但如果程式前兩篇實作的程式碼,寫在同一份程式碼,本段無須執行喔!
#
#library(httr)
library(xml2)
#
web.url="https://join.gov.tw"
wdpath=paste0(getwd(),"/Documents/GitHub/R_DayOfDataEnginner-2018/")
#[讀取]根據第一層資料,讀出第二層位置 並置入dfl dataframe備用
dfl<-read.csv(paste0(wdpath,"/dscsv/pagelist.csv"))
第二層的重點在抓下公民參與議題的討論紀錄檔,這部分,是透過爬取下載按鈕對應的下載連結來實作。
#給定第二層所需下載按鈕的xpath
pxpath <- "/html/body/div/div/h5/button[1]"
這部分有另外處理iscsv的部分,用以實作部分沒有人留言的議題,也就沒有csv,若不進行處理,後續將有議題與內容對應的問題。
#[讀取]迴圈逐一讀取第二層資料
for (j in 1:nrow(dfl)) {
#爬出該按鈕對應的下載網址 指定為flink
pdoc <- read_html(toString(dfl[j,"href"]))
pdoc<-xml_find_all(pdoc,pxpath)
flink<-paste0(web.url,xml_attr(pdoc, "data-exporturl"))
flink跟web.url筆,有csv連結的會壓TRUE
iscsv<-nchar(flink)>nchar(web.url)
迴圈處理按鈕的下載網址列,要記得要踩停。本例一則至少睡兩秒,500多筆至少要20分鐘左右。
# 並放入dff中備用
if (j==1){
dff<-data.frame(j,flink,iscsv)
}else{
dff <- rbind(dff, data.frame(j,flink,iscsv))
}
#照樣要稍稍暫停 這部分計有500多份網頁要進 要注意
Sys.sleep(runif(1,2,3))
}#迴圈結束
稍早用少量樣筆數,未踩停車,就有被網站ben掉!
dfl記錄得是第二層資料 再增補上下載連結資料
dfl<-cbind(dfl, dff)
#檢查一下資料
View(dfl)
是否落地可自行考慮
## write your table to file
write.table(dfl, file=paste0(wdpath,"/dscsv/downlist.csv"),sep=",",row.names=FALSE)
[讀取]迴圈讀取下載連結位置durl,並將下載檔案名,定義為序號.csv
for (k in 1:nrow(dfl)) {
#for (k in 1:5) {小量練習用
稍早的iscsv派上用場
if (dfl[k,"iscsv"]==TRUE){
dlurl <- toString(dfl[k,"flink"])
destfile <- paste0(wdpath,"dscsv/download/",toString(k),".csv")
download.file(dlurl, destfile, mode="wb")
#照樣要稍稍暫停 這部分計有500多份檔案要下載要存,請注意
Sys.sleep(runif(1,1,3))
}
} #k 迴圈結束
共計有500多筆檔案,其中16.csv從缺,表示無csv,不進行處理
[讀取]以迴圈方式,將下載回來的csv逐一取出
for (m in 1:nrow(dfl)) {
#for (m in 1:5) { 小量練習
if (dfl[m,"iscsv"]==TRUE){
tempdfl<-read.csv(paste0(wdpath,"dscsv/download/",toString(m),".csv"))
#加入m作為編碼,並藉此將第一層與第二層的資料連結
tempdfl<-cbind(m,tempdfl)
if (m==1){
rowdfl<-tempdfl
}else{
rowdfl<-rbind(rowdfl,tempdfl)
}
}
}#m 迴圈結束
定義欄名(當然也可等到最後再做)
colnames(rowdfl) <- c("issueid", "aid","adatetime","city","area","nname","reason")
#檢查一下資料囉!
View(rowdfl)
處理結果如下圖: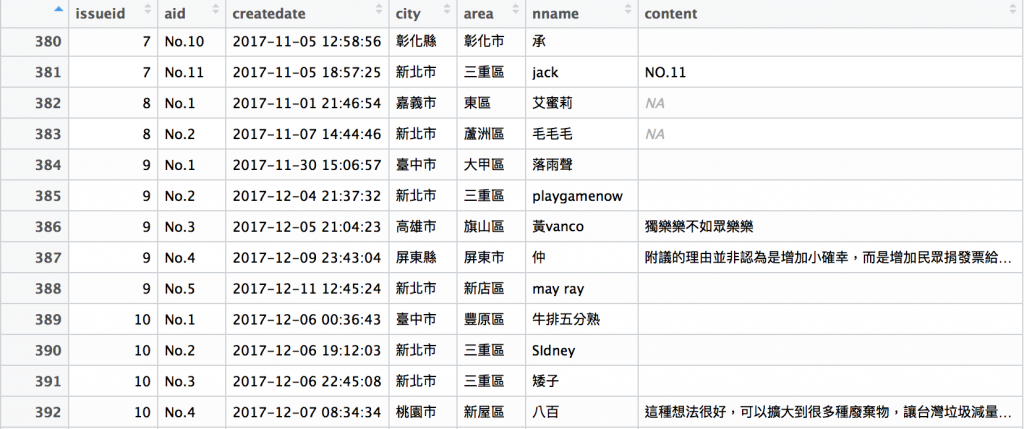
欄位說明:
issueid:對應到第一層的議題代碼
aid:對應到本篇留言序號代碼
createdate:留言時間
city:留言者城市
area:留言者行政區
nname:留言者姓名
content:留言內容


