ImageNet 每年舉辦的競賽(ILSVRC)這幾年產生了不少的CNN冠軍,歷屆比賽的模型演進非常精彩,簡單敘述如下:
Keras把它們都收錄進框架內,稱為Keras Applications ,包括下列幾項:
它們的模型結構資訊如下表: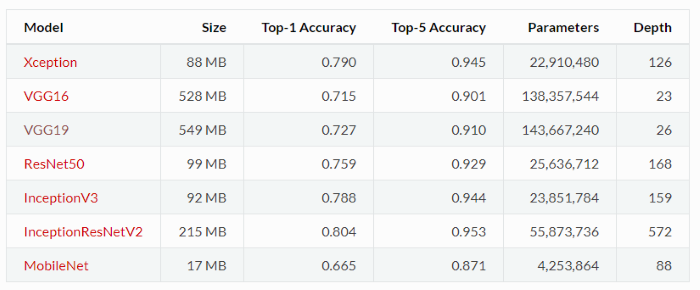
註:
除了 Xception and MobileNet,其他的Applications都與 TensorFlow 及 Theano 相容,我們就挑 VGG16 為例子,解釋如何使用。這些模型的隱藏層數都很多,也使用了大量的資料作訓練,一般電腦可能要執行很久,等結果可能要很多輪的咖啡XD,因此,Keras將研發團隊精心調校的模型及執行結果收集進來,一般使用者就不用自
己訓練模型,可以直接套用,故稱為預先訓練的模型(pre-trained models)。
由於,這些模型使用了大量資料作訓練,且使用非常多層的處理,例如 VGG 使用ImageNet 100萬張圖片,共 1000 種類別,幾乎涵蓋日常生活看到的事物,例如動物、交通工具...等,訓練出來的模型,就變成一種『通用解決方案』(Generic Solution),如果要辨識照片內事物屬於這1000類,例如貓、狗、大象等,就可以直接拿VGG模型來用了,反之,如果,要辨識的內容不屬於1000類,也可以換掉input卷積層,只利用中間層萃取的特徵,這種能力稱為『Transfer Learning』,比較嚴謹的定義如下:
Transfer learning allows you to transfer knowledge from one model to another. For example, you could transfer image recognition knowledge from a cat recognition app to a radiology diagnosis. Implementing transfer learning involves retraining the last few layers of the network used for a similar application domain with much more data. The idea is that hidden units earlier in the network have a much broader application which is usually not specific to the exact task that you are using the network for. In summary, transfer learning works when both tasks have the same input features and when the task you are trying to learn from has much more data than the task you are trying to train.
資料來源:Deep Learning Specialization by Andrew Ng — 21 Lessons Learned
VGG 是英國牛津大學 Visual Geometry Group 的縮寫,主要貢獻是使用更多的隱藏層,大量的圖片訓練,提高準確率至90%。VGG16/VGG19分別為16層(13個卷積層及3個全連接層)與19層(16個卷積層及3個全連接層),結構圖如下。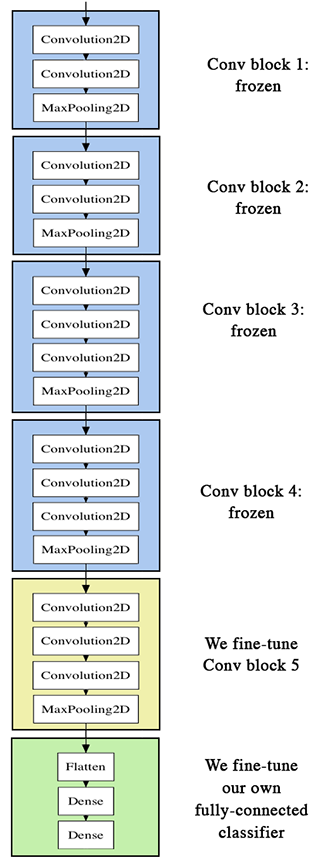
圖. VGG16 結構圖,圖片來源:Building powerful image classification models using very little data
圖. VGG19 結構圖,圖片來源:Applied Deep Learning 11/03 Convolutional Neural Networks
乍看到 Keras 的官方文件 ,就傻眼了,竟然只有寥寥一頁,除了參數說明,沒了!! 花了一整天的搜尋,總算搞懂怎麼用,迫不及待的想跟大家分享。
所有Applications執行都只要一行指令,就可以把模型及權重載入程式中,例如,載入VGG16的指令如下:
model = VGG16(weights='imagenet', include_top=True)
相關參數說明:
如果你不用Applications,要自己寫也很簡單,程式碼如下:
from keras.models
import Sequential
from keras.layers import Dense, Activation, Dropout, Flatten
from keras.layers import Conv2D
from keras.layers import MaxPooling2D
input_shape = (224, 224, 3)
model = Sequential([
Conv2D(64, (3, 3), input_shape=input_shape, padding='same',
activation='relu'),
Conv2D(64, (3, 3), activation='relu', padding='same'),
MaxPooling2D(pool_size=(2, 2), strides=(2, 2)),
Conv2D(128, (3, 3), activation='relu', padding='same'),
Conv2D(128, (3, 3), activation='relu', padding='same',),
MaxPooling2D(pool_size=(2, 2), strides=(2, 2)),
Conv2D(256, (3, 3), activation='relu', padding='same',),
Conv2D(256, (3, 3), activation='relu', padding='same',),
Conv2D(256, (3, 3), activation='relu', padding='same',),
MaxPooling2D(pool_size=(2, 2), strides=(2, 2)),
Conv2D(512, (3, 3), activation='relu', padding='same',),
Conv2D(512, (3, 3), activation='relu', padding='same',),
Conv2D(512, (3, 3), activation='relu', padding='same',),
MaxPooling2D(pool_size=(2, 2), strides=(2, 2)),
Conv2D(512, (3, 3), activation='relu', padding='same',),
Conv2D(512, (3, 3), activation='relu', padding='same',),
Conv2D(512, (3, 3), activation='relu', padding='same',),
MaxPooling2D(pool_size=(2, 2), strides=(2, 2)),
Flatten(),
Dense(4096, activation='relu'),
Dense(4096, activation='relu'),
Dense(1000, activation='softmax')
])
model.summary()
我們就來看一支範例程式,我們使用include_top=True,全盤採納VGG16模型,僅改變輸入為一張圖片(tiger.jpg),程式碼如下,我在程式中加了註解,請參考這裡 ,本範例為vgg16.py:
from keras.applications.vgg16 import VGG16
from keras.preprocessing import image
from keras.applications.vgg16 import preprocess_input, decode_predictions
import numpy as np
# include_top=True,表示會載入完整的 VGG16 模型,包括加在最後3層的卷積層
# include_top=False,表示會載入 VGG16 的模型,不包括加在最後3層的卷積層,通常是取得 Features
# 若下載失敗,請先刪除 c:\<使用者>\.keras\models\vgg16_weights_tf_dim_ordering_tf_kernels.h5
model = VGG16(weights='imagenet', include_top=True)
# Input:要辨識的影像
img_path = 'tiger.jpg'
#img_path = 'elephant.jpg'
img = image.load_img(img_path, target_size=(224, 224))
x = image.img_to_array(img)
x = np.expand_dims(x, axis=0)
x = preprocess_input(x)
# 預測,取得features,維度為 (1,7,7,512)
features = model.predict(x)
# 取得前三個最可能的類別及機率
print('Predicted:', decode_predictions(features, top=3)[0])
幾點心得整理如下:
from keras.utils import plot_model
plot_model(model, to_file='model.png')
# 從頂部移出一層
model.layers.pop()
model.outputs = [model.layers[-1].output]
model.layers[-1].outbound_nodes = []
# 加一層,只辨識10類
from keras.layers import Dense
num_classes=10
x=Dense(num_classes, activation='softmax')(model.output)
# 重新建立模型結構
model=Model(model.input,x)
我又做了幾個有趣的實驗:

圖. 『熊讚』,圖片來源:熊讚爆紅升格市府吉祥物 前進雙橡園
圖. 『熊讚與狗』,圖片來源:陽明山那場雪救了「熊讚」 狂刷存在感屢創熊式奇蹟
我們如何選擇要用哪一個預先訓練的模型? 請參考下圖,它列出各種模型運算次數與準確度的比較,圓圈大小是參數的多寡,我們可以根據問題的型態與運算資源的多寡,來決定使用哪一個預先訓練的模型。另外,我喜歡它的標題『Standing on the shoulders of giants』,使用預先訓練的模型就是站在巨人的肩膀上,沒有龐大資源,也可以有變通之道。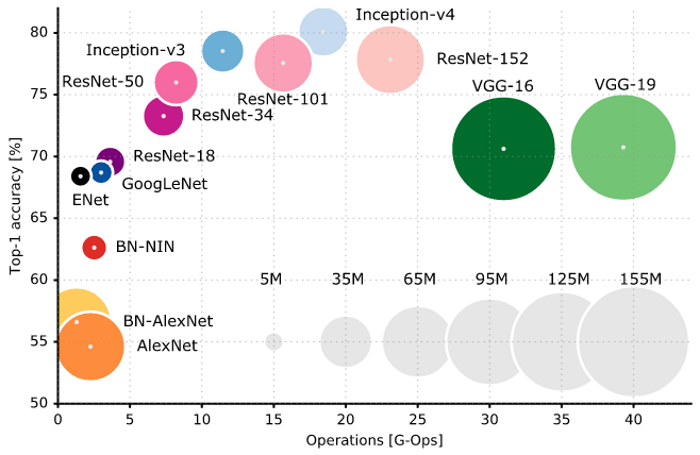
圖. 各種預先訓練模型的比較,圖片來源:Learning Deep Learning with Keras
VGG 19 與 VGG16 類似,只是它更多層,在後續篇章的『風格轉換』(Style Transfer)中會使用到。下一篇,我們繼續使用 VGG16 套用在照片相似度的比對上,說明如何找出相同主題的照片,也讓我們更熟悉如何活用這些Applications。
您好,我是初學機器學習,請問一下:
model = VGG16(weights='imagenet', include_top=False),就要加頂部三層。(一定要三層嗎?)
那您在 9.要改變ouput的分類法中
為什麼得先pop掉一層,才再加入新的一層(分成10類) (一定要先pop嗎?)
那這樣您在頂部並沒有加回三層?
謝謝您。
1.想請問下面這兩行是甚麼意思,因為我有看到原本程式碼已經有pop拿掉最後一層了
model.outputs = [model.layers[-1].output]
model.layers[-1].outbound_nodes = []
2.想問下面這行是在多+一層然後把這層跟原本的mdoel.output再連接再一起嗎?
x=Dense(num_classes, activation='softmax')(model.output)
您好!請問 pretrain 好的 vgg 可以用到 residual block 裡,並用 feature map 當做 loss function ,來做超分辨率這個 task 嗎?謝謝!
基本上神經網路是個黑箱科學,模型怎麼構建都可以,只要實證有效,而且言之成理。Keras(https://keras.io/api/layers/)提供許多內建的神經層,也允許自訂神經層。



 iThome鐵人賽
iThome鐵人賽