圖片來源: https://pixabay.com/en/books-spine-colors-pastel-1099067/ 和 https://pixabay.com/en/math-blackboard-education-classroom-1547018/
在上一篇([13]Data的運用 - 介紹篇)了解了整個Data Process Workflow會經過的每個步奏,並且了解到越前面的越重要
因此這篇將會從最重要的部分開始,怎麼定義一個好的問題?
同步發表於我的部落格:http://blog.alantsai.net/2018/01/data-science-series-14-how-to-define-good-question.html (部落格的格式會漂亮一些,ithome不支援html好不方便)
這個聽起來好像不是很難,但是定義明確的問題會讓後面的一些決定變得更加簡單。
舉例來說,假設今天我們的問題是:
預測飛機是否會準時到達?
感覺好像很明確了,就是要預測飛機的到達時間,但是如果深入往下想,這個其實還是他廣泛了:
全世界飛機那麼多,到底是要看哪裡到哪裡的飛機?這個非常重要,因為這個會決定第二個步奏裡面的收集資料的方式和方向。
舉例來說,如果今天預測的是美國的飛機,那麼就可以開始找關於美國方面的航班資料。
這個時候,會找到美國Department Of Transport(DOT)有提供資料是美國國內航班的實際起降時間
這個時候整個的問題變成:
使用從美國DOT取得到的資料,預測美國國內飛機是否會準時到達?
既然找到了資料來源,這個時候可以快速看一下DOT所提供的欄位有什麼。
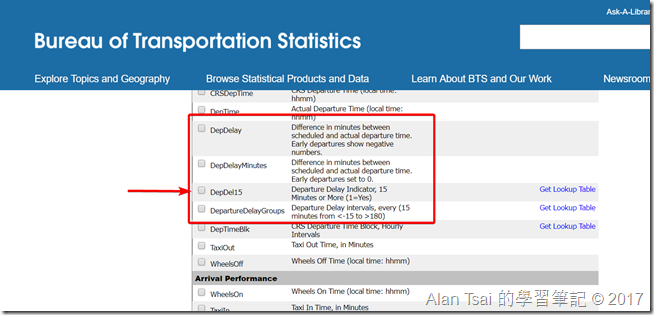
飛機遲到的欄位
從上圖會看到,其實裡面的欄位有幾個和是否延遲(delay)有關係,其中指出的那個是一個binary 欄位,如果延遲超過15分鐘,那麼就會是1,不然就是0。
所以,整個問題變成:
使用從美國DOT取得到的資料,預測美國國內飛機是否會延遲?
這個其實很重要,因為知道結果是0或1這種預測值,之後在Machine Learning選擇Algorithm就可以把一些例如預測數值的Algorithm剃掉。
接下來問題會變成,到底準確度到什麼程度是可以接受?也就是,多少預測失敗是可以接受?
一般來說,如果簡單一點,會從大約70%作為目標,因此整個的問題變成:
使用從美國DOT取得到的資料,預測精準度在70%以上,美國國內飛機是否會延遲?
到目前為止其實比一開始的問題明確,但是如果沒有跟著步奏走下來看的人其實還搞不懂這個情景是什麼。例如:怎麼樣叫做延遲?
所以整個問題可以調整變成:
使用從美國DOT取得到的資料,預測精準度在70%以上,美國國內飛機的降落時間是否會比預定的降落時間晚15分鐘?
到目前為止對於最終目標和資料取得的地方都明確了,不過對於怎麼到達最終結果並沒有定義的很清楚。
因此,以假設要建立Machine Learning的預測模型來做這個預測,那麼整個的問題變成:
透過整個Data Processing Workflow的流程,對從美國DOT取得到的資料做清理並且透過Machine Learning建立出預測模型,預測精準度在70%以上,美國國內飛機的降落時間是否會比預定的降落時間晚15分鐘?
如果把原本的問題和最後得到的問題做比較:
預測飛機是否會準時到達?
透過整個Data Processing Workflow的流程,對從美國DOT取得到的資料做清理並且透過Machine Learning建立出預測模型,預測精準度在70%以上,美國國內飛機的降落時間是否會比預定的降落時間晚15分鐘?
最後的問題很明確:
可以想象,有了這些明確目標,對於接下來Workflow的每個步奏有問題的時候都可以回來看。
例如,Exploratory Analysis階段的時候,可以盡量找可能和延遲有關的欄位,在Machine Learning的階段,會找和Supervised Learning有關的Algorithm(因為要建立的是預測模型),然後Algorithm是Binary Classification(因為結果是0或1代表延遲或沒有延遲)
上面有些詞目前還看不懂沒關係,因為後面都會介紹。
因此可以發現真的是越前面的階段越重要,因為失之毫釐,差以千里,因此也很用可能會在每個階段來來回回。
如果想一下,其實任何事情都是這樣,專案成不成功一開始的系統分析很重要,事業成不成功,和自己定義的Visio很重要,但是實際上這塊是最難做到的。
所以,真實情況是不可能一步到位,所以Agile為什麼現在這麼夯,重點是fail fast。
這篇希望透過一個很簡單的例子來帶出定義一個明確的問題有多重要,並且這個幫助會有多大。
當然,實際在run的過程可能沒辦法一次就定義這麼清楚,甚至有時候是模糊的,只是拿到一堆資料然後看看能不能找到什麼有趣的資訊。
這個也是Exploratory Analysis(探索性分析)在做的事情。
不過在實際進入Exploratory Analysis之前,要先介紹會用到的工具,R語言。
在下一篇將會快速介紹一下R語言的來源和怎麼準備好開發R。並且跑一個R的Hello World程式,用R來分析股票來看看R在分析上面的威力。
工商服務
今年的團隊機制不知不覺就集合了10位隊(坑)友 - 大家幫忙多多關注別不小心我們就gg了 XD
** 一群技術愛好者與一名物理治療師的故事 提醒著我們 千萬不要放棄治療 **
沉浸於.Net世界的後端工程師,樂於分享,現任台中Study4成員之一。除了程式以外,就愛看小說。
歡迎有任何問題或者建議都可以告訴我,可以再以下找到我:
部落格:Alan Tsai的學習筆記
我的Linkedin
我的粉絲頁
我的github
我的Slideshare
我的Twitter