可惜第6天中斷了,不過我還是會盡我最大的努力完成30篇了。
雖然大數據處理不算是Kaggle解題的一部分,但在實際應用上,也算是正相關的技術。
1 下載Kafka 1.0最新版本,並解壓縮
https://www.apache.org/dyn/closer.cgi?path=/kafka/1.0.0/kafka_2.11-1.0.0.tgz
tar -xzf kafka_2.11-1.0.0.tgz
cd kafka_2.11-1.0.0
2 啟動Zookeeper
bin/zookeeper-server-start.sh config/zookeeper.properties

3 啟動Kafka
bin/kafka-server-start.sh config/server.properties
4 建立和查詢Topic test
新增Topic
bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic test
查詢Topic
bin/kafka-topics.sh --list --zookeeper localhost:2181

5 傳送和接收訊息
傳送訊息
bin/kafka-console-producer.sh --broker-list localhost:9092 --topic test
接收訊息
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test --from-beginning

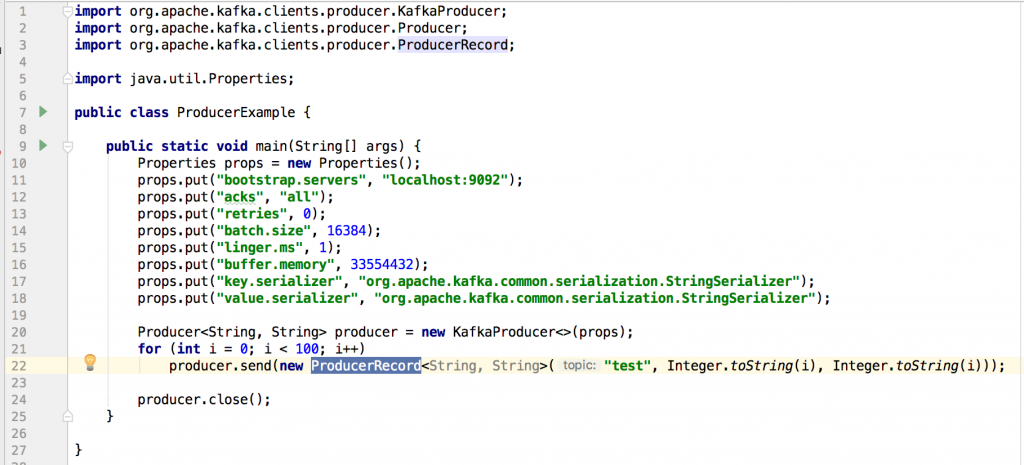
第10-18行,主要就是設定Produce的properties,第20行,建立Kafka Producer,第21-22行,發送100則訊息到指定的topic,produce是thread safe的,因此,在實際開發時,使用單一個instance也比較有效率,第24行為關閉producer。
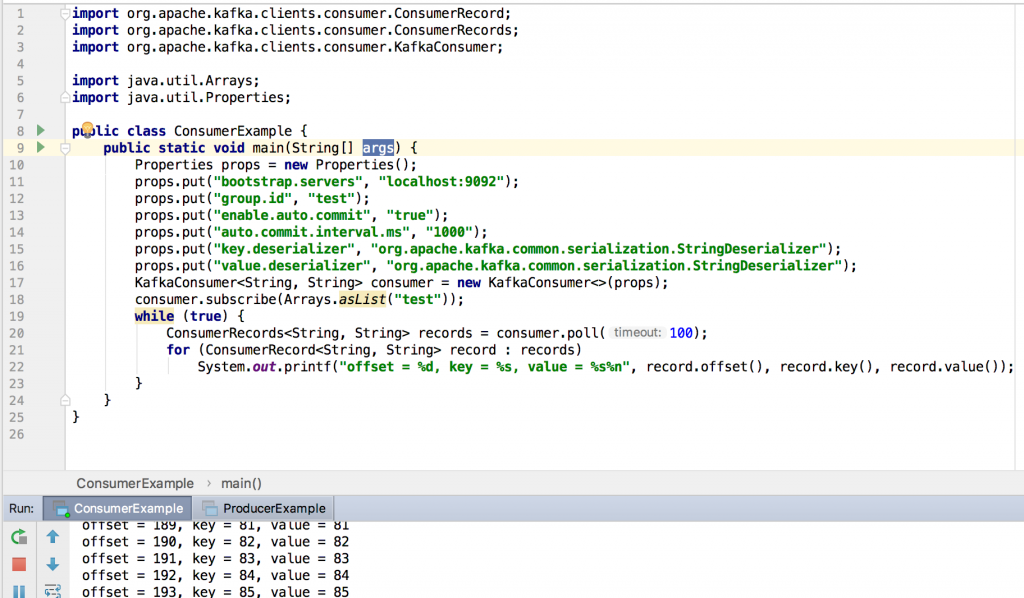
第10-16行,設定properties,第17行,建立Kafka Consumer,第19-23行,為不斷的接收訊息並將其印出,第20行,為取得資料並等待100 ms。
我並沒有實作到cluster和新的connection和stream的功能,因為就官網上的例子,還蠻簡單的,但,我想比較符合production的應用是如果部署幾百台和進立設備監控,但這又有點偏Devops,暫時先跳過,各位有興趣的可以自行研究,另外,其實我沒有鑽太多底層的觀念,有些觀念其實也還蠻重要的,有興趣的人可以看我的參考資料,至少要知道partition如何達到分佈式這式,其實我後來才懂的,明明有不少東西是可以建cluster的,那為何還要使用某些大數據的技術,其實就是機器數量上的差異,使用Kafka是可以到上萬台的設備的。



 iThome鐵人賽
iThome鐵人賽