昨天先稍微介紹了一下要如何才能從封包中把檔案擷取出來,今天就來實做給大家看看。
我們需要先創造一些包含檔案的封包,這樣才有辦法實作從封包裡把檔案拿出來,因此我使用了一些Google的搜尋技巧,從網路上找幾個看起來應該沒問題的檔案下載下來,並同時收取流量。
首先一邊開始用Wireshark收流量,一邊在Google搜尋列打上「filetype:docx site:"*.gov.tw"」,以找到存在政府單位網站中的docx檔案,並從之間隨便選一個看起來比較沒問題,而且是使用HTTP連線的檔案下載,記得不要找HTTPS的,因為流量會被加密就看不出來了。搜尋結果如下圖,就隨便點個第一個docx結果吧,就是你了,「106年高普考基訓測驗說明 - 國家文官學院」,而檔名則叫做「2eb9f7e87f8dc5054f7e66c83e841a86.docx」。
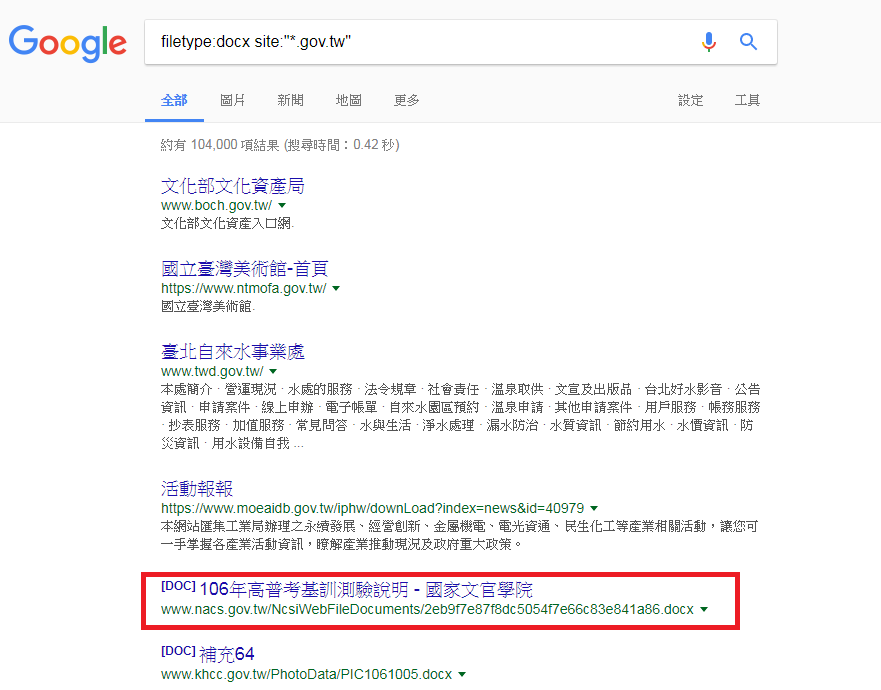
接著打開檔案看看,文件內容長得跟下面一樣。

接下來,我們回到剛剛所收到的封包,並在規則欄輸入http,以過濾http的封包,得到的封包列表如下。
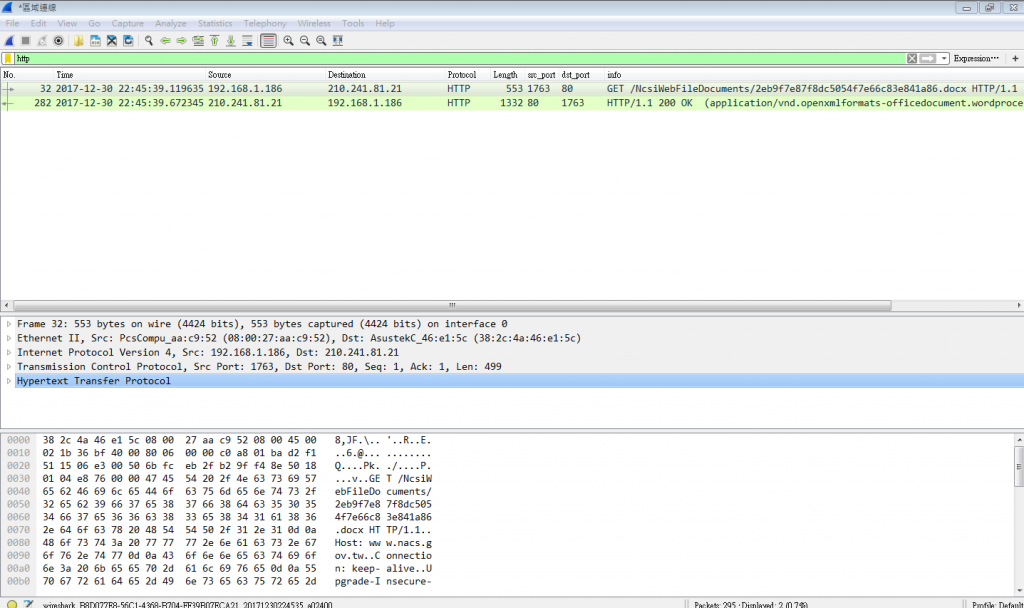
而從Info欄位也看得出這個封包就是我們剛剛下載檔案的封包。

接著,在第一個封包按下右鍵,並選取Follow>TCP Stream,就會顯示剛剛從點選下載連結到把檔案下載下來這個過程的所有封包,同時也會以ASCII顯示所有封包的內容。
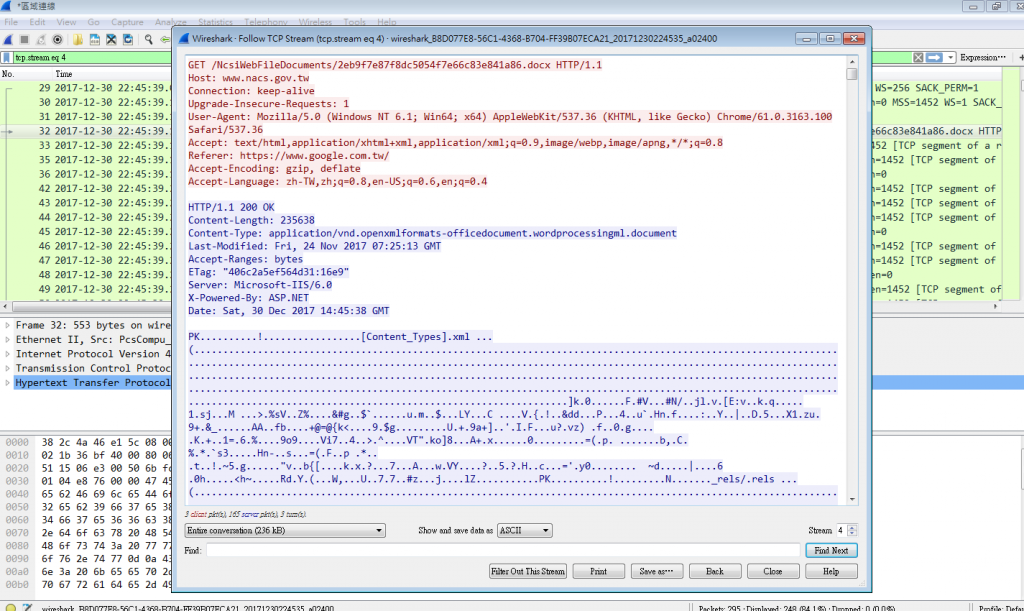
讓我們把ASCII的部分放大一點看,紅框跟藍框的部分是HTTP標頭(HTTP Header)的部分,其中紅框的地方是我向對方Server提出下載檔案的請求(HTTP Request),藍框的部分是對方Server的回覆(HTTP Response),下面綠框的部分則開始是下載檔案內容。為什麼可以判斷這段就是檔案內容呢?首先是因為剛剛的下載動作很單純,是直接從對方Server中把檔案下載下來,沒有額外的轉址或特殊的動作,另外則是昨天也曾經跟大家說過的,從ASCII看的話,docx檔案的開頭就會是PK,各位看看,綠框的一開始是不是就是PK呀?
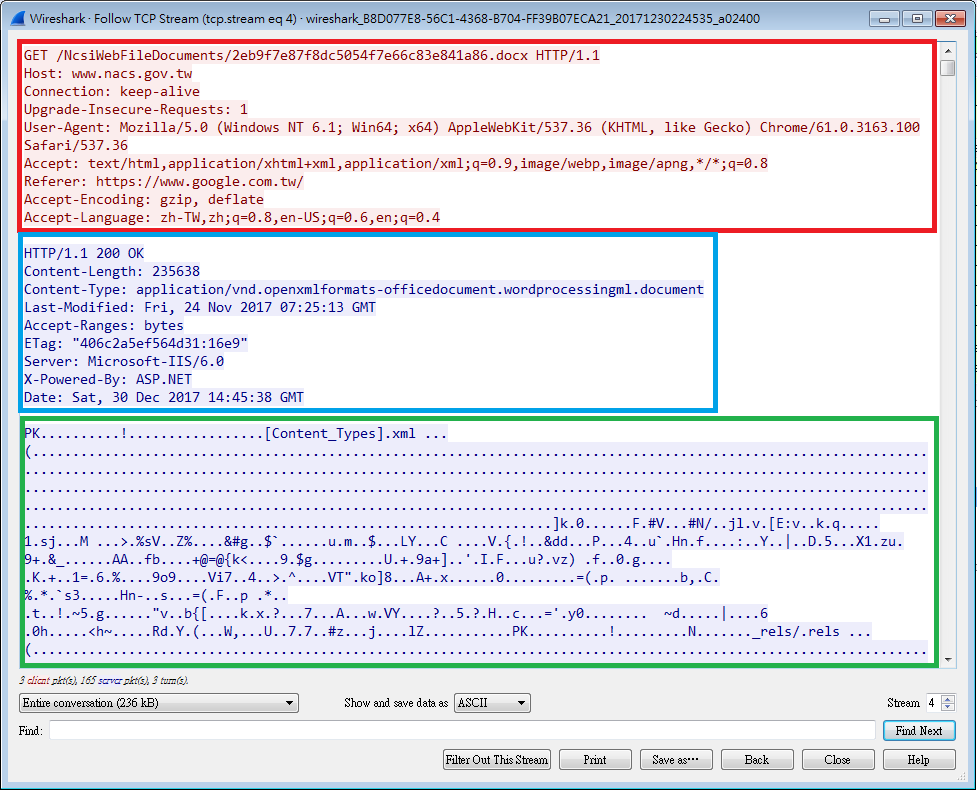
其實看上圖右邊的滑動捲軸就知道,綠框下面還有超級多的檔案內容是這邊沒有顯示出來的,那既然知道了檔案的內容是在封包的哪裡,那到底要如何把檔案複製出來呢?首先,把畫面下方Show and save data as的選項從原本的ASCII改成Raw,如下圖紅框處,這邊選擇Raw是因為要取得最原始的Hex Value,如果選擇其他類型的話,另存出來的內容因為經過多次轉譯過,可能會有點問題。選擇後上方的封包內容就會改變編碼方式,這時候再按下圖藍框處的Save as,存成隨便一個你喜歡的檔名,這邊還不用選擇副檔名,因為你這時候存下來的東西還不是正確的檔案,我的話是存成一個叫做test_data而且沒有副檔名的檔案。
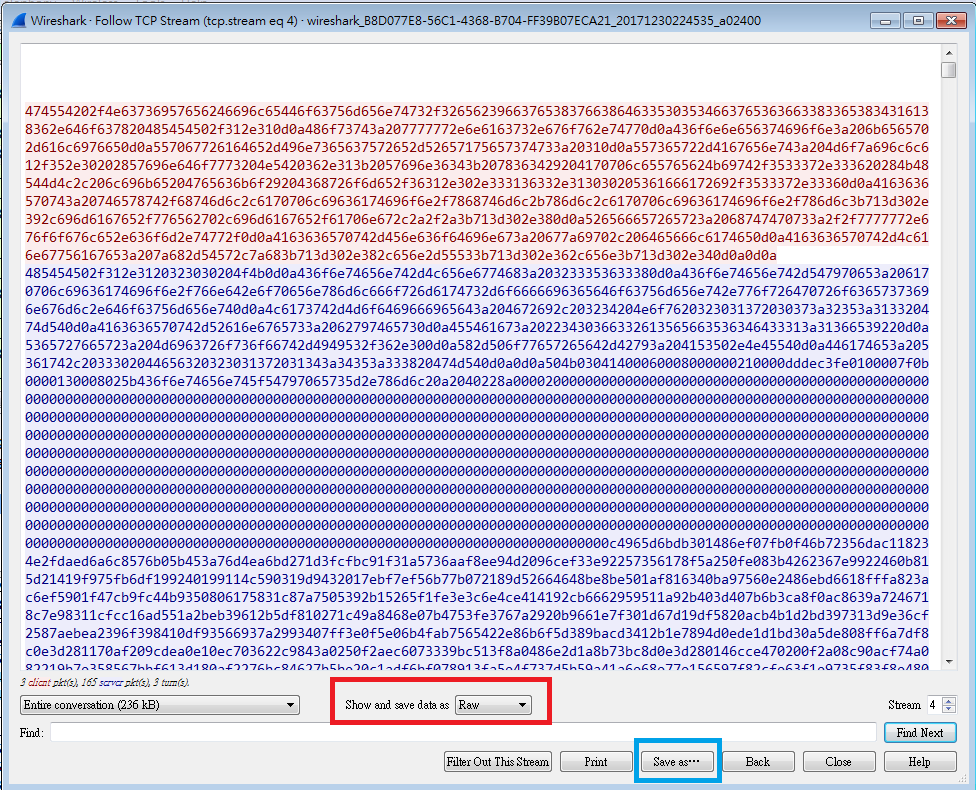
接著打開可以編輯Hex Value的編輯器軟體,例如昨天介紹過的那些,不過我使用的編輯器是叫做HxD(官方網站網址:https://mh-nexus.de/en/hxd/ ,官方下載網址:https://mh-nexus.de/en/downloads.php?product=HxD ),原因無他,唯手熟爾。
下一步,我用HxD把剛剛存的檔案test_data打開,得到的就是下圖的畫面,他除了會顯示原始的Hex Value,也會顯示對應的ASCII字元,而使用編輯器的原因是因為編輯器可以任意的編輯及刪減字元。如果你也使用HxD編輯器,預設一行只會顯示16組Hex Value(2個字元為1組),如果你跟我一樣嫌浪費版面,可以在下圖紅框的地方自行選擇一行要顯示幾組Hex Value看起來比較順眼。
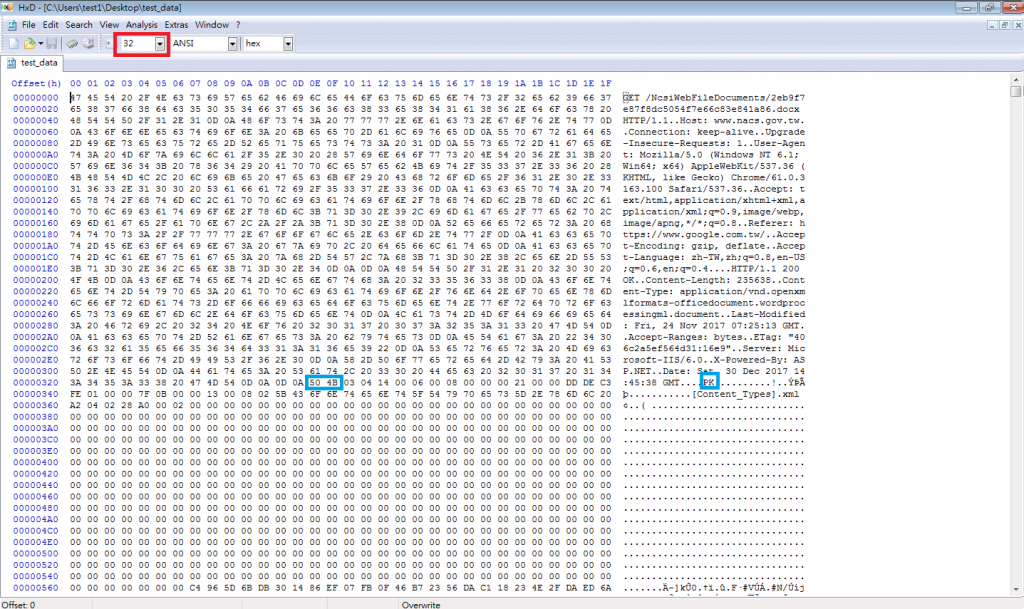
接著找到PK的部分,如上圖藍框的地方,你也可以選擇利用搜尋功能(Ctrl+F),輸入PK所對應的Hex Value,也就是50 4B,其他的選項則如下圖所示,接著按下OK就可以找到他在哪裡了。
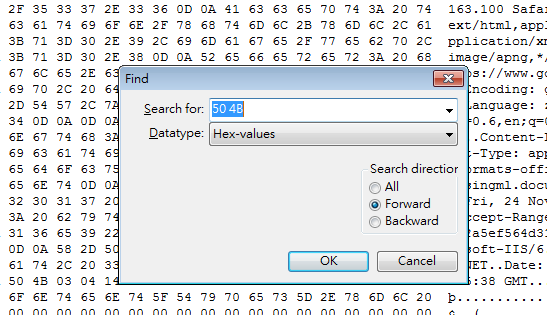
將PK以上的部分選取起來後,如下圖選取的範圍,按下delete刪除。

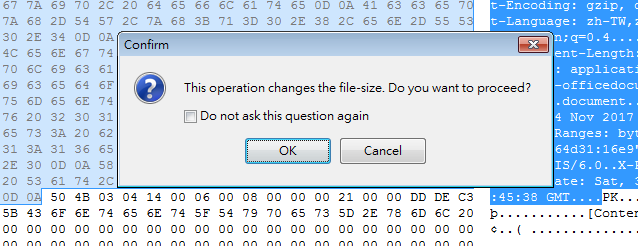
按下刪除時他可能會跳出這個警告視窗,只是想要提醒你,你刪除這些部分後會造成檔案大小有異動,不用管他按下OK就好了。
接下來把檔案另存新檔,並在檔名輸入xxx.docx,例如我是輸入test_data.docx。
刺激的一刻來了,這時如果點開test_data.docx會看到什麼呢?沒錯!我們成功的把檔案挖出來了!!而且長的跟原本的一模一樣,下圖紅框的地方也證明這是剛剛存起來的檔案。
只要用這個方法,同時知道檔案的開頭跟結尾在哪裡,就有辦法可以把檔案從封包中撈出來囉!另外,如果想知道其他格式的檔案在Hex Value中看起來是怎樣的話,也可以直接用HxD編輯器把檔案打開,就可以看到囉!
照著圖說一步步做真的可以抓出檔案耶!!!
唯手熟爾,我用的是Ultra Edit-覺得雀躍。
OK的,什麼工具都OK,熟練了什麼都是好工具!



 iThome鐵人賽
iThome鐵人賽