tidyverse套件集裡的readr套件,目的在處理資料來源的匯入,當然如有其他xml等資料要處理,就需要搭配xml2或是XML套件。
#準備工作
#install.packages("tidyverse")
library(readr)
先來看看將資料寫成檔案存放部分
#先做個dftemp的當作例子
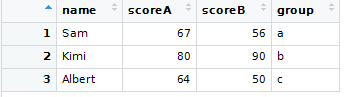
dftemp <- data.frame(
name = c("Sam", "Kimi", "Albert"),
scoreA = c(67, 80, 64),
scoreB = c(56, 90, 50),
group = letters[1:3]
)
#Save2File
#Comma delimited
##filewrite_csv(x, path, na = "NA", append = FALSE,col_names = !append)
write_csv(dftemp,path="D:/Users/Desktop/write2csv.csv")
#File with arbitrary delimiter
##write_delim(x, path, delim = " ", na = "NA",append = FALSE, col_names = !append)
write_delim(dftemp,path="D:/Users/Desktop/writedelim.csv",delim = "~")
#CSV for excel
##write_excel_csv(x, path, na = "NA", append =FALSE, col_names = !append)
write_excel_csv(dftemp,path="D:/Users/Desktop/write2excelcsv.csv")
write_csv跟write_excel_csv並無差別。
先來看看有表格樣式的原始資料處理(Tabular Data),這部分的概念,如各位日常使用Excel 作業處理資料匯入時的概念與處理,幾乎是完全一致的。
#Read Tabular Data
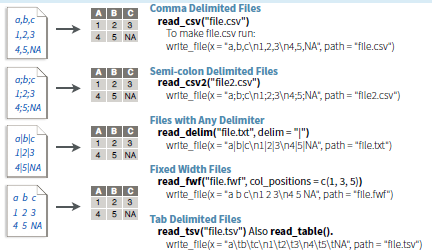
##讀入逗號分隔號分隔的檔案Comma Delimited Files
write_file(x = "a,b,c\n1,2,3\n4,5,NA", path = "file.csv")
read_csv("file.csv")
##讀入分號分隔號分隔的檔案Semi-colon Delimited Files
write_file(x = "a;b;c\n1;2;3\n4;5;NA", path = "file2.csv")
read_csv2("file2.csv")
##讀入使用分隔號分隔的檔案Files with Any Delimiter
write_file(x = "a|b|c\n1|2|3\n4|5|NA", path = "file.txt")
read_delim("file.txt", delim = "|")
##讀入使用固定欄位寬度分隔的檔案Fixed Width Files
write_file(x = "a b c\n1 2 3\n4 5 NA", path = "file.fwf")
read_fwf("file.fwf", col_positions = c(1, 3, 5))
##讀入使用Tab分隔的檔案Tab Delimited Files
write_file(x = "a\tb\tc\n1\t2\t3\n4\t5\tNA", path = "file.tsv")
read_tsv("file.tsv")
讀檔時重要的參數補充!
#USEFUL ARGUMENTS
#範例:Example file
write_file("a,b,c\n1,2,3\n4,5,NA","file.csv")
f <- "file.csv"
#宣告此資料來源,無欄位,第一欄就是資料,非欄名。No header
read_csv(f, col_names = FALSE)
#給定欄位名稱 Provide header
read_csv(f, col_names = c("x", "y", "z"))
#給定跳過處理哪一行 Skip lines
read_csv(f, skip = 1)
#給定處理資料筆數 Read in a subset
read_csv(f, n_max = 1) #Maximum number of records to read.
#直接給定Missing Values
read_csv(f, na = c("1","3"))

#比較一下
write_csv(dftemp, path = "D:/Users/Desktop/fileX.csv")
x<-read_csv("D:/Users/Desktop/fileX.csv")
y<-read.csv("D:/Users/Desktop/fileX.csv")
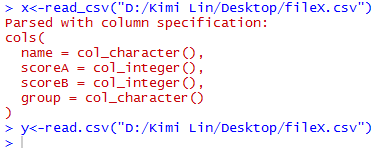
發現到使用read_csv需要給定欄位type。(想偷懶的話就用read.csv)
x<-read_csv("D:/Users/Desktop/fileX.csv");problems()#problems()展開問題對話
#根據建議,把資料補上
x<-read_csv("D:/Users/Desktop/fileX.csv", col_types = cols(
name = col_character(),
scoreA = col_integer(),
scoreB = col_integer(),
group = col_character()
))
#看看結果囉
View(x)