監督式、非監督式
因為前幾篇有講到機器學習,好像有朋友想理解,所以就跨領域發篇機器學習。先回顧一下前幾篇講的重點。我們知道機器學習有分成所謂的(監督式、非監督式、半監督式、強化學習等)學習方面
我們做網安的人員不外乎就是要學習怎麼去看封包,但是我們人類在看封包總不可能長時間的坐在電腦前盯著螢幕對吧 !
但也不完全是人在看封包,因為我們有所謂的安全防線,俗稱一二三道防線。例如說我們現在常用的IDS(入侵偵測系統)就是利用所謂的樣本參照。
雖然已經有IDS這套優良的系統,但是我們知道駭客總是比較厲害,總是會利用一些我們不知道的攻擊。而機器學習的出現不外乎就是讓機器可以像我們人一樣可以具有觀察封包、學習人的行為、了解所謂的規則、並且利用規則在自我訓練,最後藉由我們人類給他的指令(原始碼)來變得更聰明。
例如AlphaGo為例子,AlphaGo也不是一開始就很厲害的,也是利用所謂的機器學習,藉由一場接著一場的比賽,從失敗中的經驗獲取知識,再把這個知識拿來學習,就是學習別人當下的知識、以及改善別人過去的知識在判斷當下怎麼下棋,所以現今的AlphaGo才用有如此厲害的棋藝。
監督式、非監督式
今天先來提監督式、非監督式,我們在網安上是怎們運用機器學習裡的監督式、非監督式學習的呢。
其實原理很簡單,我們只要告訴機器所謂的標籤『Lable』再叫他做事(規則)就是可以。例如:有標籤的樣本稱 : 顯性封包 、 無標籤的樣本稱 : 隱性封包。
說白話一點。監督式學習就是面對一個問題時你要告訴機器正確答案是什麼。
如左圖。我們告訴機器白色的為顯性,機器就會判為顯性。
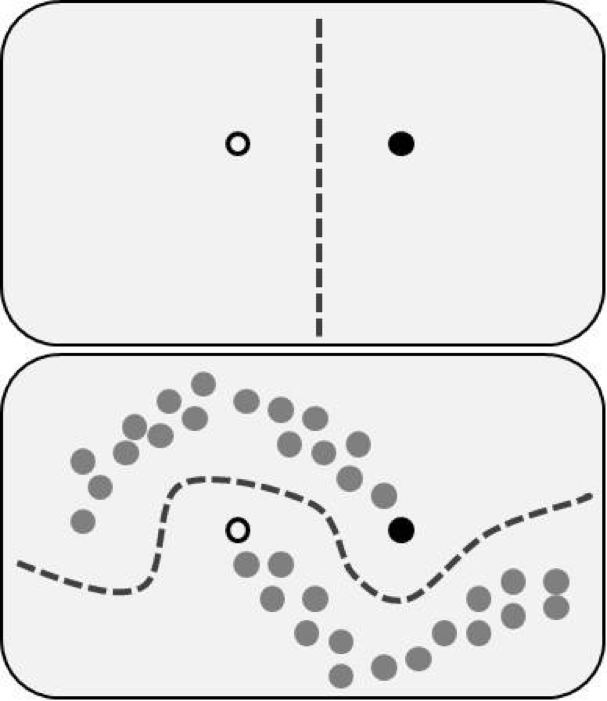
但是非監督式學習比較不一樣,因為非監督式訓練我們不需要給機器標籤『Lable』,我們只需要給機器規則,告訴機器怎麼分類就夠了。但有人會問為什麼不用監督式學習就好,其實不盡然,非監督式之所以被提出的原因就是為了要解決一些沒辦法用固定答案回答的情況,例如:棋盤的正解、汽車路線規劃、天氣的預測、網路封包密度。
備註:圖片僅提供參考,謝謝


