RDD:
numPerType:每N秒的買/賣次數 (stateless)top5clients:累積購買金額最高的前5名客戶((stateful),每N秒更新。將兩種DStream放在一個集合內,同時印出(top5clients印出clientID即可)
這該怎麼做勒?這邊可以用我們之前提過的join、cogroup或是我們再來要示範的union。在Spark中要將兩個RDD union起來的話,兩個RDD的元素型別一樣,接下來重點就是怎麼將numPerType跟top5clients轉成一樣的KV。
Key:可以考慮放成字串:"BUY","SELL","TOP5CLIENTS"Value:"BUY","SELL"的值是個數字而已,但"TOP5CLIENTS"必須存5個clientID,要麻就將ID連起來變成一個String,要麻就將Value宣告成List,"BUY","SELL"的值則為一個元素的List。再這裡我們用後者示範。開始吧,先將numPerType轉成(String,List)的kv:
val buySellList = numPerType.map(t =>
if (t._1) ("BUYS", List(t._2.toString))
else ("SELLS", List(t._2.toString))
)
K為Boolean,剛好可以用來放到判斷式裡面看要產生"BUYS"還是"SELLS"top5clients原本是多個KV值(5個)的集合,現在要變成一筆(Stirng,List),這部份就比較複雜了。因為每秒的值很小(前5個客戶的KV),所以我們可以透過repartition+glom連續技。glom會將同一個partition的資料轉成一個Array,先來簡單玩一下吧:
scala> val rdd = sc.parallelize(List((1,"abc"),(2,"ABB"),(3,"CCC"))) ①
rdd: org.apache.spark.rdd.RDD[(Int, String)] = ParallelCollectionRDD[0] at parallelize at <console>:24
scala> rdd.collect
res0: Array[(Int, String)] = Array((1,abc), (2,ABB), (3,CCC))
scala> rdd.partitions.size ②
res1: Int = 8
scala> rdd.glom.collect
res3: Array[Array[(Int, String)]] = Array(Array(), Array(), Array((1,abc)), ③ Array(), Array(), Array((2,ABB)), Array(), Array((3,CCC)))
scala> rdd.repartition(1).glom ④
res0: org.apache.spark.rdd.RDD[Array[(Int, String)]] = MapPartitionsRDD[5] at glom at <console>:27
scala> rdd.repartition(1).glom.collect
res5: Array[Array[(Int, String)]] = Array(Array((1,abc), (2,ABB), (3,CCC))) ④
①簡單宣告一個pairRDD
②觀察一下partition size
③如果直接glom會怎麼樣,觀察一下~恩,都分開了,存在不同Array
④如果先repartition勒?恩,都收集在一起了,這就是我要的!!
來看看要怎麼轉吧!
val top5clList = top5clients.repartition(1). ①
map(_._1.toString). ②
glom. ③
map(arr => ("TOP5CLIENTS", arr.toList)) ④
①將top5clients repartition
②glom前先轉換值成String
③glom,收集成RDD of Array(一個元素的Array)
④將Array轉成KV
都轉好就可以用union將兩個DStream的PairRDD串起來了
先看看一些簡易的union用法:
scala> val rdd = sc.parallelize(List((1,"abc"),(2,"ABB"),(3,"CCC"))) ①
rdd: org.apache.spark.rdd.RDD[(Int, String)] = ParallelCollectionRDD[34] at parallelize at <console>:24
scala> val rdd2 = sc.parallelize(List((11,"abc"),(22,"ABB"),(33,"CCC"))) ②
rdd2: org.apache.spark.rdd.RDD[(Int, String)] = ParallelCollectionRDD[35] at parallelize at <console>:24
scala> rdd.union(rdd2).collect
res10: Array[(Int, String)] = Array((1,abc), (2,ABB), (3,CCC), (11,abc), (22,ABB), (33,CCC))
scala> val rdd2 = sc.parallelize(List(("abc","abc"),(22,"ABB"),(33,"CCC"))) ③
rdd2: org.apache.spark.rdd.RDD[(Any, String)] = ParallelCollectionRDD[37] at parallelize at <console>:24
scala> rdd.union(rdd2).collect
<console>:29: error: type mismatch;
found : org.apache.spark.rdd.RDD[(Any, String)]
required: org.apache.spark.rdd.RDD[(Int, String)]
Note: (Any, String) >: (Int, String), but class RDD is invariant in type T.
You may wish to define T as -T instead. (SLS 4.5)
rdd.union(rdd2).collect
可以看到①②的型別一樣所以可以union,如果`K``的型別不同,可以發現噴mismatach Exception(像①③就沒辦法union)
接著回到主程式產生最後union起來的Dstream。
val finalStream = buySellList.union(top5clList)
這邊不就放完整的Code佔版面了,自己試著修看看吧,呼叫finalStream.print()的結果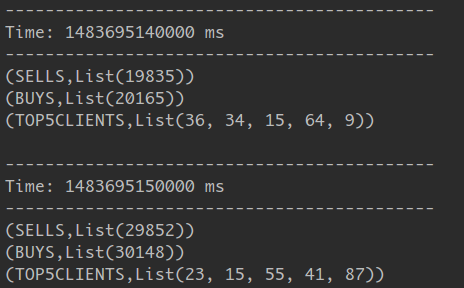
若要將這個小結果每次的輸出都寫入HDFS該怎麼做?
finalStream.repartition(1).
saveAsTextFiles("hdfs://localhost:9000/user/joechh/sparkDir/output/", "txt")
放這個只是要Demo,如果要存小檔案,可以考慮儲存前對RDD再次repartition再存。
[Snippet.42]mapWithState
Spark在1.6版時針對Spark Streaming導入新的函式mapWithState。與updateStateByKey的主要差別為mapWithState維護的狀態與回傳值可以不同。另外一大亮點就是DataBrick宣稱mapWithState效能較updateStateByKey大幅提升!(空間上多存10倍的鍵,執行速度快上6倍):
Faster Stateful Stream Processing in Apache Spark Streaming
mapWithState的使用方式與updateStateByKey很類似,都需傳入一個函式(StateSpec類別)。快來看看這個函式必要的輸入與輸出吧:(KeyType, Option[ValueType], State[StateType]) => Option[MappedType]
Option包起來KV,也就是(Key,State))開始吧!,將之前updateStateByKey用的函式換成mapWithState的!
val updatePerClient = (clientId: Long, amount: Option[Double], state: ① State[Double]) => {
var total = amount.getOrElse(0.toDouble) ②
if (state.exists()) ③
total += state.get()
state.update(total) ④
Some((clientId, total)) ⑤
}
① 宣告K為Long型別,V為Option[Double]型別,狀態為State[Double]
② 從狀態中取值(使用getOrElse),若沒有則回傳0
③ 若狀態存在則讀取並與現值(total)加總
④ 用total更新狀態值
⑤ 回傳(key,state)的KV,並用Some包成Option
建好函式了,那要怎麼透過mapWithState用呢?
val amountState = amountPerClient.mapWithState(StateSpec.function(updatePerClient)).stateSnapshots()
要用StateSpec Object的函式function呼叫,而stateSnapshots的作用是為紀錄每個批次中,每個K最新的V值,放個官方解釋圖就會比較清楚了:
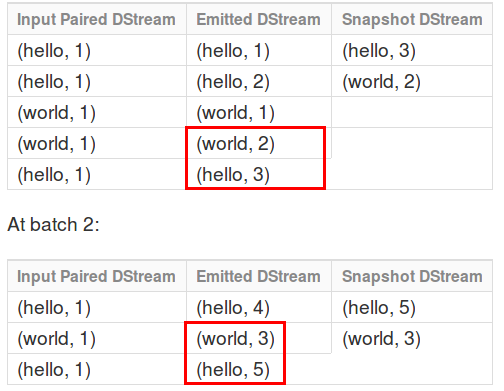
這樣我的amountState處理完每次個批次都可以拿到每個K最新的V啦。mapWithState還有一些額外的參數可以帶入,例如timeout機制等。


