RDD(Resilient Distributed Datasets)為一個分散式的資料集,如圖1,由AMPLab實驗室所提出之概念,在Spark中其為一個核心資料單元,類似於一個分散式記憶體概念,它可以居住在記憶體或是硬碟中,並具有不可變性以及高容錯性,而其中RDD提供了多樣的API來操作資料,提供了讓現今的叢集設計架構尚未支援的新應用,像是它可依照使用者需求產生一新的RDD(transformation),也可以取得運算結果(action),如圖2。此外,RDD讓使用者可以控制資料的持有化(persistence)以及切割(partitioning),故使用者可以決定資料應該儲存在緩存記憶體中還是要分配到其他節點上處理。
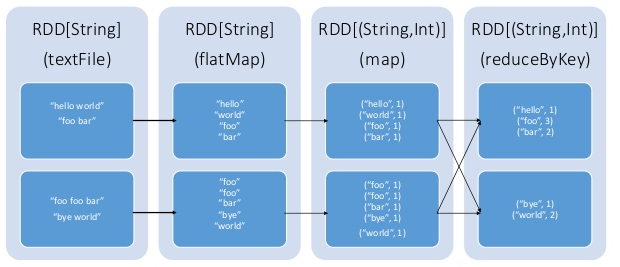
圖 1 Spark RDD
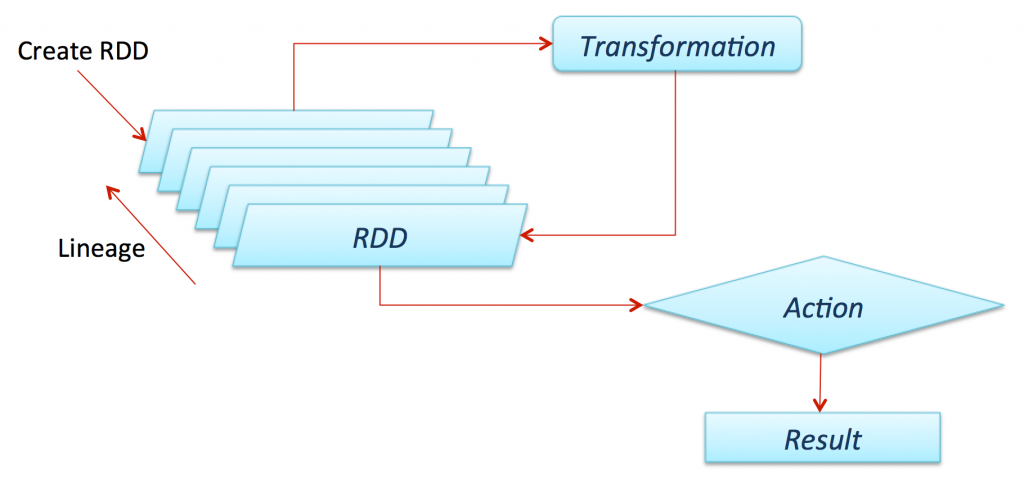
圖 2 RDD執行流程圖
RDD除了能夠與其他系統相容之外,還能提供一容錯處理的特性,RDD利用Lineage (血統)來達到容錯的特性,它會在資料運算的過程中記錄RDD與RDD之間的父子轉換過程,若某個RDD遺失時,可藉由轉換(transformation)操作方式從父RDD中來重新計算來取得子RDD的資訊,因此當某個節點機器故障時,發生RDD損毀的情形時,可藉由Lineage (血統)取得資遺失資料的內容,因此即可避免因特定節點故障導致整個系統無法運作之問題。
以下將會介紹RDD針對四種資料運算之類型:
第一種類型迭代運算:可以針對不同領域之特定系統進行應用,例如應用於影像處理、數值優化以及機器學習中的演算法。RDD能夠極佳地實現這些模型,包含KMeans、FP-Growth和LinearRegression等機器學習演算法模型。
第二種類型關聯式查詢:對於結構化之資料來說RDD提供一結構化查詢語言(Structured Query Language),可以針對關聯式資料庫來進行查詢,對於MapReduce而言執行SQL查詢是一個非常重要的需求,其中包含互動式的查詢和數小時的批次處理作業。對MapReduce而言,相較於平行資料庫進行互動式查詢,有其內在的缺點。但利用RDD可以透過實現許多通用的資料庫引擎特性,進一步獲得非常好的效能。
第三種類型MapReduce批次處理:RDD中提供的介面為MapReduce的超集合,其將MapReduce模型進行介面化,可利用介面的方式來達到MapReduce模型的功能,傳統的MapReduce模型運作流程需先執行Map function方能再執行Reduce function,但RDD的操作方式可依照使用者的需求任一搭配介面執行的順序,因此RDD可以有效的執行基於MapReduce實現的應用程式。
第四種串流式處理:目前的串流式系統的容錯處理其實相當有限,對於串流式系統來說若要針對資料進行容錯處理需要消耗非常長的容錯時間。尤其是在以連續計算為基礎的系統中,該串流式系統會處理每一筆資料,若要達到容錯性的效果,它們需要為每一筆資料複製成兩份,或是將先前的資料進行非常耗時的資料重放。RDD中有提供一種模型離散資料流程(D-Stream),其代表一個資料流程,DStream是由一組時間序列的連續RDD所組成,它提供一高階層的程式介面供使用者使用,具有強一致性以及高效的錯誤恢復,D-Stream支援了一個新的恢復機制,相較於傳統串流式系統的容錯機制,其可達到有效的備份機制解決方案。
D-Stream串流式計算將一系列短小的批次操作進行處理,而它會將有狀態的RDD操作紀錄下來,透過每一個RDD中的相依資訊將其從錯誤中恢復。
參考:
https://dzone.com/refcardz/apache-spark


