圖片來源: https://pixabay.com/en/books-spine-colors-pastel-1099067/ 和 https://pixabay.com/en/math-blackboard-education-classroom-1547018/
還記得之前提到過,如果Data是原油那麼Data Science就是提煉成石油的技術。
到目前為止,解決了Data的儲存和運算的部分。但是就算可以處理Big Data,該怎麼處理?如何把處理結果變成有意義或者可以動作的策略?
如果說,Big Data的儲存和運算在武俠小說裡面屬於內功的話那麼Data Process Workflow(資料處理流程)就同等於招式一樣。
沒有足夠的內力(Data),招式在精妙也沒有用(就像瞎子摸象,就算摸的技巧再好,也因為局限的關係摸不到全貌,一定會有偏頗)。
反過來說,如果內力深厚,但是不會招式,那麼同等於英雄無用武之地。
在這個系列的接下來將會著重在介紹Data Processing的部分。這篇將會是概觀介紹。
同步發表於我的部落格:http://blog.alantsai.net/2017/12/data-science-series-13-data-processing-workflow-introduction.html (部落格的格式會漂亮一些,ithome不支援html好不方便)
Data Processing Workflow其實非常廣的一個詞,所以這邊會定義一下這裡指的是什麼。
Data Processing Workflow圖
還記不記得之前的這張圖?這次有做了一些調整。
這邊變成了灰色表示已經講完了。Big Data在中間是因為整個的核心其實是Data。如果沒有Data就算有在好的“招式”也沒有用。
整個的Workflow從想找到某個問題的解決方案開始。這個非常重要。因為接下來的處理方式都是依照這個問題來延伸出來。
這個和開發軟體一樣,如果一開始的需求分析就錯了,那麼後面做的再好客戶一定不滿意,因為這個不是他想解決的問題。
題外話,還記得之前提到Data Scientist有提到會需要某個Domain Knowledge(領域知識) - 因為沒有這個領域知識根本問不出問題。
在這個部分,將會依照想要處理的問題去收集資料、收集完了之後需要對資料進行處理和分析,然後才會有所謂的clean data(乾淨)。
反過來說,如果一開始問題定義不明確,或者對於整個Domain不熟悉,那麼收集的資料一定會有偏頗,對有偏頗的資料進行處理和分析肯定就錯了。
這個階段會需要:
這個階段花的時間最多 - 有做過研究,大約80%的時間都是花在這個階段。
傳統的Data Analysis(資料分析)是不會有Machine Learning的階段,或者準確一點說,並不會像現在Machine Learning的定義方式來產生出模型。
個人覺得Machine Learning(以下簡稱ML)這個詞有點誤導傾向,因為聽到ML第一個想到的是 AI。好像是在講AI自動進化的感覺。但是,實際上不是,或者說只是AI進化的一小塊部分而已。
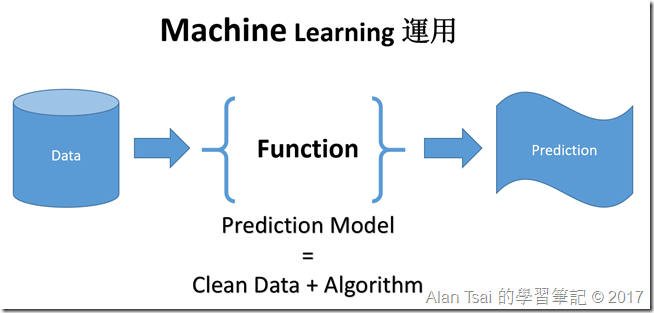
ML process
整個Machine Learning的目的是在建立一個Prediction Model。透過這個Prediction Model,只需要把資料丟進去,就會得到“準確”的預測結果。
而Prediction Model其實就是 Clean Data + Algorithm最後產生出來。
而Algorithm是什麼?其實就是一些Statistical Model(統計模型)定義出來。
所以ML和一般程式開發很不一樣,一般程式開發寫的是邏輯,但是ML其實不是寫邏輯,而是挑選最適合目前預測內容和資料的algorithm。所以他在調整的是兩個東西:
Training Data (也就是Clean Data)
Algorithm - 使用哪個演算法和演算法本身參數的調整
所以最後的Prediction Model找到的不是最終解法,而是找到Data之間的關聯性,因此Model不會一直有效,因為假設什麼原因導致那個關聯性斷了,Model就不準確了。
以上是一個非常快速的介紹ML,之後會到了ML階段會有更深入的一些介紹。
不管有沒有走ML,最後一定會有一些分析結果或者有走ML會有Prediction Model。
這些資訊如何容易的呈現給他人來看?如何把Model變成簡單方式就可以讓一般人操作?這個階段其實就是把整個結果很好的呈現出來。
這個Workflow裡面,越前面的階段越重要,換句話說,定義問題最重要。因為,每一個階段的動作會相依上一個階段的結果,所謂 失之毫釐,差以千里,因此很長會在 各個階段往回跳來跳去。
在接下來的內容,會需要有個前置條件,就是多多少少有碰過程式開發。
不需要很深入的了解,但是要有基本知識像是什麼是variable(參數)這種很簡單的概念即可。
因為,接下來的一些資料處理都會使用R語言,這邊不會一個一個語法介紹R。只會把整個的歷史和特色概念介紹一下,剩下都是邊操作邊說明,因此如果從來沒有碰過程式肯能會覺得不太懂(不過應該就算沒有碰過程式開發應該也會看的懂才對)
至於另外一個重要的概念:一些簡單的統計概念也會很有幫助,不過這個部分會有特定篇幅做一些簡單介紹,因為如果沒有這些背景在看一些Data Process的時候會看不太懂。
這篇對於整個Data運用的整個階段做了一個簡單和快速的介紹,為接下來介紹的內容先打下一些基礎。
下篇將會從最終要的部分開始,怎麼定義一個問題?什麼樣的定義才是好的定義。
工商服務
今年的團隊機制不知不覺就集合了10位隊(坑)友 - 大家幫忙多多關注別不小心我們就gg了 XD
** 一群技術愛好者與一名物理治療師的故事 提醒著我們 千萬不要放棄治療 **
沉浸於.Net世界的後端工程師,樂於分享,現任台中Study4成員之一。除了程式以外,就愛看小說。
歡迎有任何問題或者建議都可以告訴我,可以再以下找到我:
部落格:Alan Tsai的學習筆記
我的Linkedin
我的粉絲頁
我的github
我的Slideshare
我的Twitter