前兩篇我們介紹了CNN的概念及程式撰寫方式,有幾點要再強調:
以上就是各種隱藏層堆疊的原則,之後再觀摩幾個經典的模型,就比較清楚隱藏層的安排順序與原則。
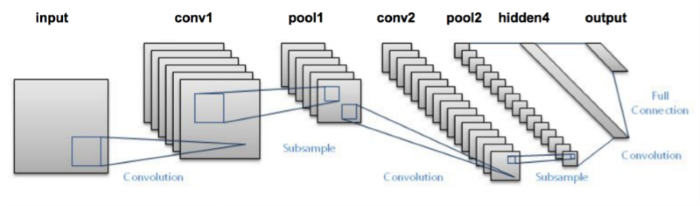
除了全連接階層(Dense)外,CNN隱藏層分為下列幾類:
下面我們就詳細說明各層的參數。
Keras 提供的卷積層又分為幾個小類:
重要的參數說明如下:
其他參數用法與一般的 Neural Network 相同,請看 『Day 05:模型參數說明』介紹。
池化層(Pooling Layer) 又分為幾個小類:
重要的參數說明如下:
經過以上介紹,你應該會有很多疑問,究竟CNN要設幾層? Filters要設多少? 卷積核要設多大? strides要設多大? 根據我目前找到的答案是,『多加實驗,找到最佳值』,如果是真的,難怪連大師都說『Neural Network』的結果是很難對一般人解釋清楚的。我喜歡前百度首席科学家、史丹佛大學副教授吳恩達下面這段評論:
Deep Learning has also been overhyped. Because neural networks are very technical and hard to explain, many of us used to explain it by drawing an analogy to the human brain. But we have pretty much no idea how the biological brain works.
資料來源:What does Andrew Ng think about Deep Learning?
下一次我們就看看一些很成功的CNN模型,觀摩他們的模型設計,並且研究如何使用他們的模型,來實作各種應用。也作一些簡單的實驗,與時事作結合,實驗『太陽花看成香蕉』的機率有多少呢?
老師我想請問kernelsize是只能定義3X3還是也可以定義5X5或7X7,如果這應定義會有什麼效果差異呢
kernel size 可以設定各種尺寸,以直覺來看,取較大的kernel,可抓取較大的特徵,取較小的kernel,可抓取較小的特徵。進階的模型如YOLO,他們會取大小不同的candidate box.
了解謝謝老師


