Kafka可以說是目前大數據架構中的標準技術之一了,比如SMACK這個目前主流的大數據即時處理架構中的5個技術,Spark, Mesos, akka, Cassendra, Kafka,就包含在其中。這篇就簡單的帶大家了解一下Kafka是什麼。
Kafka是由LinkedIn開發的一個分布式的Message System, 由Scala實作,它具備有水平擴充和高吞吐量的能力,而隨著新版Stream功能的加入,將自已定位為一個分散式串流平台(distributed streaming platform),來提供實時資料串接(real-time pipeline)。
1 以Time Complexity O(1)的方式提供消息持久化能力,對TB級的資料持久化,也能保持高效
2 在一般商用機器上,也能達到每秒100k以上的訊息處理量
3 保證partition上的訊息順序
4 支援實時和離線資料處理
5 支援水平擴展,但只能加大,不能縮小
6 不支援JMS和事務
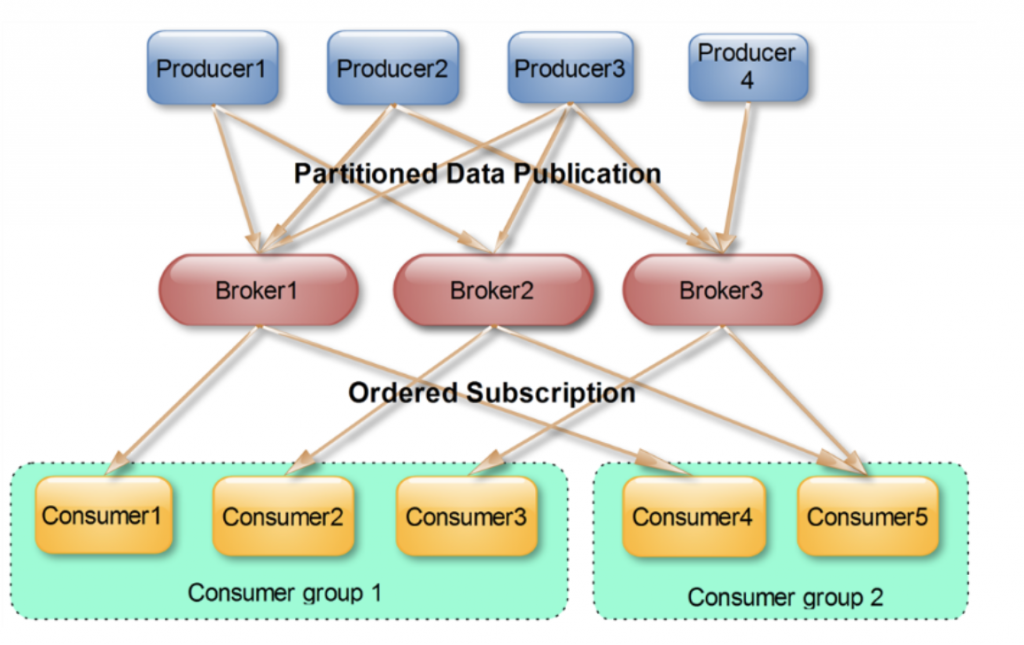
Broker
可以簡單的視為Kafka cluster中的機器設備,另外會使用ZooKeeper來進行資源的管理
Topic
簡單的說訊息的發收和接收時需要指定的類別,可以視為是Queue的概念
Partition
會將Topic上的訊息切割成多個Partition,為一個實際使用的空間
Producer
負責發布訊息到Kafka
Consumer
訊息消費者,將訊息由Kafka讀出,要注意的是一個Partition只能被一個Consumer讀取,所以比較好的設計是將Partition的數量設得比Consumer多
Consumer Group
每個Consumer屬於一個特別的Consumer Group
Leader and Follower
Leader是該Partition的資料讀寫最優先者
而Follower會同步Leader的資料,當作是備援,來達到高可用性
Official Website
Kafka剖析(一):Kafka背景及架构介绍
Apache Kafka Tutorial



 iThome鐵人賽
iThome鐵人賽